Department of Biomedical Engineering, School of Life Science and Technology, Ministry of Education Key Laboratory of Molecular Biophysics, Huazhong University of Science and Technology, No 1037, Luoyu Road, Wuhan 430074, China.
Sensors (Basel). 2020 Jul 3;20(13):3724. doi: 10.3390/s20133724.
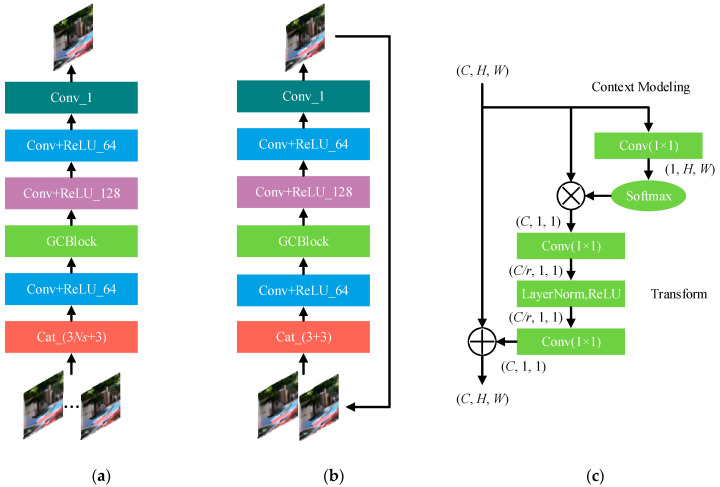
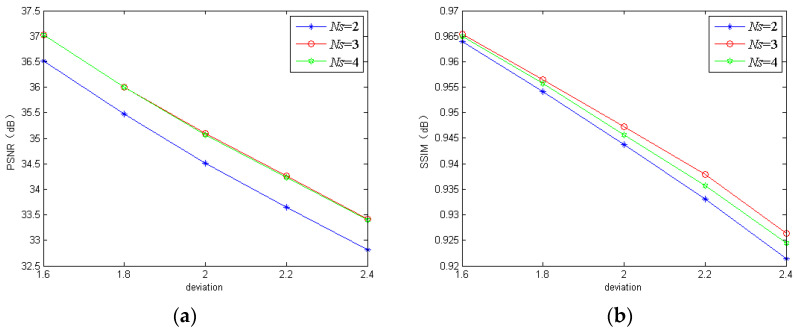
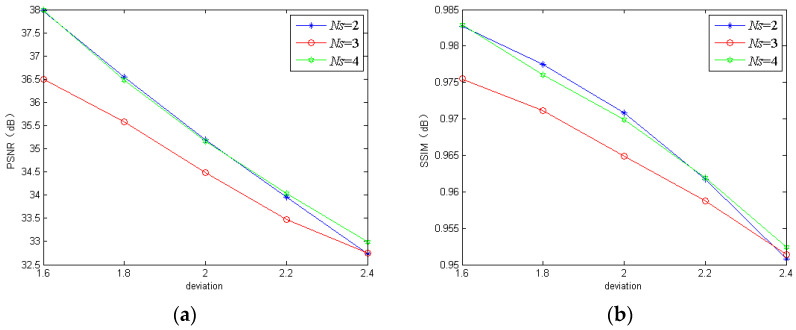
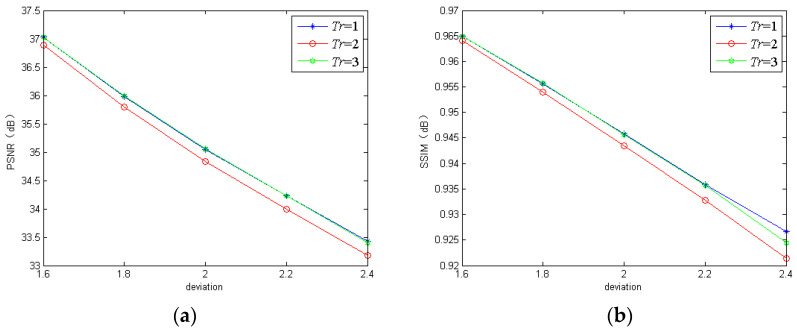
Image deblurring has been a challenging ill-posed problem in computer vision. Gaussian blur is a common model for image and signal degradation. The deep learning-based deblurring methods have attracted much attention due to their advantages over the traditional methods relying on hand-designed features. However, the existing deep learning-based deblurring techniques still cannot perform well in restoring the fine details and reconstructing the sharp edges. To address this issue, we have designed an effective end-to-end deep learning-based non-blind image deblurring algorithm. In the proposed method, a multi-stream bottom-top-bottom attention network (MBANet) with the encoder-to-decoder structure is designed to integrate low-level cues and high-level semantic information, which can facilitate extracting image features more effectively and improve the computational efficiency of the network. Moreover, the MBANet adopts a coarse-to-fine multi-scale strategy to process the input images to improve image deblurring performance. Furthermore, the global information-based fusion and reconstruction network is proposed to fuse multi-scale output maps to improve the global spatial information and recurrently refine the output deblurred image. The experiments were done on the public GoPro dataset and the realistic and dynamic scenes (REDS) dataset to evaluate the effectiveness and robustness of the proposed method. The experimental results show that the proposed method generally outperforms some traditional deburring methods and deep learning-based state-of-the-art deblurring methods such as scale-recurrent network (SRN) and denoising prior driven deep neural network (DPDNN) in terms of such quantitative indexes as peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) and human vision.
图像去模糊一直是计算机视觉中一个具有挑战性的不适定问题。高斯模糊是图像和信号退化的常见模型。基于深度学习的去模糊方法由于其相对于依赖于手工设计特征的传统方法的优势而受到了广泛关注。然而,现有的基于深度学习的去模糊技术仍然不能很好地恢复细节和重建边缘。为了解决这个问题,我们设计了一种有效的端到端基于深度学习的非盲图像去模糊算法。在提出的方法中,设计了一个具有编解码器结构的多流自顶向下自底向上的注意力网络(MBANet),以集成底层线索和高层语义信息,这可以更有效地提取图像特征,并提高网络的计算效率。此外,MBANet 采用了一种由粗到精的多尺度策略来处理输入图像,以提高图像去模糊性能。此外,提出了基于全局信息的融合和重建网络,以融合多尺度输出图,提高全局空间信息,并递归地细化输出去模糊图像。在公共 GoPro 数据集和真实动态场景(REDS)数据集上进行了实验,以评估所提出方法的有效性和鲁棒性。实验结果表明,所提出的方法在 PSNR 和 SSIM 等定量指标以及人类视觉方面,通常优于一些传统的去模糊方法和基于深度学习的最新去模糊方法,如尺度递归网络(SRN)和去噪先验驱动的深度神经网络(DPDNN)。