Ho Thanh Lam Luu, Le Ngoc Hoang, Van Tuan Le, Tran Ban Ho, Nguyen Khanh Hung Truong, Nguyen Ngan Thi Kim, Huu Dang Luong, Le Nguyen Quoc Khanh
International Master/PhD Program in Medicine, College of Medicine, Taipei Medical University, Taipei City 110, Taiwan.
Children's Hospital 2, Ho Chi Minh City 700000, Vietnam.
Biology (Basel). 2020 Oct 6;9(10):325. doi: 10.3390/biology9100325.
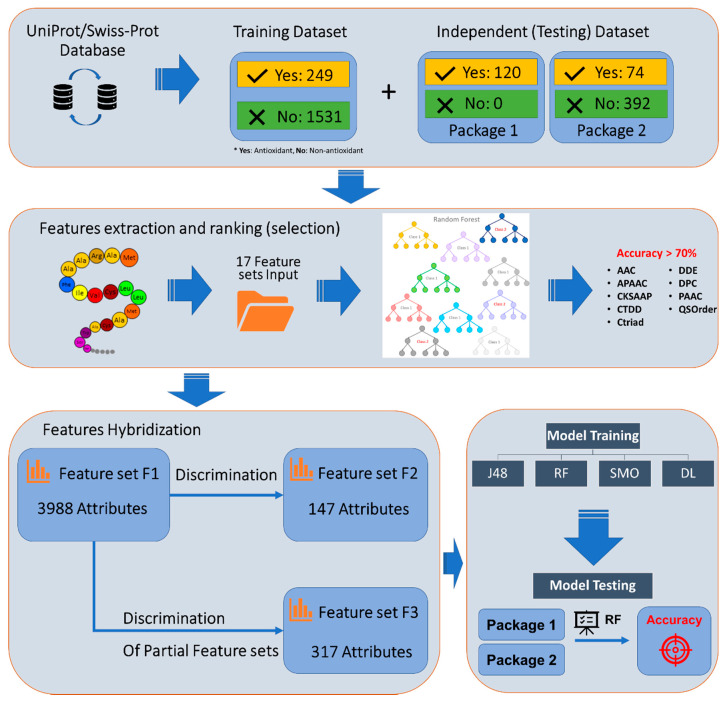
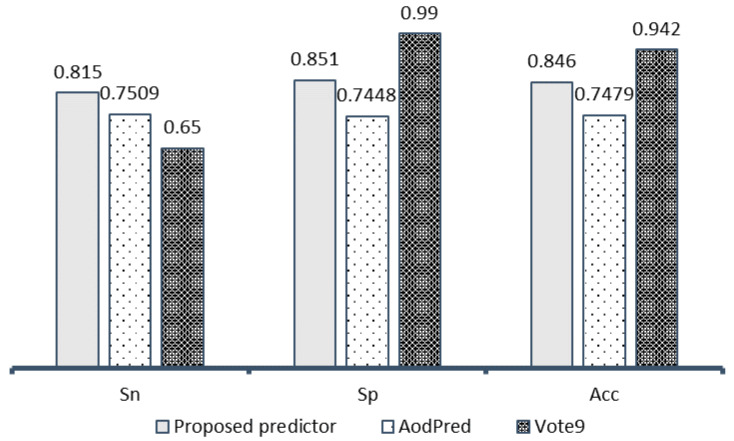
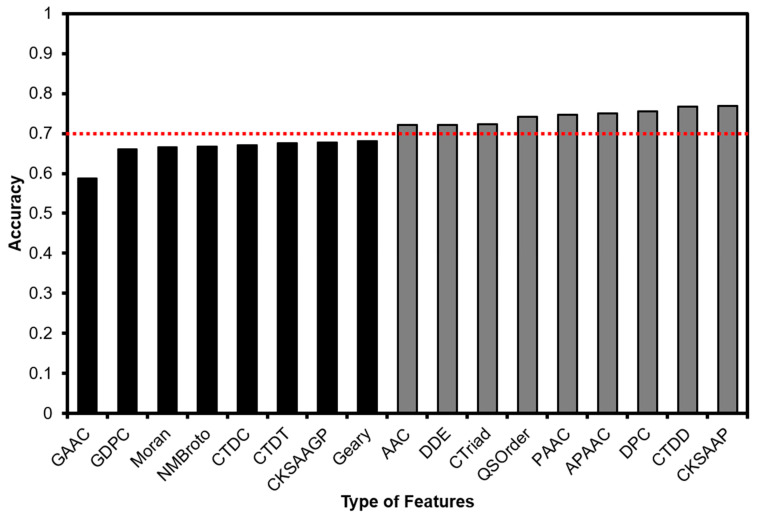
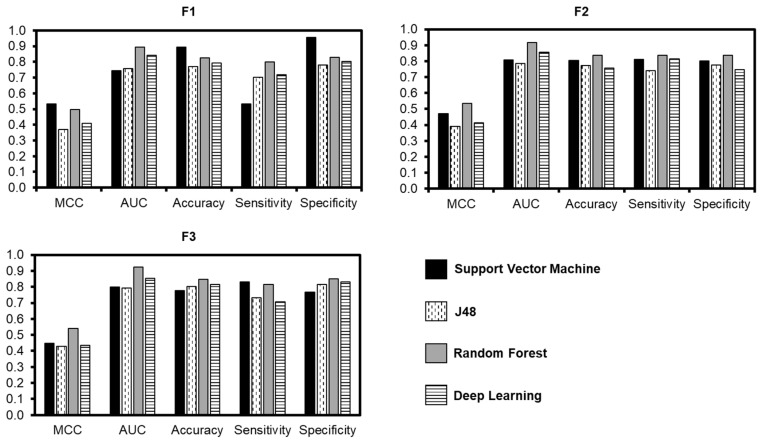
Antioxidant proteins are involved importantly in many aspects of cellular life activities. They protect the cell and DNA from oxidative substances (such as peroxide, nitric oxide, oxygen-free radicals, etc.) which are known as reactive oxygen species (ROS). Free radical generation and antioxidant defenses are opposing factors in the human body and the balance between them is necessary to maintain a healthy body. An unhealthy routine or the degeneration of age can break the balance, leading to more ROS than antioxidants, causing damage to health. In general, the antioxidant mechanism is the combination of antioxidant molecules and ROS in a one-electron reaction. Creating computational models to promptly identify antioxidant candidates is essential in supporting antioxidant detection experiments in the