Department of Computational Biology, University of Lausanne, Lausanne, Switzerland.
Swiss Institute of Bioinformatics, University of Lausanne, Lausanne, Switzerland.
PLoS Genet. 2020 Nov 16;16(11):e1009049. doi: 10.1371/journal.pgen.1009049. eCollection 2020 Nov.
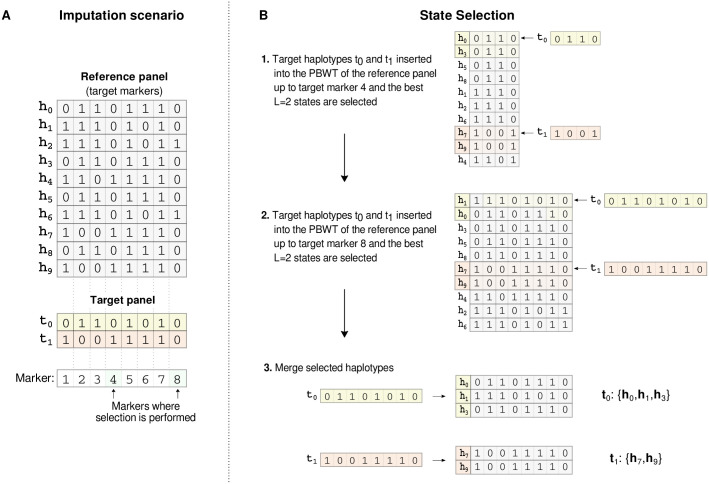
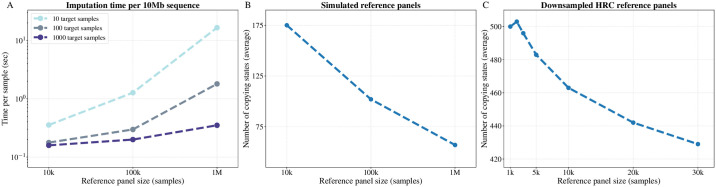
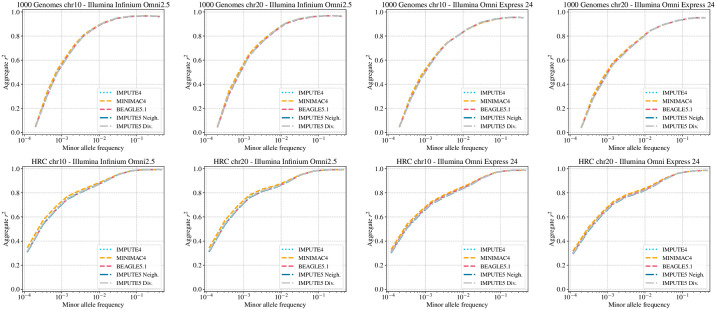
Genotype imputation is the process of predicting unobserved genotypes in a sample of individuals using a reference panel of haplotypes. In the last 10 years reference panels have increased in size by more than 100 fold. Increasing reference panel size improves accuracy of markers with low minor allele frequencies but poses ever increasing computational challenges for imputation methods. Here we present IMPUTE5, a genotype imputation method that can scale to reference panels with millions of samples. This method continues to refine the observation made in the IMPUTE2 method, that accuracy is optimized via use of a custom subset of haplotypes when imputing each individual. It achieves fast, accurate, and memory-efficient imputation by selecting haplotypes using the Positional Burrows Wheeler Transform (PBWT). By using the PBWT data structure at genotyped markers, IMPUTE5 identifies locally best matching haplotypes and long identical by state segments. The method then uses the selected haplotypes as conditioning states within the IMPUTE model. Using the HRC reference panel, which has ∼65,000 haplotypes, we show that IMPUTE5 is up to 30x faster than MINIMAC4 and up to 3x faster than BEAGLE5.1, and uses less memory than both these methods. Using simulated reference panels we show that IMPUTE5 scales sub-linearly with reference panel size. For example, keeping the number of imputed markers constant, increasing the reference panel size from 10,000 to 1 million haplotypes requires less than twice the computation time. As the reference panel increases in size IMPUTE5 is able to utilize a smaller number of reference haplotypes, thus reducing computational cost.
基因型推断是指使用单倍型参考面板预测个体样本中未观察到的基因型的过程。在过去的 10 年中,参考面板的大小增加了 100 多倍。增加参考面板的大小可以提高低次要等位基因频率标记的准确性,但为推断方法带来了越来越大的计算挑战。这里我们提出了 IMPUTE5,这是一种可以扩展到具有数百万样本的参考面板的基因型推断方法。该方法延续了 IMPUTE2 方法的观察结果,即通过在每个个体推断时使用自定义单倍型子集,可以优化准确性。它通过使用位置 Burrows Wheeler 变换 (PBWT) 选择单倍型来实现快速、准确和内存高效的推断。通过在基因分型标记处使用 PBWT 数据结构,IMPUTE5 确定局部最佳匹配的单倍型和长的同态状态段。然后,该方法使用所选的单倍型作为 IMPUTE 模型中的条件状态。使用 HRC 参考面板(约有 65,000 个单倍型),我们表明 IMPUTE5 比 MINIMAC4 快 30 倍,比 BEAGLE5.1 快 3 倍,并且使用的内存比这两种方法都少。使用模拟参考面板,我们表明 IMPUTE5 与参考面板大小呈次线性缩放。例如,保持推断标记的数量不变,将参考面板的大小从 10,000 个增加到 100 万个单倍型,所需的计算时间不到两倍。随着参考面板的增大,IMPUTE5 能够利用更少的参考单倍型,从而降低计算成本。