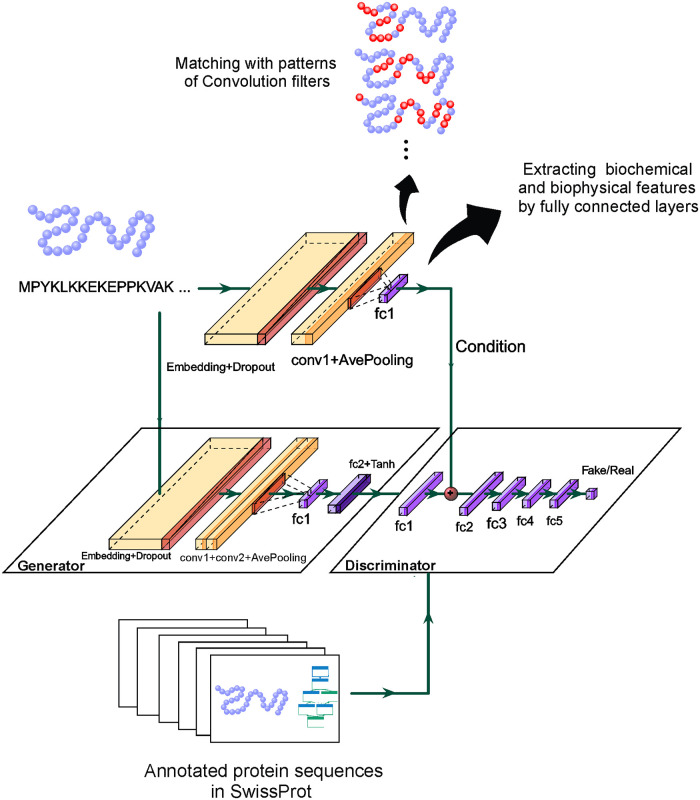
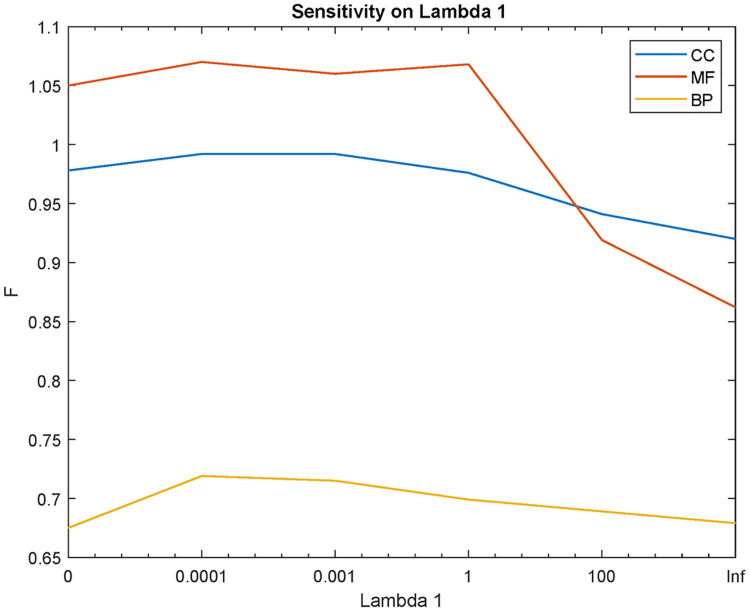
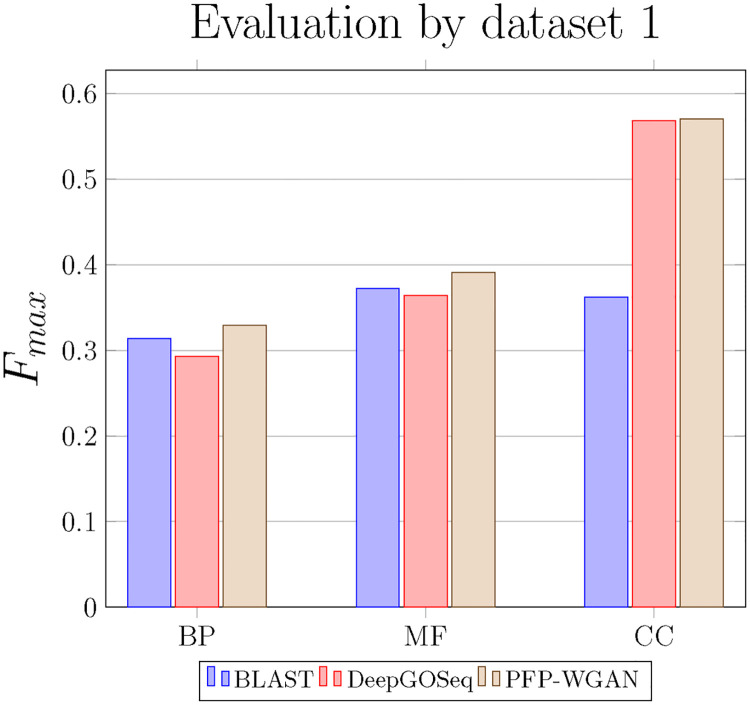
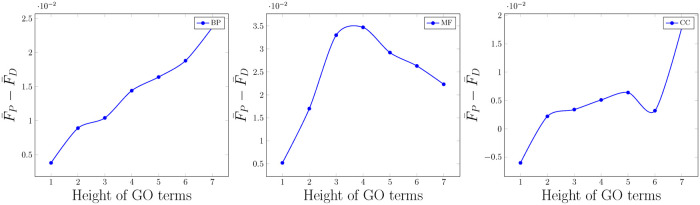
Department of Computer Engineering, Sharif University of Technology, Tehran, Iran.