laboratory. In this study, we proposed a machine learning-based model for this prediction purpose from a benchmark set of sequencing data. The experiments were conducted by using 10-fold cross-validation on the training process and validated by three different independent datasets. Different machine learning and deep learning algorithms have been evaluated on an optimal set of sequence features. Among them, Random Forest has been identified as the best model to identify antioxidant proteins with the highest performance. Our optimal model achieved high accuracy of 84.6%, as well as a balance in sensitivity (81.5%) and specificity (85.1%) for antioxidant protein identification on the training dataset. The performance results from different independent datasets also showed the significance in our model compared to previously published works on antioxidant protein identification.
抗氧化蛋白在细胞生命活动的许多方面都起着重要作用。它们保护细胞和DNA免受氧化物质(如过氧化物、一氧化氮、氧自由基等)的侵害,这些氧化物质被称为活性氧(ROS)。自由基的产生和抗氧化防御是人体中的相反因素,它们之间的平衡对于维持身体健康是必要的。不健康的生活习惯或年龄的增长会打破这种平衡,导致ROS多于抗氧化剂,从而损害健康。一般来说,抗氧化机制是抗氧化分子与ROS在单电子反应中的结合。创建计算模型以快速识别抗氧化候选物对于支持实验室中的抗氧化检测实验至关重要。在本研究中,我们从一组测序数据基准集中提出了一种基于机器学习的模型用于此预测目的。实验在训练过程中采用10折交叉验证进行,并通过三个不同的独立数据集进行验证。在一组最优的序列特征上评估了不同的机器学习和深度学习算法。其中,随机森林被确定为识别抗氧化蛋白性能最高的最佳模型。我们的最优模型在训练数据集上识别抗氧化蛋白时达到了84.6%的高精度,以及灵敏度(81.5%)和特异性(85.1%)的平衡。与之前发表的关于抗氧化蛋白识别的工作相比,不同独立数据集的性能结果也显示了我们模型的重要性。