School of Computing, Universiti Teknologi Malaysia, Johor Bahru 81310, Malaysia.
College of Computer Science and Engineering, Taibah University, Medina 344, Saudi Arabia.
Molecules. 2020 Dec 29;26(1):128. doi: 10.3390/molecules26010128.
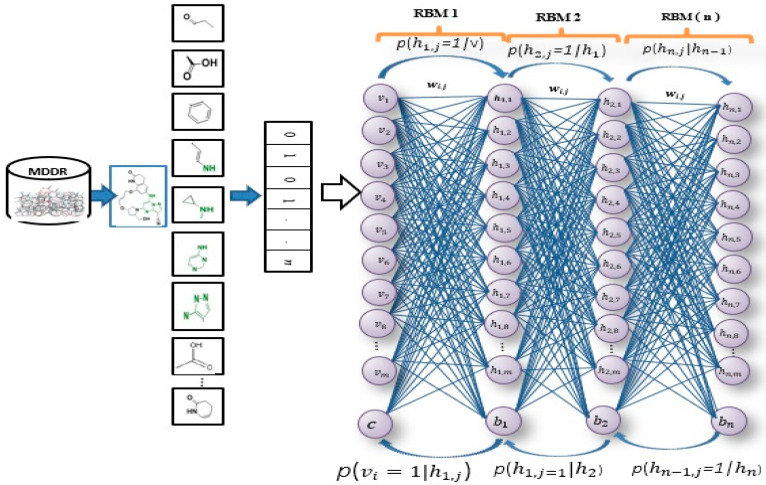
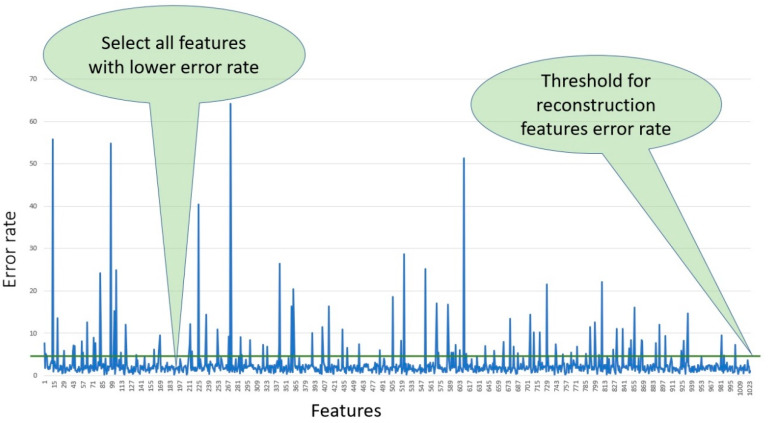
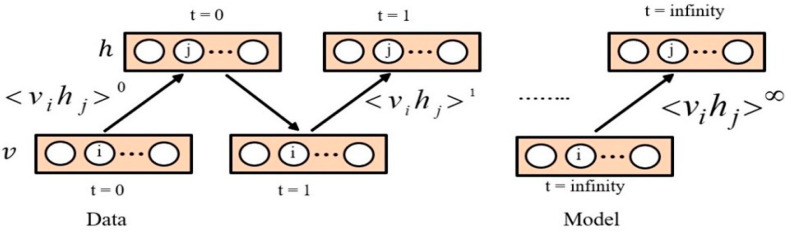
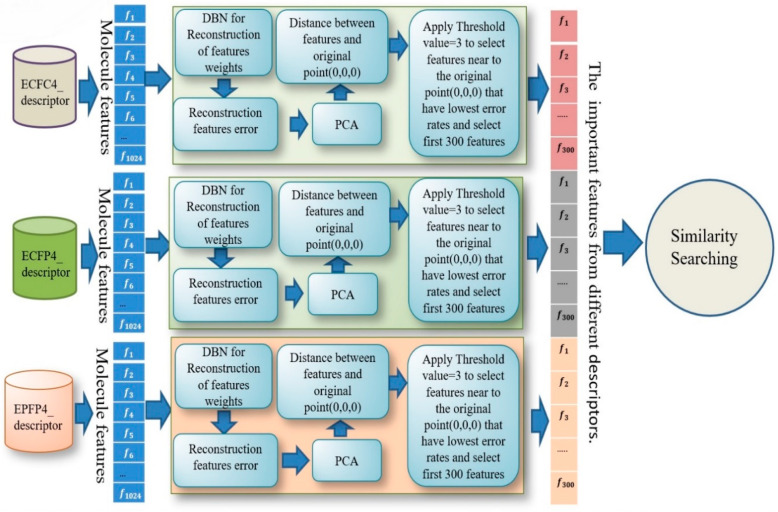
Virtual screening (VS) is a computational practice applied in drug discovery research. VS is popularly applied in a computer-based search for new lead molecules based on molecular similarity searching. In chemical databases similarity searching is used to identify molecules that have similarities to a user-defined reference structure and is evaluated by quantitative measures of intermolecular structural similarity. Among existing approaches, 2D fingerprints are widely used. The similarity of a reference structure and a database structure is measured by the computation of association coefficients. In most classical similarity approaches, it is assumed that the molecular features in both biological and non-biologically-related activity carry the same weight. However, based on the chemical structure, it has been found that some distinguishable features are more important than others. Hence, this difference should be taken consideration by placing more weight on each important fragment. The main aim of this research is to enhance the performance of similarity searching by using multiple descriptors. In this paper, a deep learning method known as deep belief networks (DBN) has