Institute of Systems Genetics, New York University Grossman School of Medicine, New York, NY, 10016, USA.
Department of Medicine, New York University Grossman School of Medicine, New York, NY, 10016, USA.
BMC Bioinformatics. 2020 Sep 29;21(1):428. doi: 10.1186/s12859-020-03774-1.
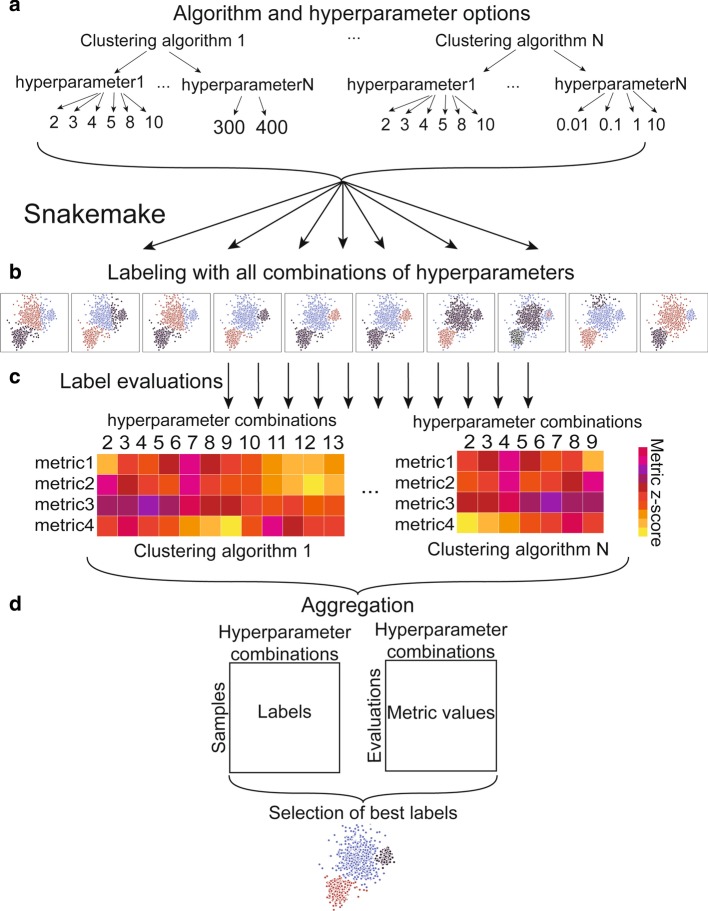
Unsupervised clustering is a common and exceptionally useful tool for large biological datasets. However, clustering requires upfront algorithm and hyperparameter selection, which can introduce bias into the final clustering labels. It is therefore advisable to obtain a range of clustering results from multiple models and hyperparameters, which can be cumbersome and slow.
We present hypercluster, a python package and SnakeMake pipeline for flexible and parallelized clustering evaluation and selection. Users can efficiently evaluate a huge range of clustering results from multiple models and hyperparameters to identify an optimal model.
Hypercluster improves ease of use, robustness and reproducibility for unsupervised clustering application for high throughput biology. Hypercluster is available on pip and bioconda; installation, documentation and example workflows can be found at: https://github.com/ruggleslab/hypercluster .
无监督聚类是处理大型生物学数据集的常用且非常有用的工具。然而,聚类需要事先选择算法和超参数,这可能会给最终的聚类标签带来偏差。因此,从多个模型和超参数中获得一系列聚类结果是明智的,但是这可能会很繁琐和缓慢。
我们提出了 hypercluster,这是一个 Python 包和 SnakeMake 管道,用于灵活且并行的聚类评估和选择。用户可以从多个模型和超参数中高效地评估大量的聚类结果,以确定最佳模型。
hypercluster 提高了高通量生物学中无监督聚类应用的易用性、鲁棒性和可重复性。hypercluster 可通过 pip 和 bioconda 获得;安装、文档和示例工作流程可在以下网址找到:https://github.com/ruggleslab/hypercluster 。