Savnik Iztok, Akulich Mikita, Krnc Matjaž, Škrekovski Riste
Faculty of Mathematics, Natural Sciences and Information Technologies, University of Primorska, Koper, Slovenia.
Faculty of Information Studies, Novo Mesto, Slovenia.
PLoS One. 2021 Feb 10;16(2):e0245122. doi: 10.1371/journal.pone.0245122. eCollection 2021.
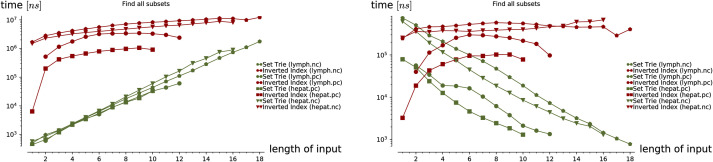
Set containment operations form an important tool in various fields such as information retrieval, AI systems, object-relational databases, and Internet applications. In the paper, a set-trie data structure for storing sets is considered, along with the efficient algorithms for the corresponding set containment operations. We present the mathematical and empirical study of the set-trie. In the mathematical study, the relevant upper-bounds on the efficiency of its expected performance are established by utilizing a natural probabilistic model. In the empirical study, we give insight into how different distributions of input data impact the efficiency of set-trie. Using the correct parameters for those randomly generated datasets, we expose the key sources of the input sensitivity of set-trie. Finally, the empirical comparison of set-trie with the inverted index is based on the real-world datasets containing sets of low cardinality. The comparison shows that the running time of set-trie consistently outperforms the inverted index by orders of magnitude.
集合包含操作在诸如信息检索、人工智能系统、对象关系数据库和互联网应用等各个领域中构成了一个重要工具。在本文中,我们考虑了一种用于存储集合的集合字典树数据结构,以及针对相应集合包含操作的高效算法。我们给出了对集合字典树的数学和实证研究。在数学研究中,通过利用一种自然概率模型建立了其预期性能效率的相关上界。在实证研究中,我们深入了解输入数据的不同分布如何影响集合字典树的效率。通过为那些随机生成的数据集使用正确的参数,我们揭示了集合字典树输入敏感性的关键来源。最后,基于包含低基数集合的真实世界数据集,对集合字典树与倒排索引进行了实证比较。比较结果表明,集合字典树的运行时间始终比倒排索引快几个数量级。