Si Yuqi, Du Jingcheng, Li Zhao, Jiang Xiaoqian, Miller Timothy, Wang Fei, Jim Zheng W, Roberts Kirk
School of Biomedical Informatics, The University of Texas Health Science Center at Houston, TX, USA.
Computational Health Informatics Program (CHIP), Boston Children's Hospital and Harvard Medical School, MA, USA.
J Biomed Inform. 2021 Mar;115:103671. doi: 10.1016/j.jbi.2020.103671. Epub 2020 Dec 31.
Patient representation learning refers to learning a dense mathematical representation of a patient that encodes meaningful information from Electronic Health Records (EHRs). This is generally performed using advanced deep learning methods. This study presents a systematic review of this field and provides both qualitative and quantitative analyses from a methodological perspective.
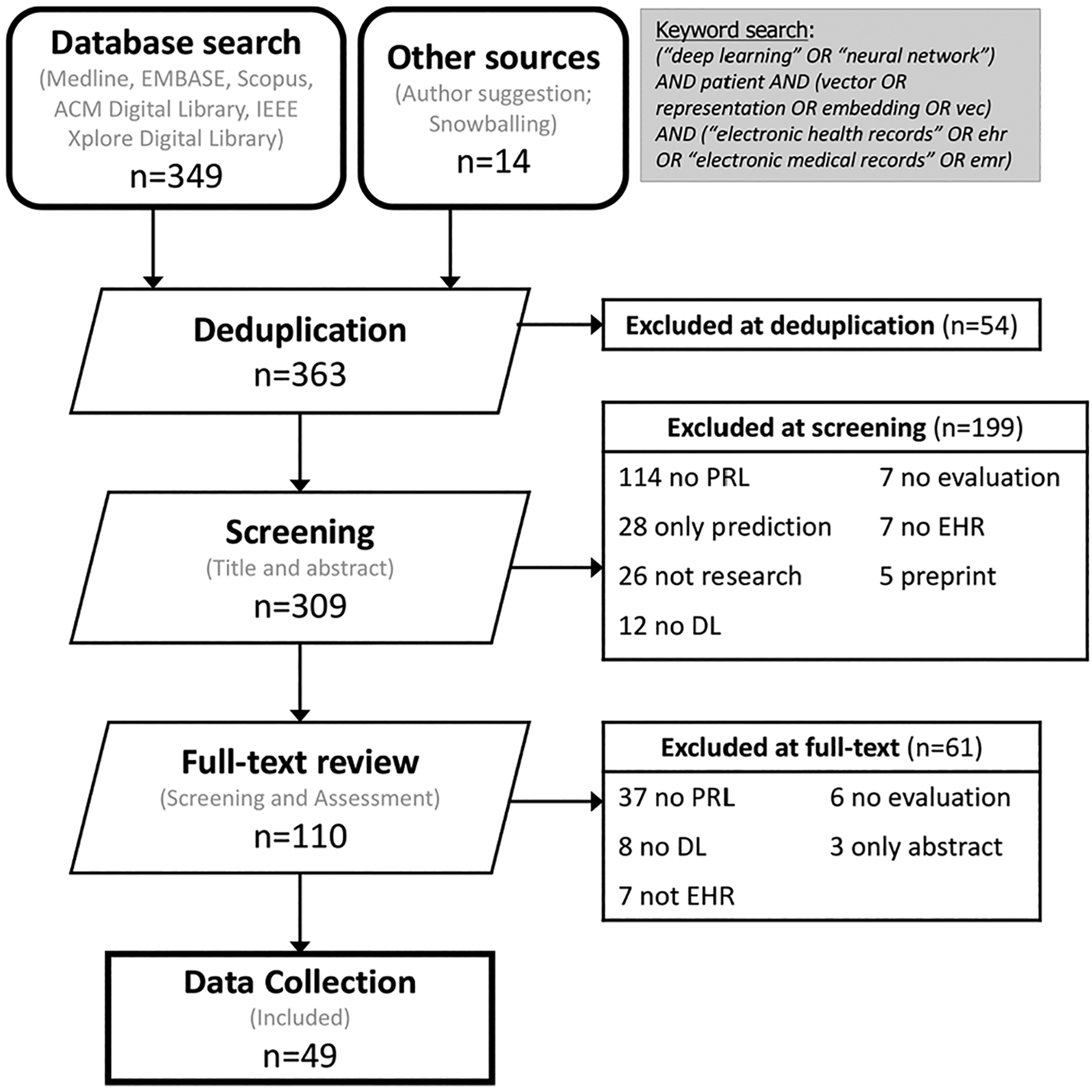
We identified studies developing patient representations from EHRs with deep learning methods from MEDLINE, EMBASE, Scopus, the Association for Computing Machinery (ACM) Digital Library, and the Institute of Electrical and Electronics Engineers (IEEE) Xplore Digital Library. After screening 363 articles, 49 papers were included for a comprehensive data collection.
