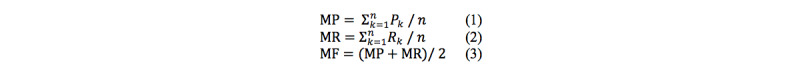Pan Xiaoyi, Chen Boyu, Weng Heng, Gong Yongyi, Qu Yingying
School of Information Science and Technology, Guangdong University of Foreign Studies, Guangzhou, China.
Department of Big Data Research of Medicine, The Second Affiliated Hospital of Guangzhou University of Chinese Medicine, Guangzhou, China.
JMIR Med Inform. 2020 Jul 27;8(7):e17652. doi: 10.2196/17652.
Temporal information frequently exists in the representation of the disease progress, prescription, medication, surgery progress, or discharge summary in narrative clinical text. The accurate extraction and normalization of temporal expressions can positively boost the analysis and understanding of narrative clinical texts to promote clinical research and practice.
The goal of the study was to propose a novel approach for extracting and normalizing temporal expressions from Chinese narrative clinical text.
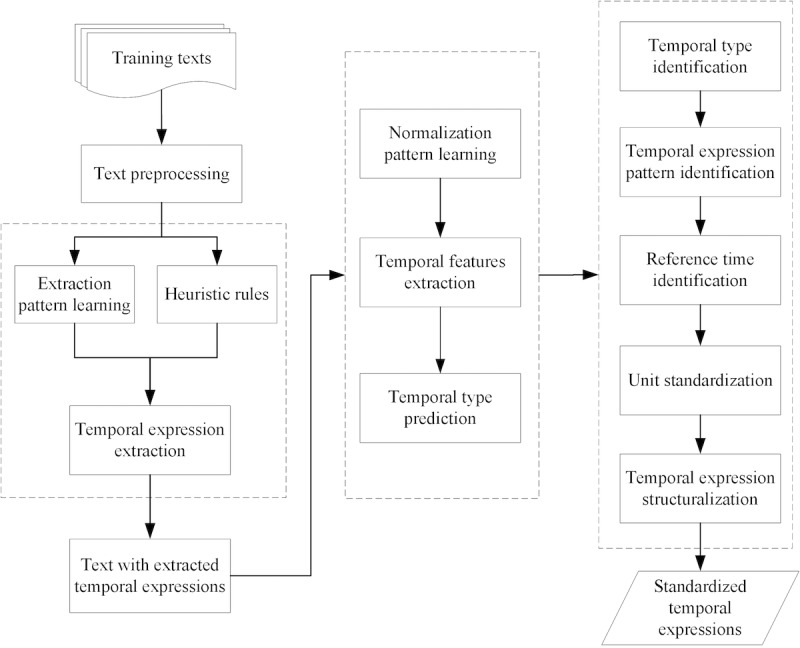
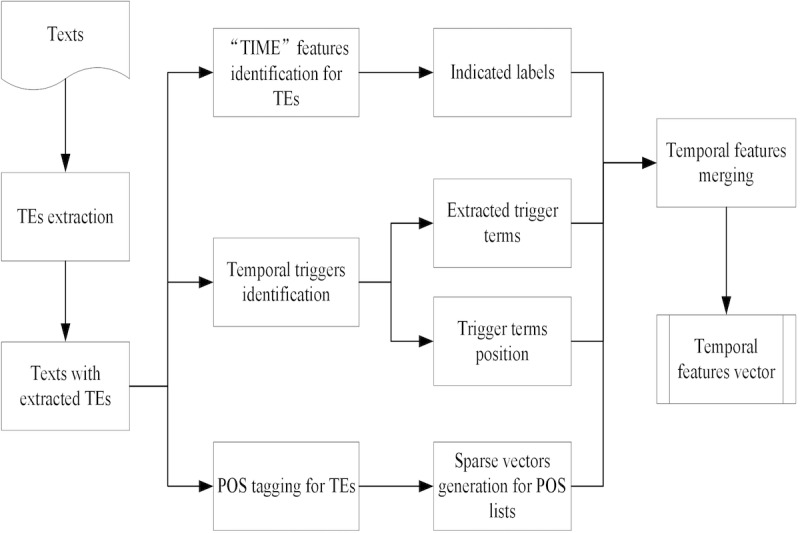
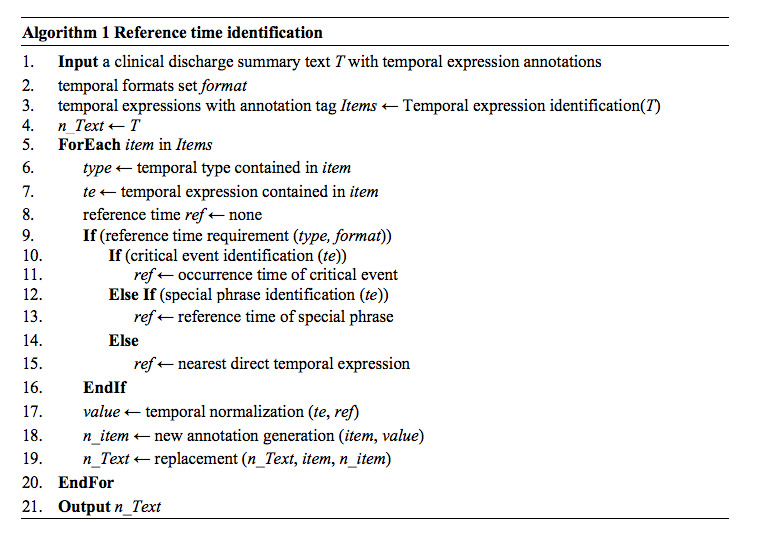
TNorm, a rule-based and pattern learning-based approach, has been developed for automatic temporal expression extraction and normalization from unstructured Chinese clinical text data. TNorm consists of three stages: extraction, classification, and normalization. It applies a set of heuristic rules and automatically generated patterns for temporal expression identification and extraction of clinical texts. Then, it collects the features of extracted temporal expressions for temporal type prediction and classification by using machine learning algorithms. Finally, the features are combined with the rule-based and a pattern learning-based approach to normalize the extracted temporal expressions.
