Niu Haoyu, Wei Jiamin, Chen YangQuan
Electrical Engineering and Computer Science Department, University of California, Merced, CA 95340, USA.
School of Telecommunications Engineering, Xidian University, No.2, Taibai Road, Xi'an 710071, Shaanxi, China.
Entropy (Basel). 2020 Dec 31;23(1):56. doi: 10.3390/e23010056.
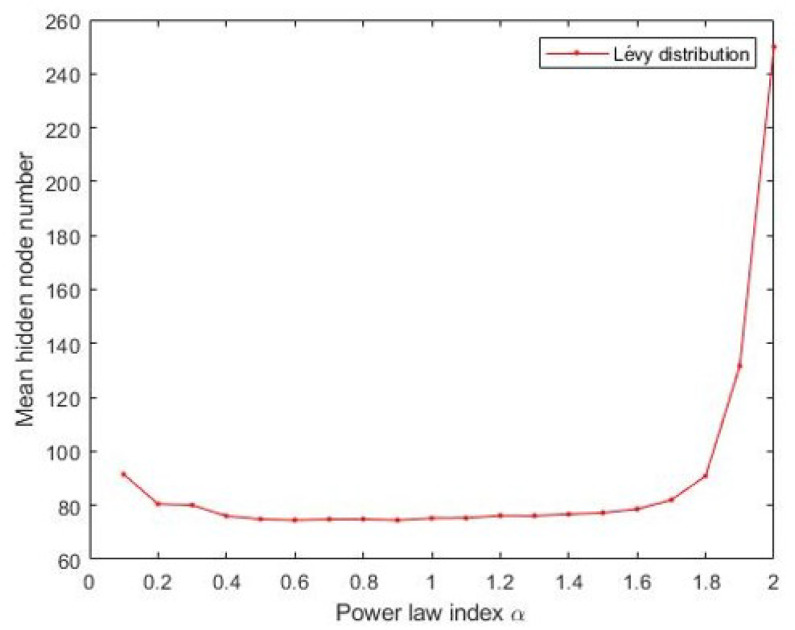
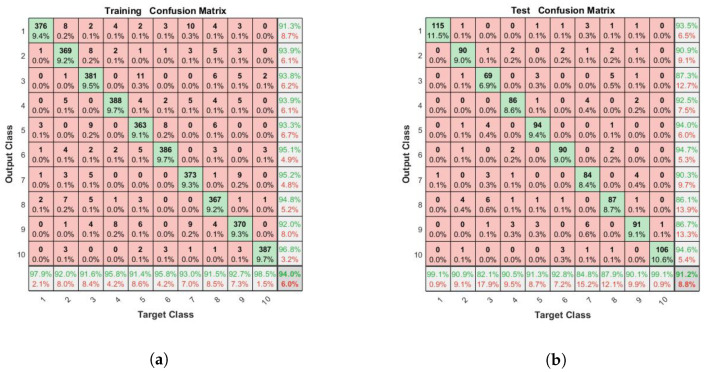
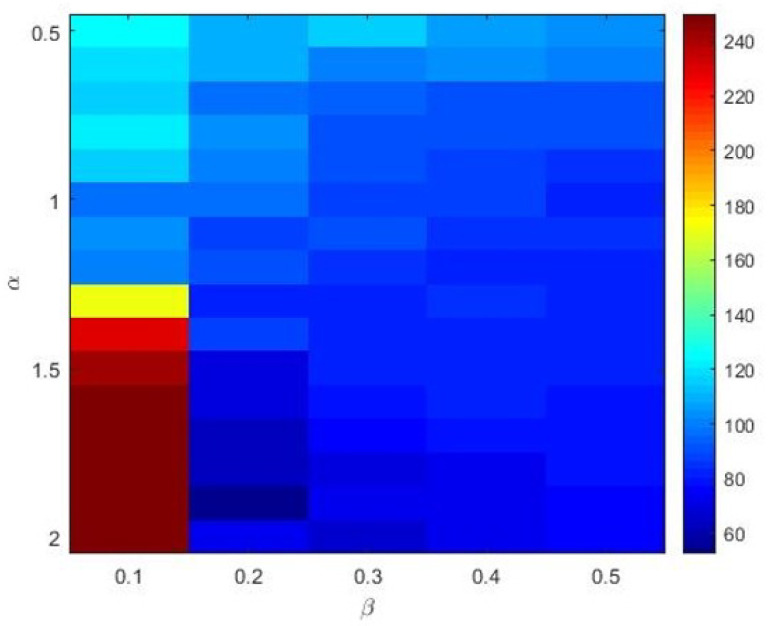
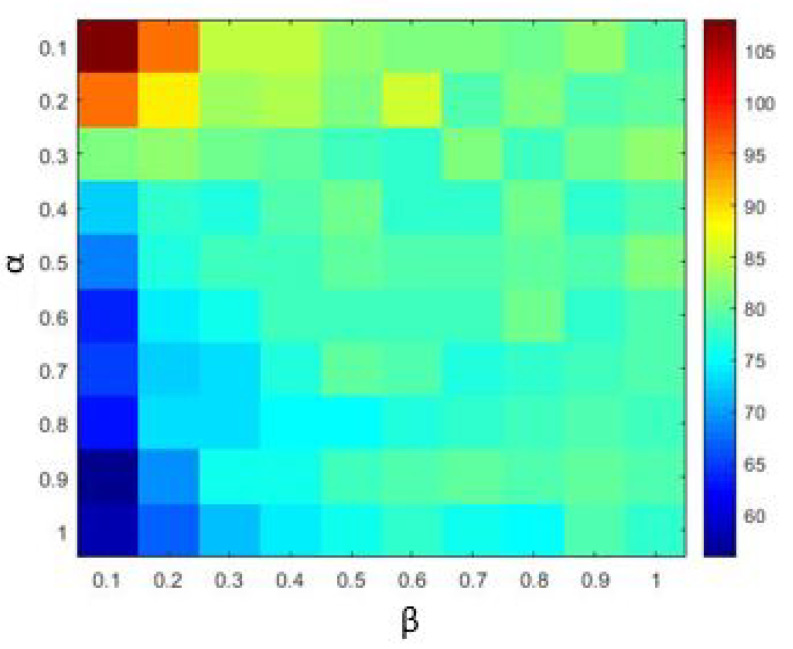
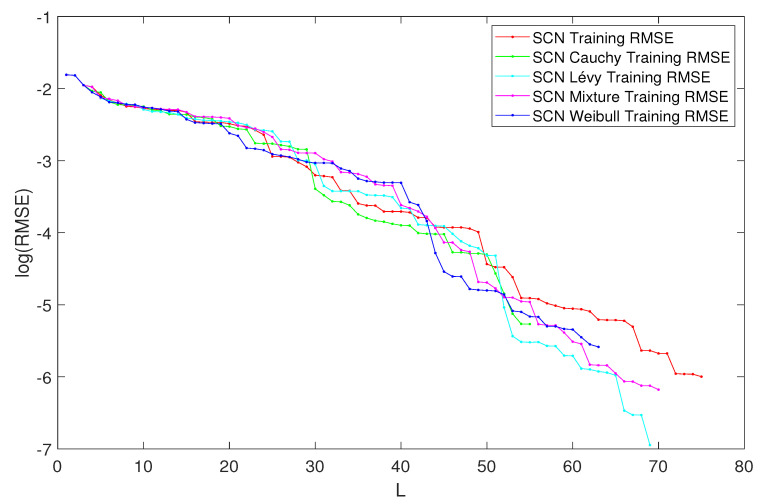
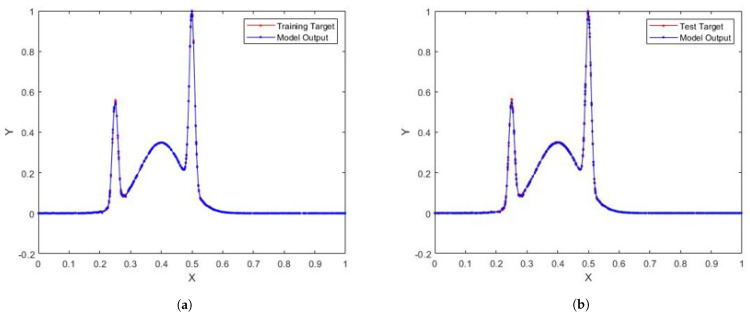
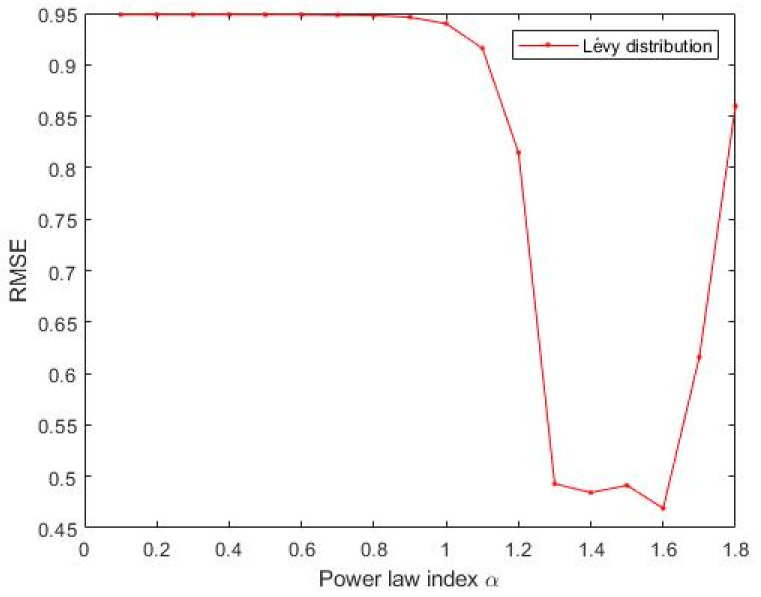
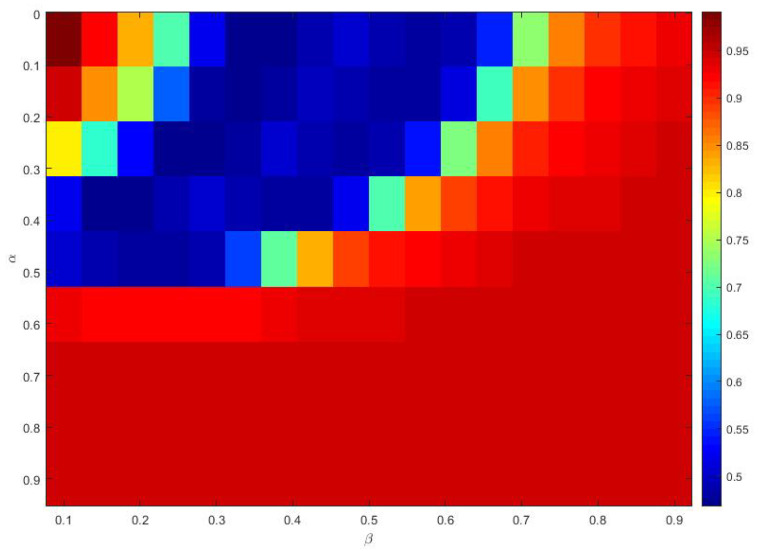
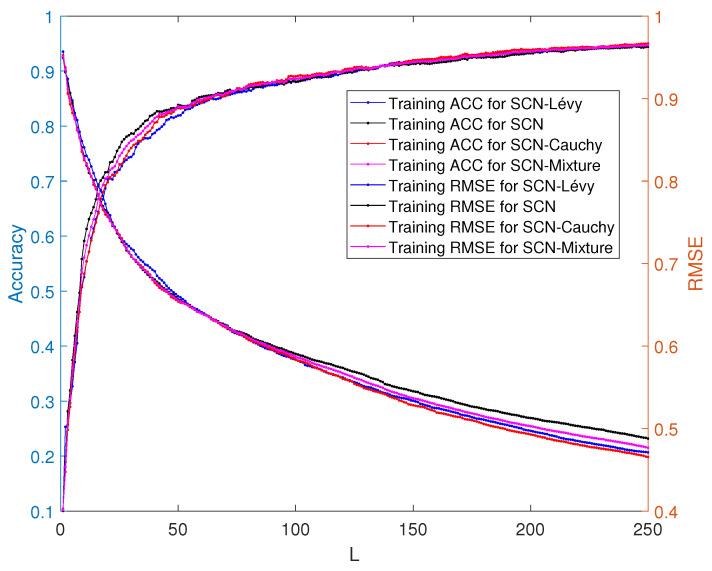