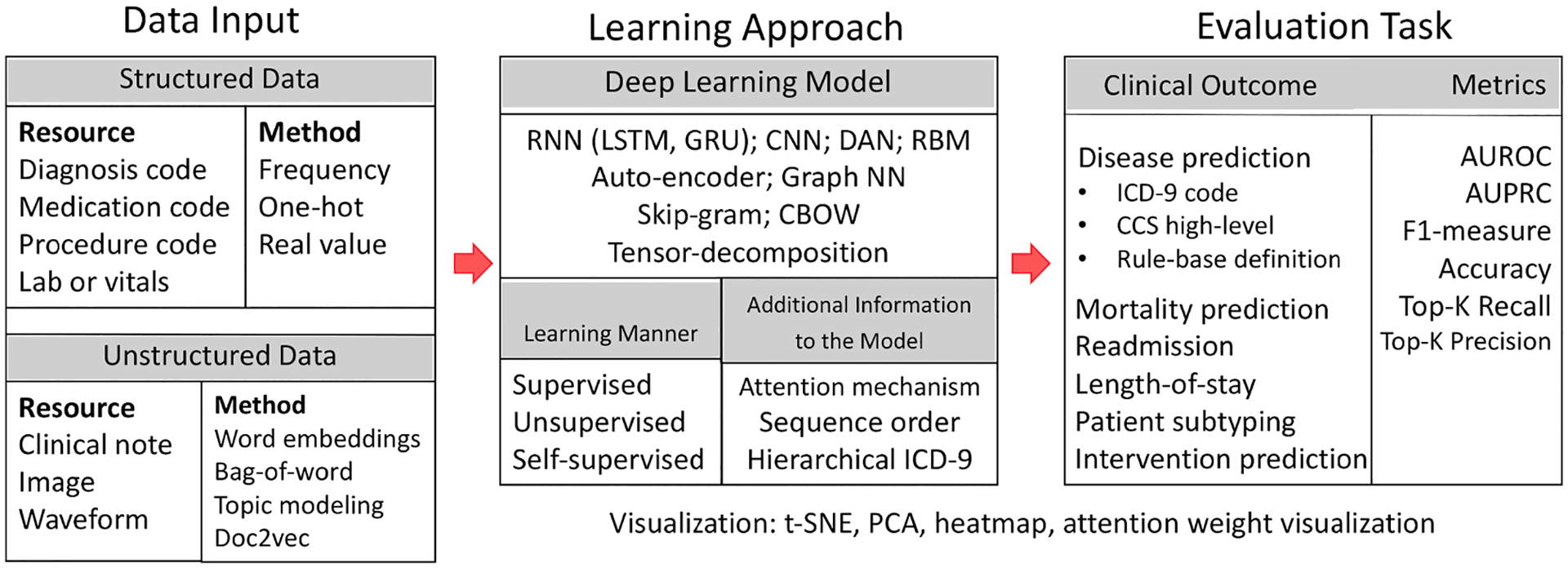
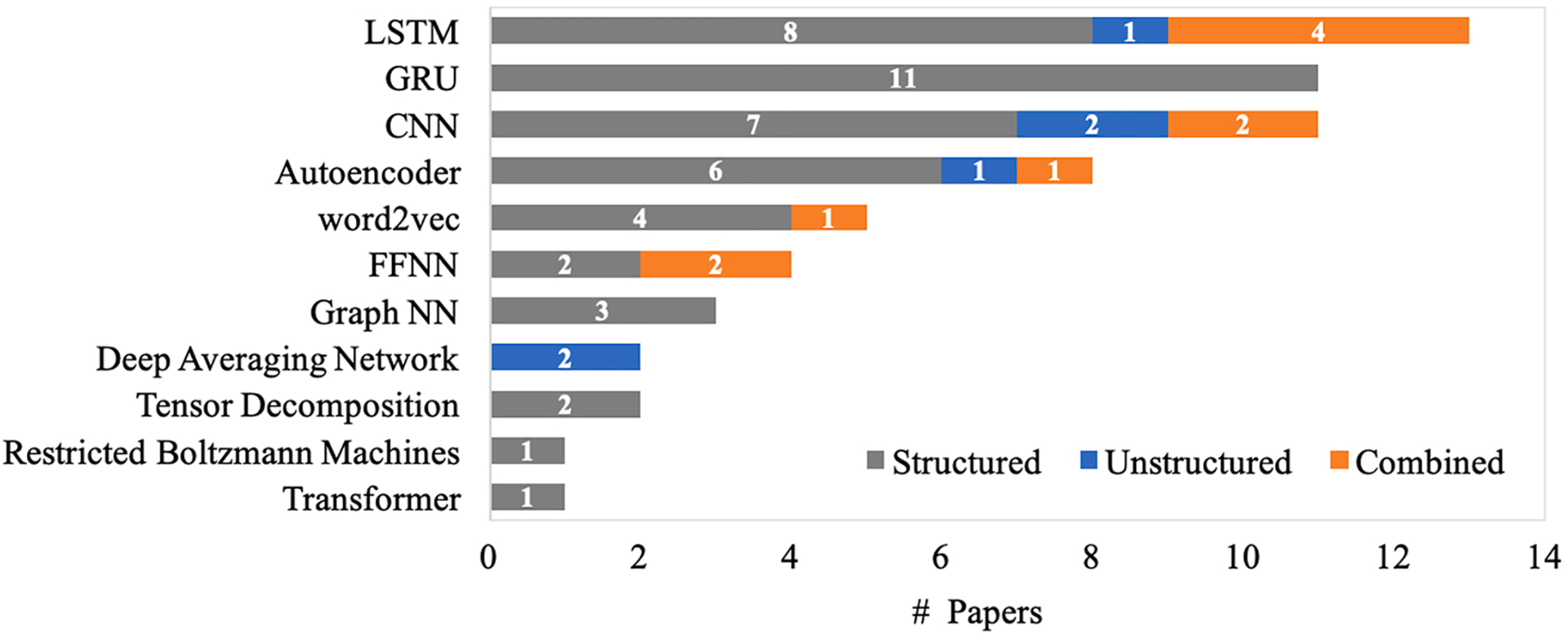
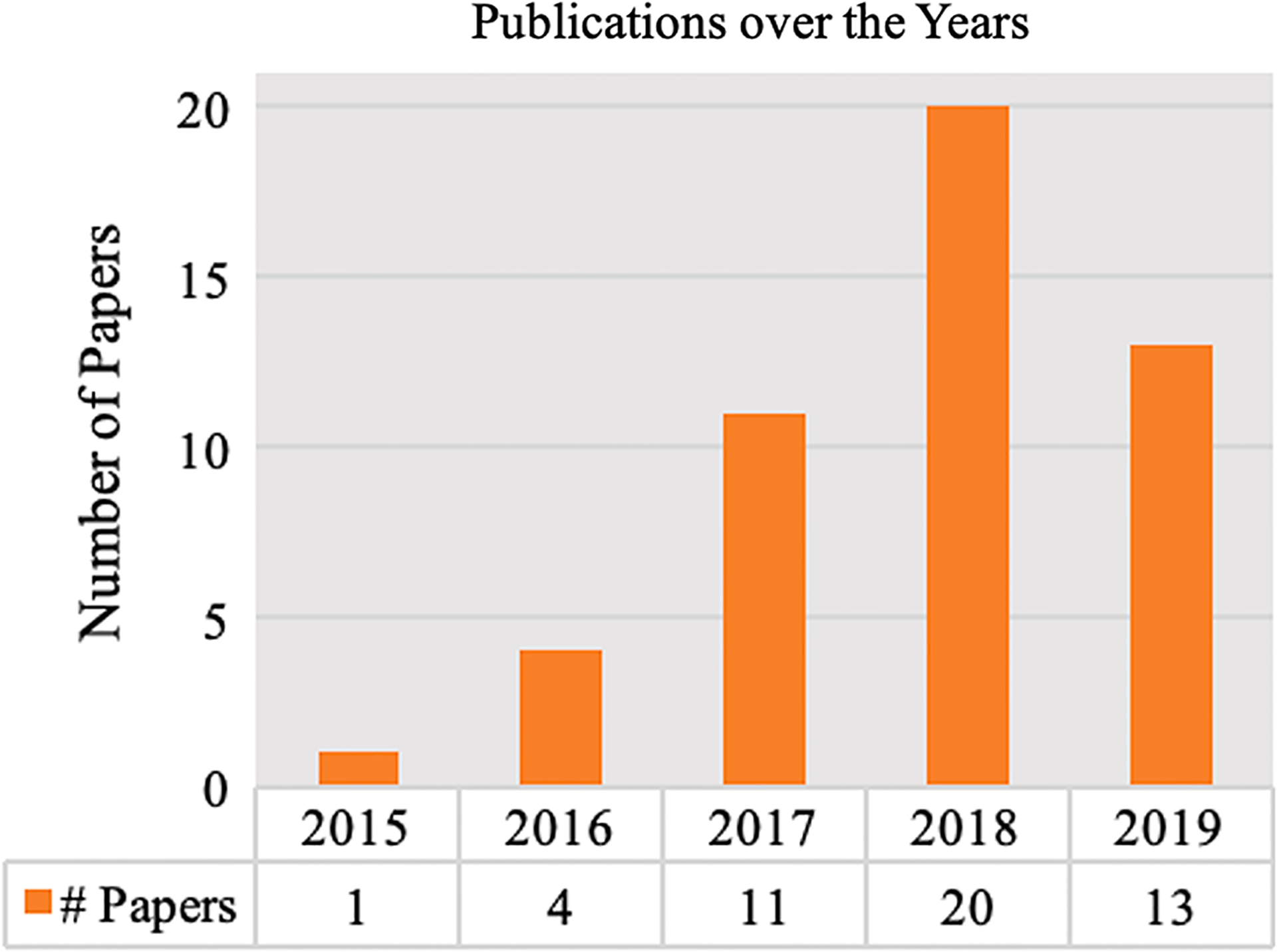
Publications developing patient representations almost doubled each year from 2015 until 2019. We noticed a typical workflow starting with feeding raw data, applying deep learning models, and ending with clinical outcome predictions as evaluations of the learned representations. Specifically, learning representations from structured EHR data was dominant (37 out of 49 studies). Recurrent Neural Networks were widely applied as the deep learning architecture (Long short-term memory: 13 studies, Gated recurrent unit: 11 studies). Learning was mainly performed in a supervised manner (30 studies) optimized with cross-entropy loss. Disease prediction was the most common application