CNRS UMR5157, Télécom SudParis, Institut Polytechnique de Paris, Évry, France.
PLoS One. 2020 Aug 27;15(8):e0237861. doi: 10.1371/journal.pone.0237861. eCollection 2020.
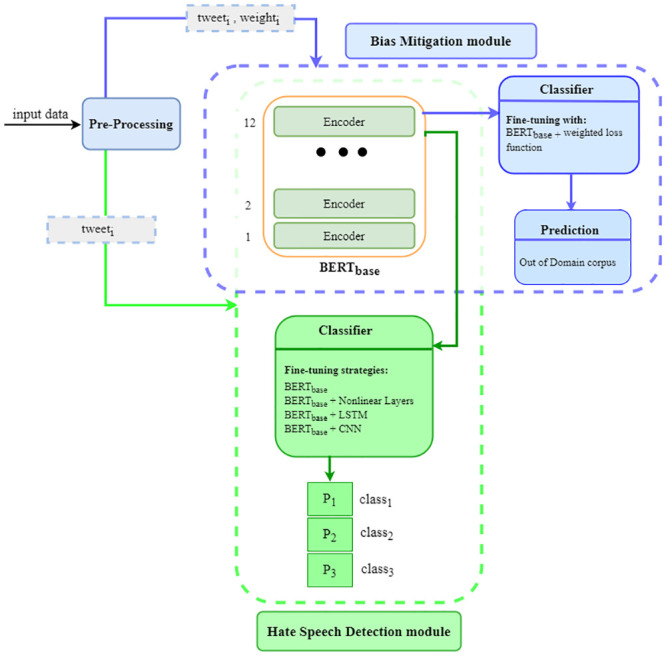
Disparate biases associated with datasets and trained classifiers in hateful and abusive content identification tasks have raised many concerns recently. Although the problem of biased datasets on abusive language detection has been addressed more frequently, biases arising from trained classifiers have not yet been a matter of concern. In this paper, we first introduce a transfer learning approach for hate speech detection based on an existing pre-trained language model called BERT (Bidirectional Encoder Representations from Transformers) and evaluate the proposed model on two publicly available datasets that have been annotated for racism, sexism, hate or offensive content on Twitter. Next, we introduce a bias alleviation mechanism to mitigate the effect of bias in training set during the fine-tuning of our pre-trained BERT-based model for hate speech detection. Toward that end, we use an existing regularization method to reweight input samples, thereby decreasing the effects of high correlated training set' s n-grams with class labels, and then fine-tune our pre-trained BERT-based model with the new re-weighted samples. To evaluate our bias alleviation mechanism, we employed a cross-domain approach in which we use the trained classifiers on the aforementioned datasets to predict the labels of two new datasets from Twitter, AAE-aligned and White-aligned groups, which indicate tweets written in African-American English (AAE) and Standard American English (SAE), respectively. The results show the existence of systematic racial bias in trained classifiers, as they tend to assign tweets written in AAE from AAE-aligned group to negative classes such as racism, sexism, hate, and offensive more often than tweets written in SAE from White-aligned group. However, the racial bias in our classifiers reduces significantly after our bias alleviation mechanism is incorporated. This work could institute the first step towards debiasing hate speech and abusive language detection systems.
最近,与数据集和训练分类器相关的差异偏见在仇恨和辱骂内容识别任务中引起了很多关注。虽然已经更频繁地解决了关于辱骂性语言检测的有偏差数据集的问题,但源于训练分类器的偏差尚未成为关注的问题。在本文中,我们首先介绍了一种基于现有的预训练语言模型 BERT(来自 Transformer 的双向编码器表示)的仇恨言论检测的迁移学习方法,并在两个已为 Twitter 上的种族主义、性别歧视、仇恨或冒犯性内容进行标注的公开可用数据集上评估了所提出的模型。接下来,我们引入了一种偏差缓解机制,以减轻在对我们基于预训练 BERT 的仇恨言论检测模型进行微调过程中训练集的偏差影响。为此,我们使用现有的正则化方法对输入样本进行重新加权,从而减少了与类别标签相关的高相关训练集 n-gram 的影响,然后使用新的重新加权样本对我们的基于预训练 BERT 的模型进行微调。为了评估我们的偏差缓解机制,我们采用了一种跨领域的方法,即在上述数据集上使用训练好的分类器来预测来自 Twitter 的两个新数据集的标签,分别为 AAE-aligned 和 White-aligned 组,它们分别表示以非裔美国人英语(AAE)和标准美国英语(SAE)编写的推文。结果表明,训练好的分类器中存在系统性的种族偏见,因为它们倾向于将 AAE-aligned 组中以 AAE 编写的推文更频繁地分配到负面类别,如种族主义、性别歧视、仇恨和冒犯,而不是将 White-aligned 组中以 SAE 编写的推文分配到这些类别。然而,在我们的偏差缓解机制被纳入之后,分类器中的种族偏见显著减少。这项工作可能是朝着消除仇恨言论和辱骂性语言检测系统的偏见迈出的第一步。