Haselbeck Florian, John Maura, Zhang Yuqi, Pirnay Jonathan, Fuenzalida-Werner Juan Pablo, Costa Rubén D, Grimm Dominik G
Technical University of Munich, Campus Straubing for Biotechnology and Sustainability, Bioinformatics, 94315 Straubing, Germany.
Weihenstephan-Triesdorf University of Applied Sciences, Bioinformatics, 94315 Straubing, Germany.
NAR Genom Bioinform. 2023 Oct 11;5(4):lqad087. doi: 10.1093/nargab/lqad087. eCollection 2023 Dec.
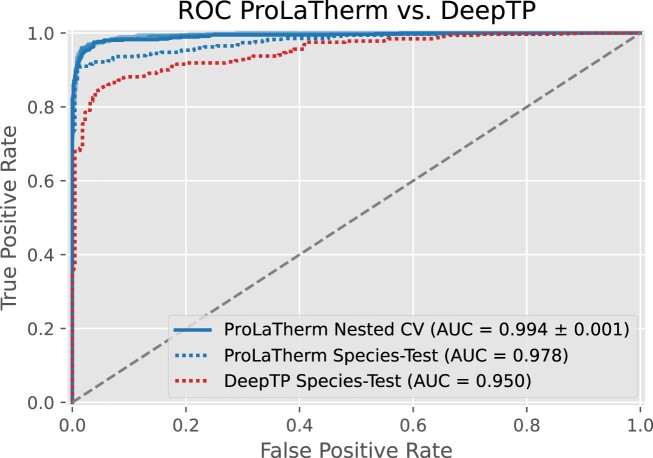
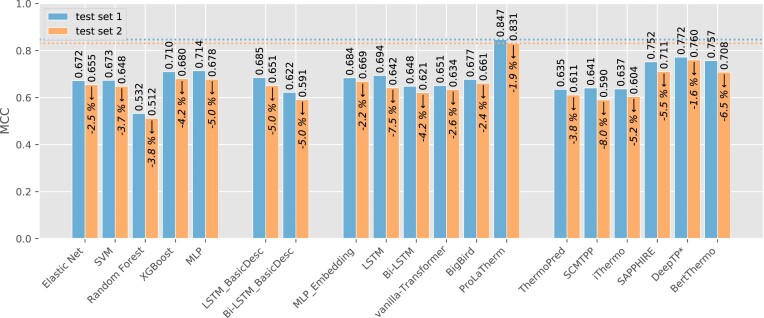
Protein thermostability is important in many areas of biotechnology, including enzyme engineering and protein-hybrid optoelectronics. Ever-growing protein databases and information on stability at different temperatures allow the training of machine learning models to predict whether proteins are thermophilic. predictions could reduce costs and accelerate the development process by guiding researchers to more promising candidates. Existing models for predicting protein thermophilicity rely mainly on features derived from physicochemical properties. Recently, modern protein language models that directly use sequence information have demonstrated superior performance in several tasks. In this study, we evaluate the usefulness of protein language model embeddings for thermophilicity prediction with ProLaTherm, a tein nguage model-based ophilicity predictor. ProLaTherm significantly outperforms all feature-, sequence- and literature-based comparison partners on multiple evaluation metrics. In terms of the Matthew's correlation coefficient, ProLaTherm outperforms the second-best competitor by 18.1% in a nested cross-validation setup. Using proteins from species not overlapping with species from the training data, ProLaTherm outperforms all competitors by at least 9.7%. On these data, it misclassified only one nonthermophilic protein as thermophilic. Furthermore, it correctly identified 97.4% of all thermophilic proteins in our test set with an optimal growth temperature above 70°C.
蛋白质热稳定性在生物技术的许多领域都很重要,包括酶工程和蛋白质混合光电子学。不断增长的蛋白质数据库以及不同温度下的稳定性信息使得机器学习模型得以训练,以预测蛋白质是否为嗜热蛋白。这些预测可以通过引导研究人员找到更有前景的候选蛋白来降低成本并加速开发过程。现有的预测蛋白质嗜热性的模型主要依赖于从物理化学性质衍生的特征。最近,直接使用序列信息的现代蛋白质语言模型在多项任务中展现出卓越性能。在本研究中,我们使用基于蛋白质语言模型的嗜热性预测器ProLaTherm评估蛋白质语言模型嵌入用于嗜热性预测的有效性。在多个评估指标上,ProLaTherm显著优于所有基于特征、序列和文献的比较对象。在马修斯相关系数方面,在嵌套交叉验证设置中,ProLaTherm比第二优的竞争对手高出18.1%。使用与训练数据中的物种不重叠的物种的蛋白质,ProLaTherm比所有竞争对手至少高出9.7%。在这些数据上,它仅将一个非嗜热蛋白误分类为嗜热蛋白。此外,它正确识别了我们测试集中所有最佳生长温度高于70°C的嗜热蛋白中的97.4%。