Dong Xinzheng, Chen Chang, Geng Qingshan, Cao Zhixin, Chen Xiaoyan, Lin Jinxiang, Jin Yu, Zhang Zhaozhi, Shi Yan, Zhang Xiaohua Douglas
School of Software Engineering, South China University of Technology, Guangzhou 510006, China.
Zhuhai Laboratory of Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education, Zhuhai College of Jilin University, Zhuhai 519041, China.
Entropy (Basel). 2019 Mar 12;21(3):274. doi: 10.3390/e21030274.
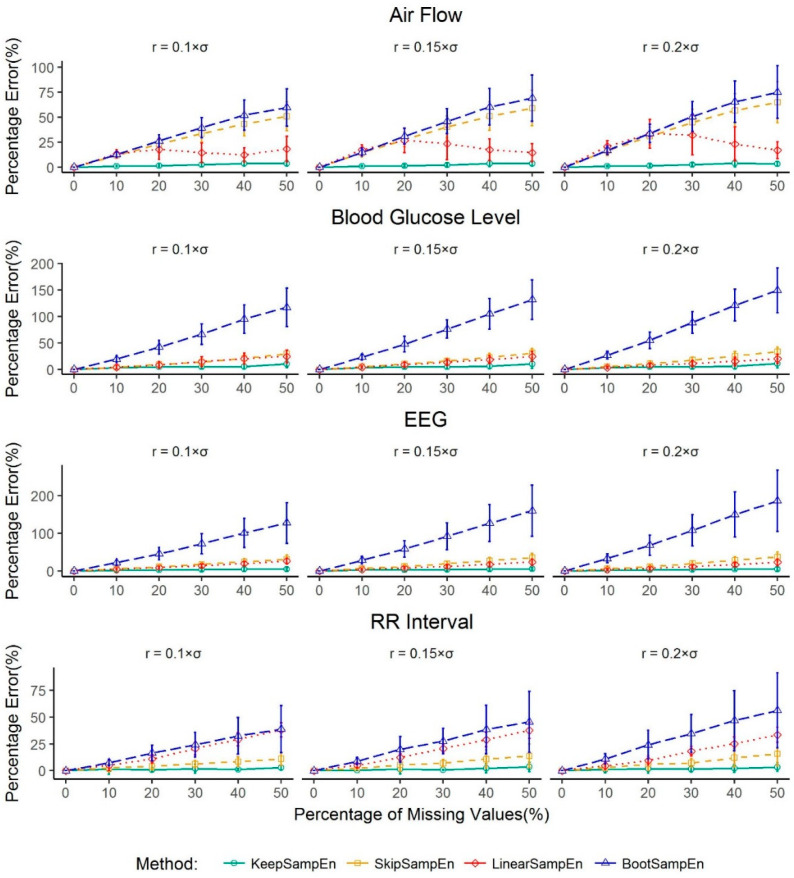
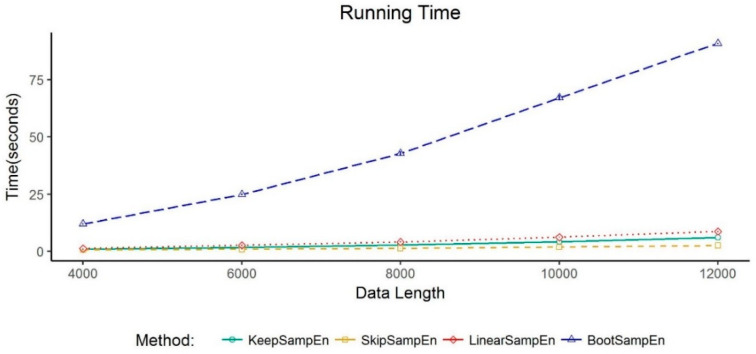
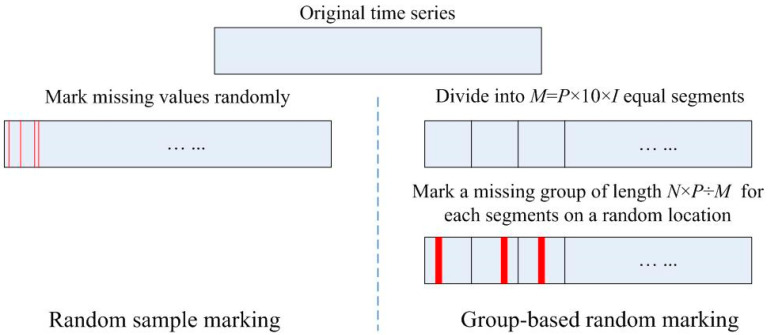
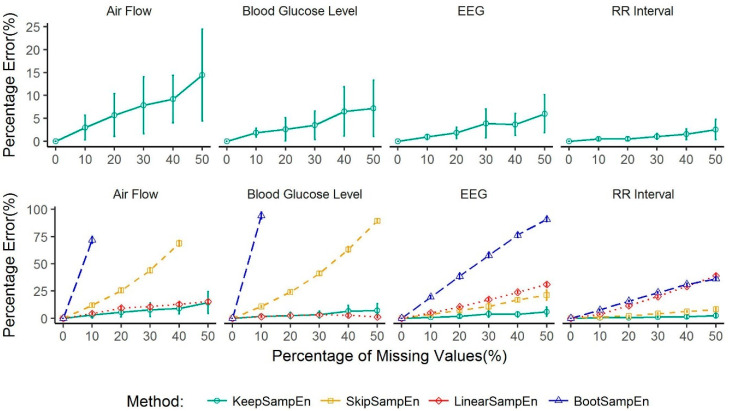
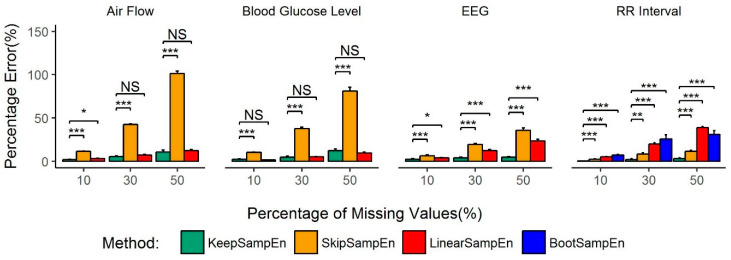
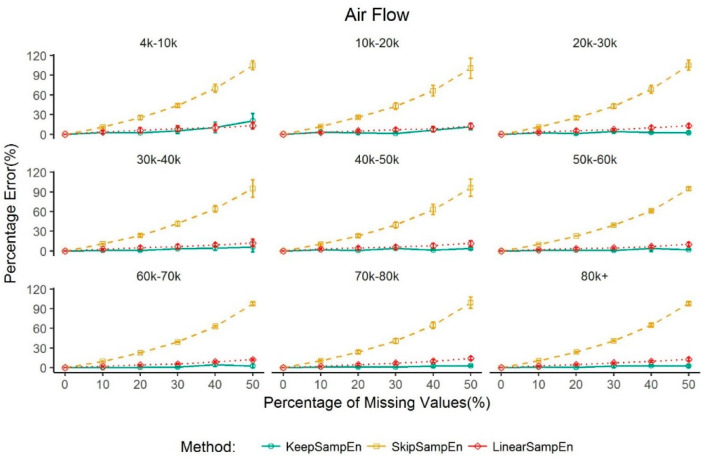
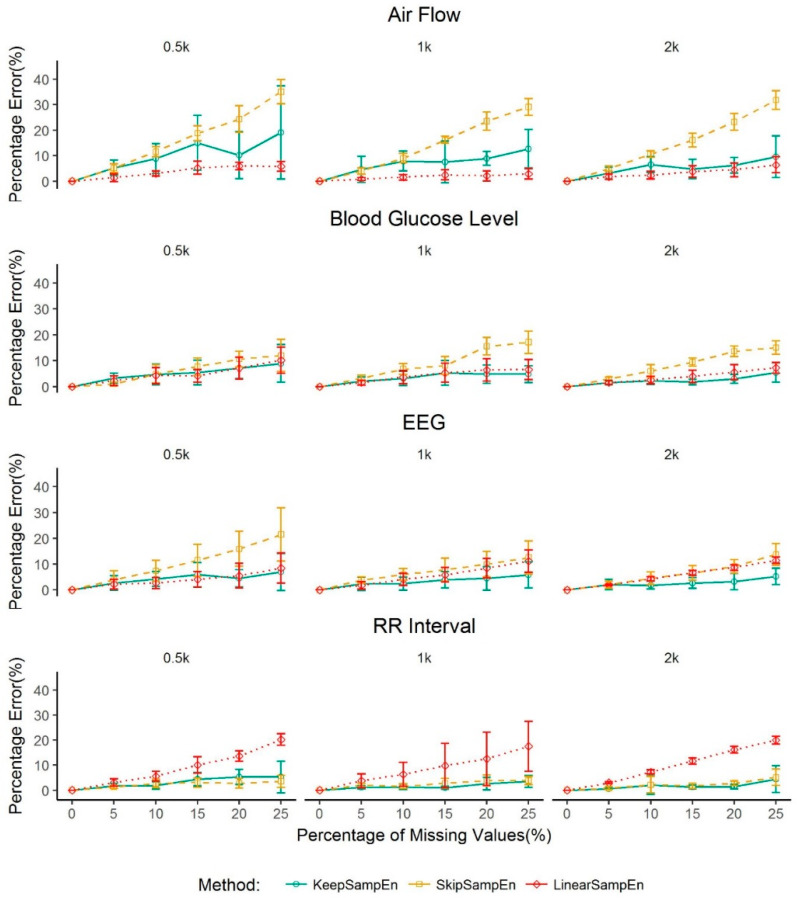
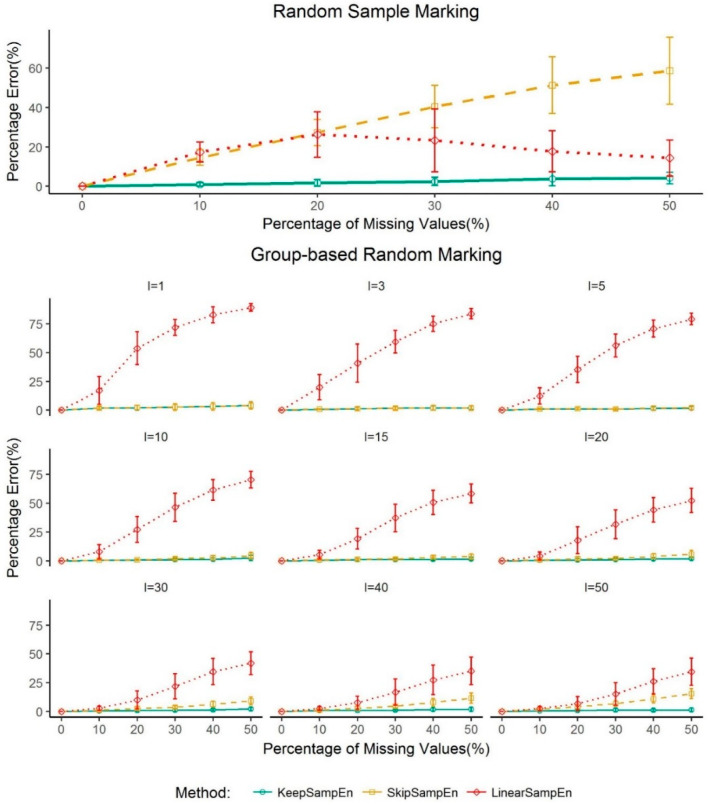
