Institute of Medical Information/Library, Chinese Academy of Medical Sciences and Peking Union Medical College, Beijing, China.
Office of Cancer Screening, National Cancer Center/National Clinical Research Center for Cancer/Cancer Hospital, Chinese Academy of Medical Sciences and Peking Union Medical College, Beijing, 100021, China.
BMC Med Inform Decis Mak. 2020 Jul 9;20(Suppl 3):122. doi: 10.1186/s12911-020-1116-1.
The increasing global cancer incidence corresponds to serious health impact in countries worldwide. Knowledge-powered health system in different languages would enhance clinicians' healthcare practice, patients' health management and public health literacy. High-quality corpus containing cancer information is the necessary foundation of cancer education. Massive non-structural information resources exist in clinical narratives, electronic health records (EHR) etc. They can only be used for training AI models after being transformed into structured corpus. However, the scarcity of multilingual cancer corpus limits the intelligent processing, such as machine translation in medical scenarios. Thus, we created the cancer specific cross-lingual corpus and open it to the public for academic use.
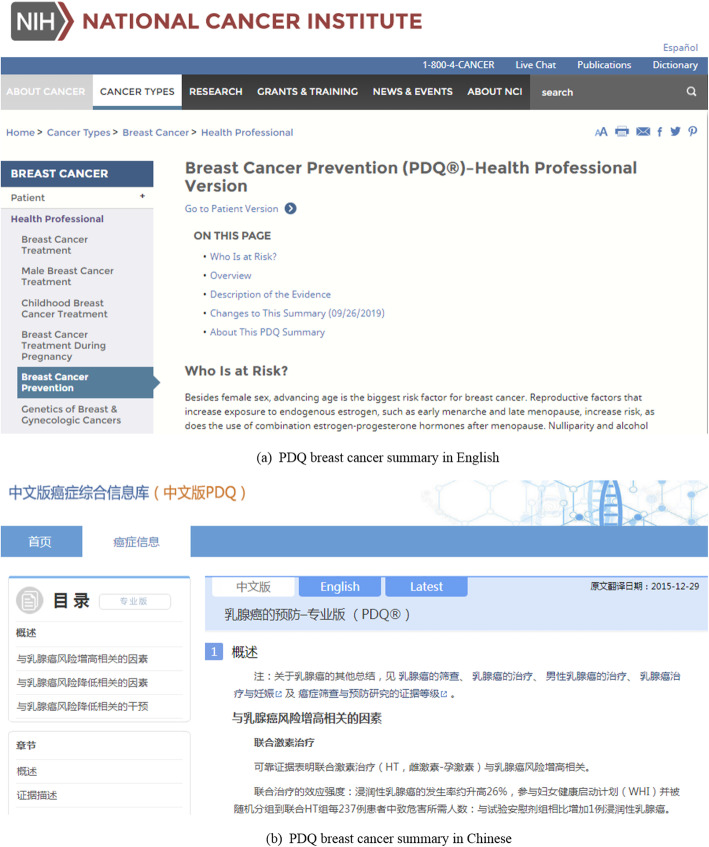
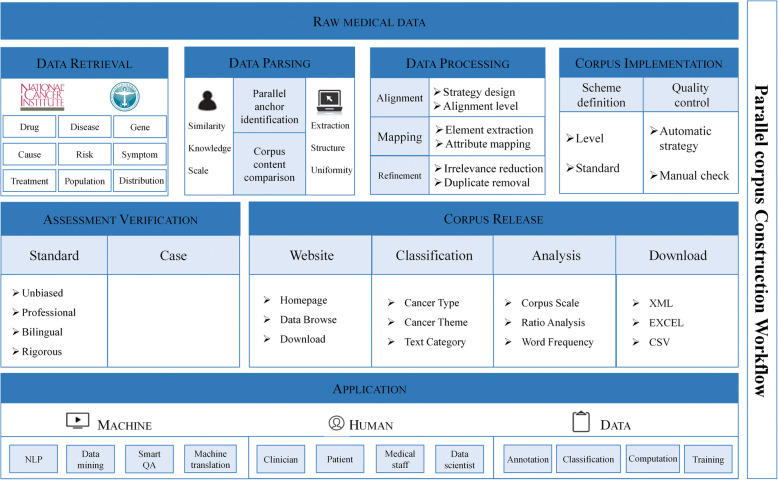
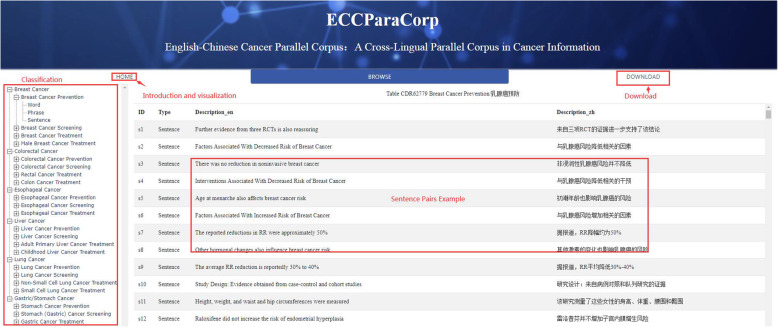
Aiming to build an English-Chinese cancer parallel corpus, we developed a workflow of seven steps including data retrieval, data parsing, data processing, corpus implementation, assessment verification, corpus release, and application. We applied the workflow to a cross-lingual, comprehensive and authoritative cancer information resource, PDQ (Physician Data Query). We constructed, validated and released the parallel corpus named as ECCParaCorp, made it openly accessible online.
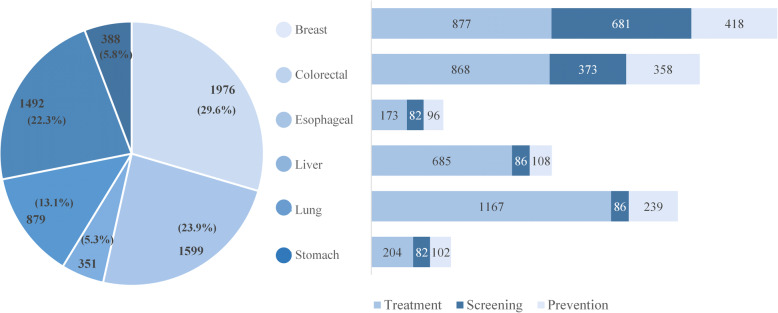
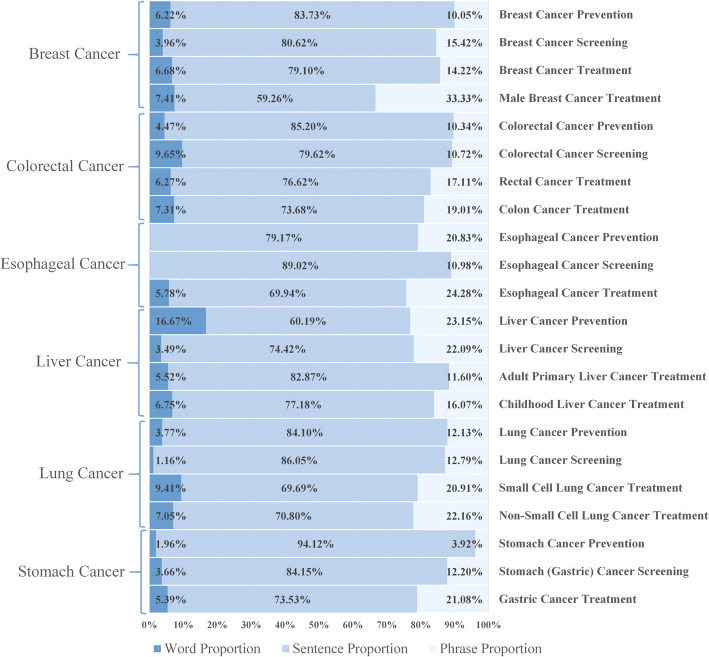
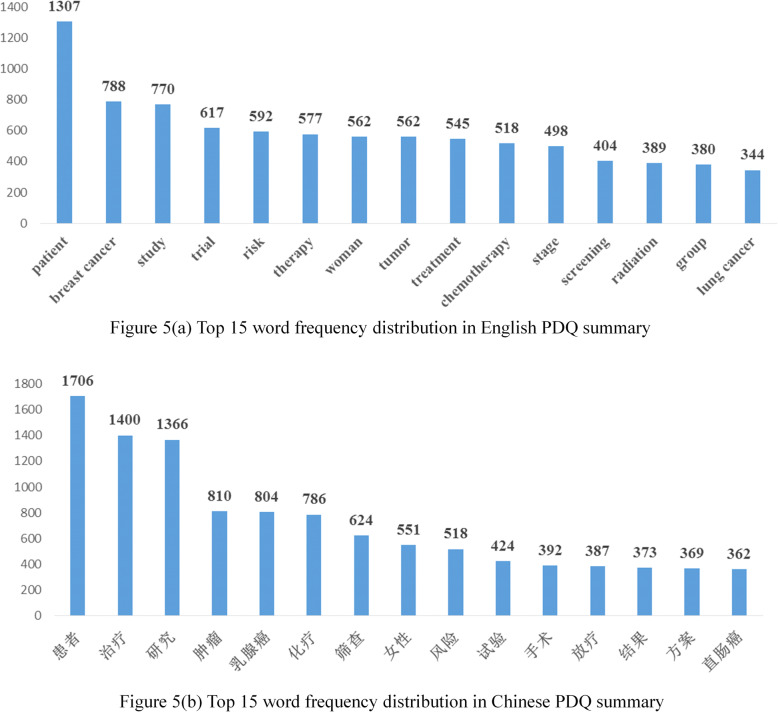
The proposed English-Chinese Cancer Parallel Corpus (ECCParaCorp) consists of 6685 aligned text pairs in Xml, Excel, Csv format, containing 5190 sentence pairs, 1083 phrase pairs and 412 word pairs, which involved information of 6 cancers including breast cancer, liver cancer, lung cancer, esophageal cancer, colorectal cancer, and stomach cancer, and 3 cancer themes containing cancer prevention, screening, and treatment. All data in the parallel corpus are online, available for users to browse and download ( http://www.phoc.org.cn/ECCParaCorp/ ).
