Engineering Research Center of Intelligent Control for Underground Space, Ministry of Education, China University of Mining and Technology, Xuzhou 221116 China.
The School of Information and Control Engineering, China University of Mining and Technology, Xuzhou 221116, China.
Sensors (Basel). 2020 Jun 30;20(13):3664. doi: 10.3390/s20133664.
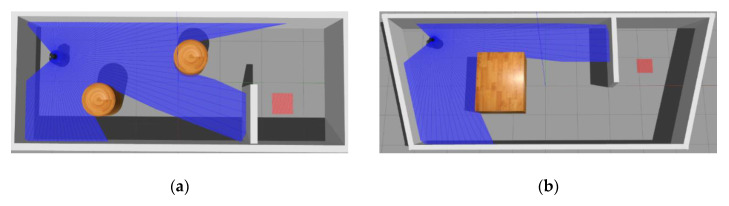
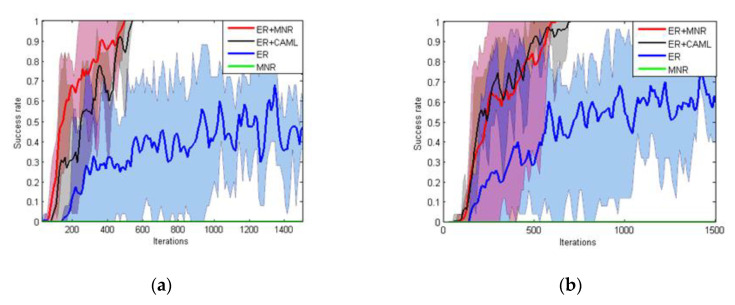
Deep reinforcement learning (DRL) has been successfully applied in mapless navigation. An important issue in DRL is to design a reward function for evaluating actions of agents. However, designing a robust and suitable reward function greatly depends on the designer's experience and intuition. To address this concern, we consider employing reward shaping from trajectories on similar navigation tasks without human supervision, and propose a general reward function based on matching network (MN). The MN-based reward function is able to gain the experience by pre-training through trajectories on different navigation tasks and accelerate the training speed of DRL in new tasks. The proposed reward function keeps the optimal strategy of DRL unchanged. The simulation results on two static maps show that the DRL converge with less iterations via the learned reward function than the state-of-the-art mapless navigation methods. The proposed method performs well in dynamic maps with partially moving obstacles. Even when test maps are different from training maps, the proposed strategy is able to complete the navigation tasks without additional training.
深度强化学习 (DRL) 在无地图导航中得到了成功应用。在 DRL 中,一个重要的问题是设计一个用于评估智能体动作的奖励函数。然而,设计一个稳健且合适的奖励函数在很大程度上取决于设计者的经验和直觉。为了解决这个问题,我们考虑在没有人工监督的情况下,从类似导航任务的轨迹中采用奖励塑造技术,并提出了一种基于匹配网络 (MN) 的通用奖励函数。基于 MN 的奖励函数能够通过在不同导航任务上的轨迹进行预训练来获取经验,并加速 DRL 在新任务中的训练速度。所提出的奖励函数保持 DRL 的最优策略不变。在两个静态地图上的仿真结果表明,通过学习奖励函数,DRL 能够在更少的迭代次数内收敛,优于最新的无地图导航方法。所提出的方法在部分移动障碍物的动态地图中表现良好。即使测试地图与训练地图不同,所提出的策略也能够在无需额外训练的情况下完成导航任务。