and evaluation (31 studies). Benchmark datasets were mostly unavailable (28 studies) due to privacy concerns of EHR data, and code availability was assured in 20 studies.
DISCUSSION & CONCLUSION: The existing predictive models mainly focus on the prediction of single diseases, rather than considering the complex mechanisms of patients from a holistic review. We show the importance and feasibility of learning comprehensive representations of patient EHR data through a systematic review. Advances in patient representation learning techniques will be essential for powering patient-level EHR analyses. Future work will still be devoted to leveraging the richness and potential of available EHR data. Reproducibility and transparency of reported results will hopefully improve. Knowledge distillation and advanced learning techniques will be exploited to assist the capability of learning patient representation further.
患者表征学习是指学习患者的密集数学表征,该表征对来自电子健康记录(EHR)的有意义信息进行编码。这通常使用先进的深度学习方法来执行。本研究对该领域进行了系统综述,并从方法论角度提供了定性和定量分析。
我们从MEDLINE、EMBASE、Scopus、美国计算机协会(ACM)数字图书馆和电气与电子工程师协会(IEEE)Xplore数字图书馆中,识别出使用深度学习方法从电子健康记录中开发患者表征的研究。在筛选了363篇文章后,纳入了49篇论文进行全面的数据收集。
从2015年到2019年,开发患者表征的出版物数量几乎每年都翻一番。我们注意到一个典型的工作流程,从输入原始数据开始,应用深度学习模型,最后以临床结果预测作为对所学表征的评估。具体而言,从结构化电子健康记录数据中学习表征占主导地位(49项研究中的37项)。循环神经网络被广泛用作深度学习架构(长短期记忆:13项研究,门控循环单元:11项研究)。学习主要以监督方式进行(30项研究),并通过交叉熵损失进行优化。疾病预测是最常见的应用和评估(31项研究)。由于电子健康记录数据的隐私问题,基准数据集大多不可用(28项研究),20项研究确保了代码可用性。
现有的预测模型主要侧重于单一疾病的预测,而不是从整体角度考虑患者的复杂机制。我们通过系统综述展示了学习患者电子健康记录数据综合表征的重要性和可行性。患者表征学习技术的进步对于推动患者层面的电子健康记录分析至关重要。未来的工作仍将致力于利用现有电子健康记录数据的丰富性和潜力。有望提高报告结果的可重复性和透明度。知识蒸馏和先进的学习技术将被用于进一步辅助学习患者表征的能力。