Stochastic Configuration Network (SCN) has a powerful capability for regression and classification analysis. Traditionally, it is quite challenging to correctly determine an appropriate architecture for a neural network so that the trained model can achieve excellent performance for both learning and generalization. Compared with the known randomized learning algorithms for single hidden layer feed-forward neural networks, such as Randomized Radial Basis Function (RBF) Networks and Random Vector Functional-link (RVFL), the SCN randomly assigns the input weights and biases of the hidden nodes in a supervisory mechanism. Since the parameters in the hidden layers are randomly generated in uniform distribution, hypothetically, there is optimal randomness. Heavy-tailed distribution has shown optimal randomness in an unknown environment for finding some targets. Therefore, in this research, the authors used heavy-tailed distributions to randomly initialize weights and biases to see if the new SCN models can achieve better performance than the original SCN. Heavy-tailed distributions, such as Lévy distribution, Cauchy distribution, and Weibull distribution, have been used. Since some mixed distributions show heavy-tailed properties, the mixed Gaussian and Laplace distributions were also studied in this research work. Experimental results showed improved performance for SCN with heavy-tailed distributions. For the regression model, SCN-Lévy, SCN-Mixture, SCN-Cauchy, and SCN-Weibull used less hidden nodes to achieve similar performance with SCN. For the classification model, SCN-Mixture, SCN-Lévy, and SCN-Cauchy have higher test accuracy of 91.5%, 91.7% and 92.4%, respectively. Both are higher than the test accuracy of the original SCN.
随机配置网络(SCN)具有强大的回归和分类分析能力。传统上,正确确定神经网络的合适架构颇具挑战性,以便训练后的模型在学习和泛化方面都能取得优异性能。与已知的单隐藏层前馈神经网络的随机学习算法相比,如随机径向基函数(RBF)网络和随机向量功能链接(RVFL),SCN在监督机制中随机分配隐藏节点的输入权重和偏差。由于隐藏层中的参数是在均匀分布中随机生成的,所以假设存在最优随机性。重尾分布在未知环境中寻找某些目标时已显示出最优随机性。因此,在本研究中,作者使用重尾分布来随机初始化权重和偏差,以查看新的SCN模型是否能比原始SCN取得更好的性能。已使用了重尾分布,如列维分布、柯西分布和威布尔分布。由于一些混合分布显示出重尾特性,本研究工作中还研究了混合高斯和拉普拉斯分布。实验结果表明,具有重尾分布的SCN性能有所提高。对于回归模型,SCN - 列维、SCN - 混合、SCN - 柯西和SCN - 威布尔使用较少的隐藏节点就能达到与SCN相似的性能。对于分类模型,SCN - 混合、SCN - 列维和SCN - 柯西的测试准确率分别更高,为91.5%、91.7%和92.4%。两者都高于原始SCN的测试准确率。