been used to reweight the molecule features. Several descriptors have been used for the MDL Drug Data Report (MDDR) dataset each of which represents different important features. The proposed method has been implemented with each descriptor individually to select the important features based on a new weight, with a lower error rate, and merging together all new features from all descriptors to produce a new descriptor for similarity searching. Based on the extensive experiments conducted, the results show that the proposed method outperformed several existing benchmark similarity methods, including Bayesian inference networks (BIN), the Tanimoto similarity method (TAN), adapted similarity measure of text processing (ASMTP) and the quantum-based similarity method (SQB). The results of this proposed multi-descriptor-based on Stack of deep belief networks method (SDBN) demonstrated a higher accuracy compared to existing methods on structurally heterogeneous datasets.
虚拟筛选(VS)是一种应用于药物发现研究的计算实践。VS 通常用于基于分子相似性搜索的新型先导分子的计算机搜索。在化学数据库中,相似性搜索用于识别与用户定义的参考结构具有相似性的分子,并通过分子间结构相似性的定量度量进行评估。在现有的方法中,2D 指纹被广泛使用。参考结构和数据库结构之间的相似性通过关联系数的计算来测量。在大多数经典相似性方法中,假设生物和非生物相关活性中的分子特征具有相同的权重。然而,基于化学结构,已经发现一些可区分的特征比其他特征更重要。因此,应该通过为每个重要片段赋予更多权重来考虑这种差异。本研究的主要目的是通过使用多个描述符来提高相似性搜索的性能。在本文中,使用了一种称为深度置信网络(DBN)的深度学习方法来重新加权分子特征。已经为 MDL 药物数据报告(MDDR)数据集使用了几种描述符,每个描述符代表不同的重要特征。该方法已分别与每个描述符一起实现,以根据新的权重选择重要特征,具有较低的错误率,并合并来自所有描述符的所有新特征,以生成用于相似性搜索的新描述符。基于进行的广泛实验,结果表明,所提出的方法优于包括贝叶斯推理网络(BIN)、Tanimoto 相似性方法(TAN)、文本处理的自适应相似性度量(ASMTP)和基于量子的相似性方法(SQB)在内的几种现有基准相似性方法。与现有方法相比,基于多描述符的深度置信网络方法(SDBN)的结果在结构异构数据集上表现出更高的准确性。