Draelos Rachel Lea, Dov David, Mazurowski Maciej A, Lo Joseph Y, Henao Ricardo, Rubin Geoffrey D, Carin Lawrence
Computer Science Department, Duke University, LSRC Building D101, 308 Research Drive, Duke Box 90129, Durham, North Carolina 27708-0129, United States of America; School of Medicine, Duke University, DUMC 3710, Durham, North Carolina 27710, United States of America.
Electrical and Computer Engineering Department, Edmund T. Pratt Jr. School of Engineering, Duke University, Box 90291, Durham, North Carolina 27708, United States of America.
Med Image Anal. 2021 Jan;67:101857. doi: 10.1016/j.media.2020.101857. Epub 2020 Oct 9.
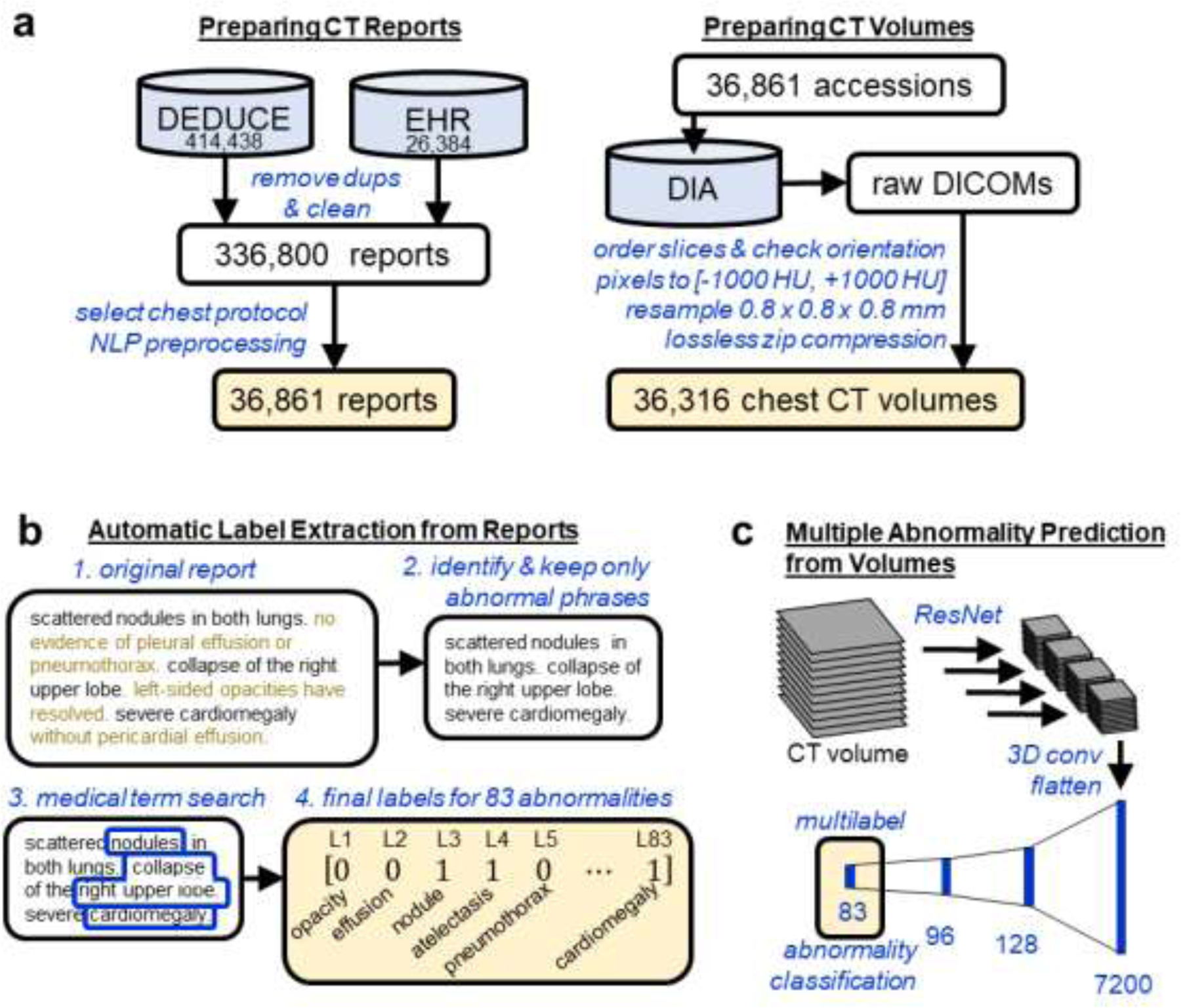
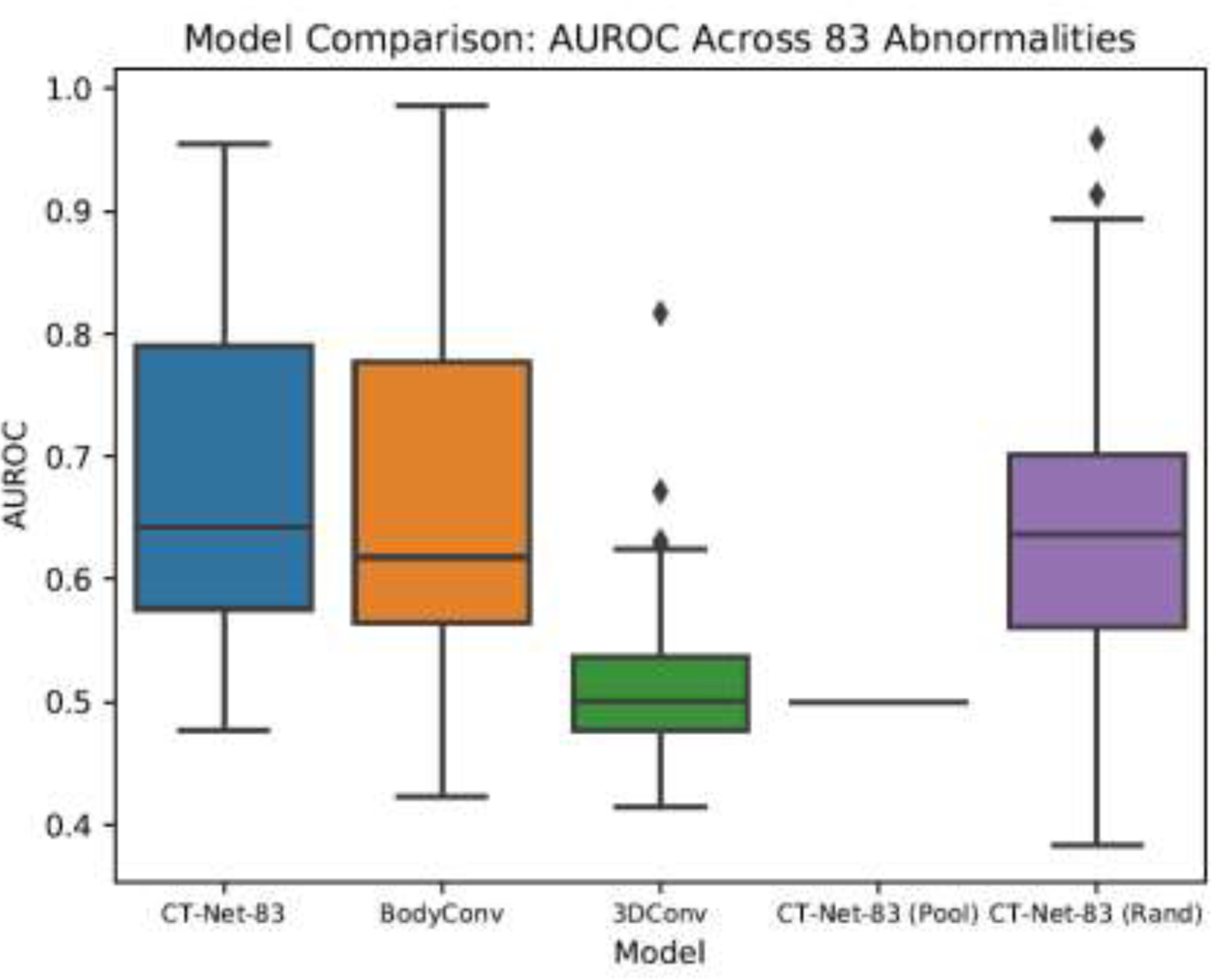
Machine learning models for radiology benefit from large-scale data sets with high quality labels for abnormalities. We curated and analyzed a chest computed tomography (CT) data set of 36,316 volumes from 19,993 unique patients. This is the largest multiply-annotated volumetric medical imaging data set reported. To annotate this data set, we developed a rule-based method for automatically extracting abnormality labels from free-text radiology reports with an average F-score of 0.976 (min 0.941, max 1.0). We also developed a model for multi-organ, multi-disease classification of chest CT