Medical devices generate huge amounts of continuous time series data. However, missing values commonly found in these data can prevent us from directly using analytic methods such as sample entropy to reveal the information contained in these data. To minimize the influence of missing points on the calculation of sample entropy, we propose a new method to handle missing values in continuous time series data. We use both experimental and simulated datasets to compare the performance (in percentage error) of our proposed method with three currently used methods: skipping the missing values, linear interpolation, and bootstrapping. Unlike the methods that involve modifying the input data, our method modifies the calculation process. This keeps the data unchanged which is less intrusive to the structure of the data. The results demonstrate that our method has a consistent lower average percentage error than other three commonly used methods in multiple common physiological signals. For missing values in common physiological signal type, different data size and generating mechanism, our method can more accurately extract the information contained in continuously monitored data than traditional methods. So it may serve as an effective tool for handling missing values and may have broad utility in analyzing sample entropy for common physiological signals. This could help develop new tools for disease diagnosis and evaluation of treatment effects.
医疗设备会生成大量的连续时间序列数据。然而,这些数据中常见的缺失值会妨碍我们直接使用诸如样本熵等分析方法来揭示其中包含的信息。为了最小化缺失点对样本熵计算的影响,我们提出了一种处理连续时间序列数据中缺失值的新方法。我们使用实验数据集和模拟数据集,将我们提出的方法与目前使用的三种方法(即跳过缺失值、线性插值和自抽样法)在性能方面(以百分比误差衡量)进行比较。与那些涉及修改输入数据的方法不同,我们的方法修改了计算过程。这使得数据保持不变,对数据结构的干扰较小。结果表明,在多种常见生理信号中,我们的方法平均百分比误差始终低于其他三种常用方法。对于常见生理信号类型中的缺失值、不同的数据大小和生成机制,我们的方法比传统方法能更准确地提取连续监测数据中包含的信息。因此,它可能成为处理缺失值的有效工具,并且在分析常见生理信号的样本熵方面可能具有广泛的用途。这有助于开发用于疾病诊断和治疗效果评估的新工具。