Department of Mechanical Engineering, University of California Berkeley, Berkeley, California, United States of America.
PLoS One. 2021 Feb 25;16(2):e0244430. doi: 10.1371/journal.pone.0244430. eCollection 2021.
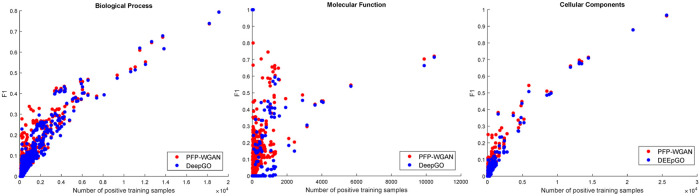
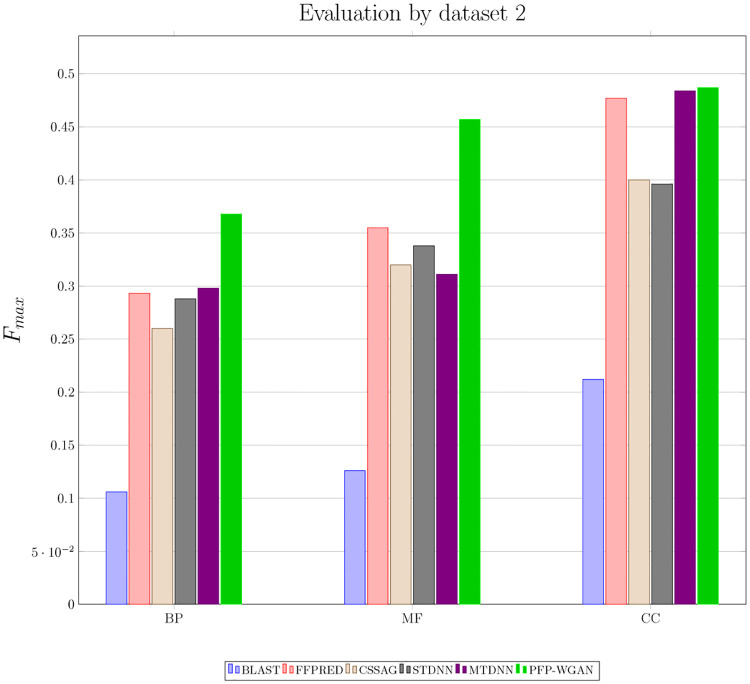
Understanding the functionality of proteins has emerged as a critical problem in recent years due to significant roles of these macro-molecules in biological mechanisms. However, in-laboratory techniques for protein function prediction are not as efficient as methods developed and processed for protein sequencing. While more than 70 million protein sequences are available today, only the functionality of around one percent of them are known. These facts have encouraged researchers to develop computational methods to infer protein functionalities from their sequences. Gene Ontology is the most well-known database for protein functions which has a hierarchical structure, where deeper terms are more determinative and specific. However, the lack of experimentally approved annotations for these specific terms limits the performance of computational methods applied on them. In this work, we propose a method to improve protein function prediction using their sequences by deeply extracting relationships between Gene Ontology terms. To this end, we construct a conditional generative adversarial network which helps to effectively discover and incorporate term correlations in the annotation process. In addition to the baseline algorithms, we compare our method with two recently proposed deep techniques that attempt to utilize Gene Ontology term correlations. Our results confirm the superiority of the proposed method compared to the previous works. Moreover, we demonstrate how our model can effectively help to assign more specific terms to sequences.
近年来,由于这些大分子在生物机制中的重要作用,理解蛋白质的功能已成为一个关键问题。然而,蛋白质功能预测的实验室技术并不像蛋白质测序那样高效。尽管目前有超过 7000 万个蛋白质序列,但已知的只有大约百分之一的蛋白质具有功能。这些事实促使研究人员开发计算方法,从蛋白质序列中推断其功能。
GO 是最著名的蛋白质功能数据库,具有层次结构,较深的术语更具决定性和特异性。然而,由于缺乏针对这些特定术语的实验验证注释,限制了应用于这些术语的计算方法的性能。在这项工作中,我们提出了一种利用蛋白质序列进行功能预测的方法,通过深入挖掘基因本体术语之间的关系来实现。为此,我们构建了一个条件生成对抗网络,以帮助在注释过程中有效地发现和合并术语相关性。
除了基准算法之外,我们还将我们的方法与两种最近提出的试图利用基因本体论术语相关性的深度技术进行了比较。我们的结果证实了与以前的工作相比,所提出的方法具有优越性。此外,我们还证明了我们的模型如何有效地帮助为序列分配更具体的术语。