ECCParaCorp is a parallel corpus focused on cancer in a cross-lingual form, which is openly accessible. It would make up the imbalance of scarce multilingual corpus resources, bridge the gap between human readable information and machine understanding data resources, and would contribute to intelligent technology application as a preparatory data foundation e.g. cancer-related machine translation, cancer system development towards medical education, and disease-oriented knowledge extraction.
全球癌症发病率的不断增加对应着全球各国严重的健康影响。不同语言的知识驱动型卫生系统将增强临床医生的医疗实践、患者的健康管理和公众的健康素养。高质量的包含癌症信息的语料库是癌症教育的必要基础。大量非结构化信息资源存在于临床叙述、电子健康记录 (EHR) 等中。在将其转换为结构化语料库之前,它们只能用于训练 AI 模型。然而,多语言癌症语料库的稀缺限制了智能处理,例如医学场景中的机器翻译。因此,我们创建了特定于癌症的跨语言语料库并向公众开放供学术使用。
为了构建英中癌症平行语料库,我们开发了一个包含七个步骤的工作流程,包括数据检索、数据解析、数据处理、语料库实现、评估验证、语料库发布和应用。我们将该工作流程应用于跨语言、全面和权威的癌症信息资源 PDQ(医生数据查询)。我们构建、验证和发布了名为 ECCParaCorp 的平行语料库,并在网上公开提供。
提出的英中癌症平行语料库 (ECCParaCorp) 由 6685 对以 Xml、Excel、Csv 格式对齐的文本对组成,包含 5190 个句子对、1083 个短语对和 412 个单词对,涉及乳腺癌、肝癌、肺癌、食管癌、结直肠癌和胃癌等 6 种癌症的信息,以及癌症预防、筛查和治疗等 3 个癌症主题。平行语料库中的所有数据都在线,供用户浏览和下载(http://www.phoc.org.cn/ECCParaCorp/)。
ECCParaCorp 是一个专注于跨语言癌症的平行语料库,可公开访问。它将弥补多语言语料库资源稀缺的不平衡,弥合人类可读信息与机器理解数据资源之间的差距,并为智能技术应用做出贡献,例如癌症相关的机器翻译、面向医学教育的癌症系统开发和面向疾病的知识提取。