volumes that uses a deep convolutional neural network (CNN). This model reached a classification performance of AUROC >0.90 for 18 abnormalities, with an average AUROC of 0.773 for all 83 abnormalities, demonstrating the feasibility of learning from unfiltered whole volume CT data. We show that training on more labels improves performance significantly: for a subset of 9 labels - nodule, opacity, atelectasis, pleural effusion, consolidation, mass, pericardial effusion, cardiomegaly, and pneumothorax - the model's average AUROC increased by 10% when the number of training labels was increased from 9 to all 83. All code for volume preprocessing, automated label extraction, and the volume abnormality prediction model is publicly available. The 36,316 CT volumes and labels will also be made publicly available pending institutional approval.
用于放射学的机器学习模型受益于具有高质量异常标签的大规模数据集。我们整理并分析了来自19993名独特患者的36316份胸部计算机断层扫描(CT)数据集。这是已报道的最大的经过多次标注的体积医学影像数据集。为了标注这个数据集,我们开发了一种基于规则的方法,用于从自由文本放射学报告中自动提取异常标签,平均F分数为0.976(最小值0.941,最大值1.0)。我们还开发了一个用于胸部CT体积的多器官、多疾病分类的模型,该模型使用深度卷积神经网络(CNN)。该模型对18种异常的分类性能达到了AUROC>0.90,对所有83种异常的平均AUROC为0.773,证明了从未经筛选的全容积CT数据中学习的可行性。我们表明,在更多标签上进行训练能显著提高性能:对于9个标签的子集——结节、实变、肺不张、胸腔积液、实变、肿块、心包积液、心脏肥大和气胸——当训练标签数量从9个增加到所有83个时,模型的平均AUROC提高了10%。所有用于体积预处理、自动标签提取和体积异常预测模型的代码都可公开获取。36316份CT体积数据和标签在获得机构批准后也将公开提供。