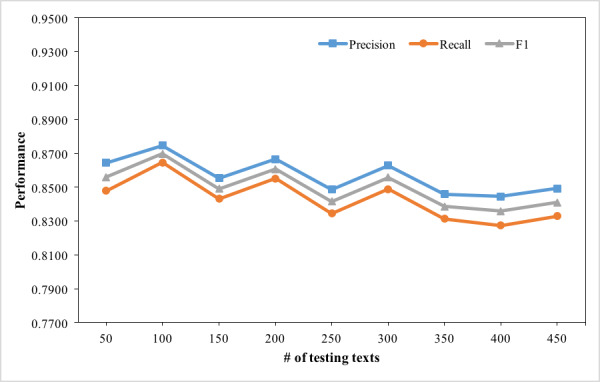
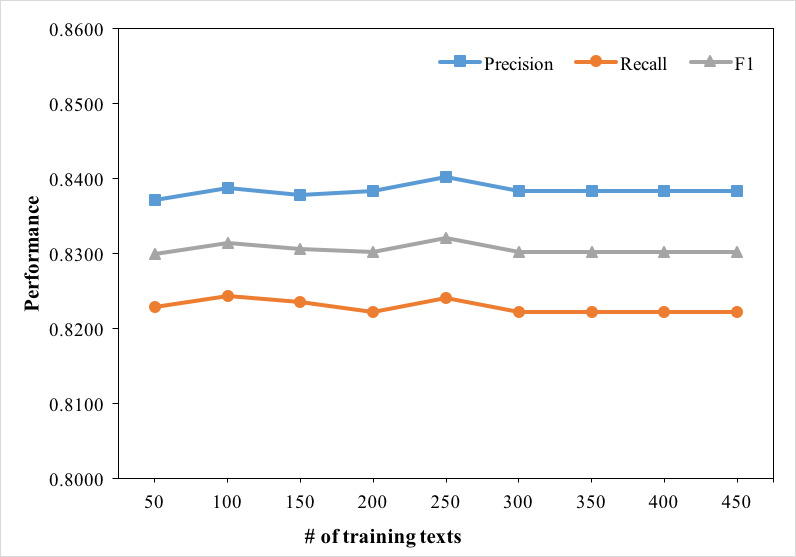
The evaluation dataset is a set of narrative clinical texts in Chinese containing 1459 discharge summaries of a domestic Grade A Class 3 hospital. The results show that TNorm, combined with temporal expressions extraction and temporal types prediction, achieves a precision of 0.8491, a recall of 0.8328, and a F1 score of 0.8409 in temporal expressions normalization.
This study illustrates an automatic approach, TNorm, that extracts and normalizes temporal expression from Chinese narrative clinical texts. TNorm was evaluated on the basis of discharge summary data, and results demonstrate its effectiveness on temporal expression normalization.
时间信息经常存在于叙述性临床文本中的疾病进展、处方、用药、手术过程或出院小结的表述中。时间表达式的准确提取和规范化能够积极推动对叙述性临床文本的分析和理解,以促进临床研究与实践。
本研究的目标是提出一种从中文叙述性临床文本中提取和规范化时间表达式的新方法。
已开发出TNorm,这是一种基于规则和模式学习的方法,用于从非结构化中文临床文本数据中自动提取和规范化时间表达式。TNorm包括三个阶段:提取、分类和规范化。它应用一组启发式规则和自动生成的模式来识别和提取临床文本中的时间表达式。然后,它通过使用机器学习算法收集提取的时间表达式的特征,用于时间类型预测和分类。最后,将这些特征与基于规则和基于模式学习的方法相结合,对提取的时间表达式进行规范化。
评估数据集是一组包含国内一家三甲医院1459份出院小结的中文叙述性临床文本。结果表明,TNorm结合时间表达式提取和时间类型预测,在时间表达式规范化方面的精确率为0.8491,召回率为0.8328,F1分数为0.8—409—。
本研究阐述了一种自动方法TNorm—它能从中文叙述性临床文本中提取和规范化时间表达式—TNorm基于出院小结数据进行了评估—结果证明了其在时间表达式规范化方面的有效性。