Institute of Statistical Science, Academia Sinica, Taipei 11529, Taiwan, Republic of China.
Crop Science Division, Taiwan Agricultural Research Institute, Council of Agriculture, Taichung 41362, Taiwan, Republic of China.
G3 (Bethesda). 2021 Apr 15;11(4). doi: 10.1093/g3journal/jkab056.
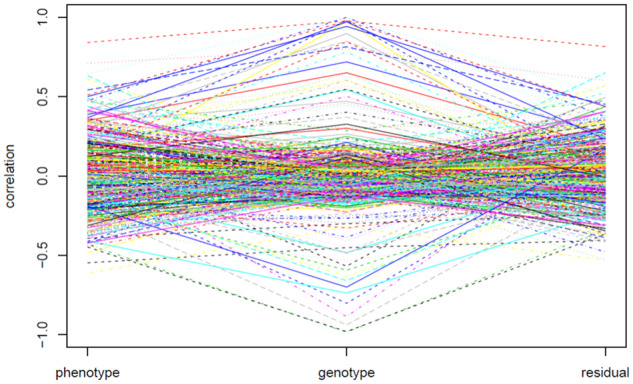
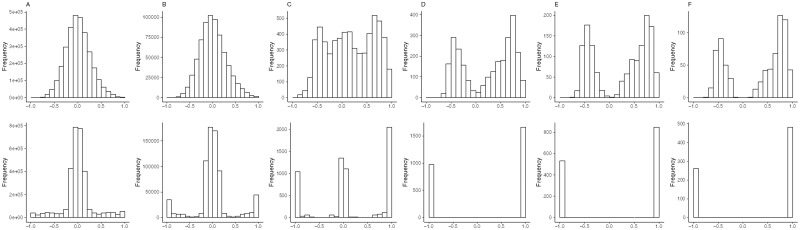
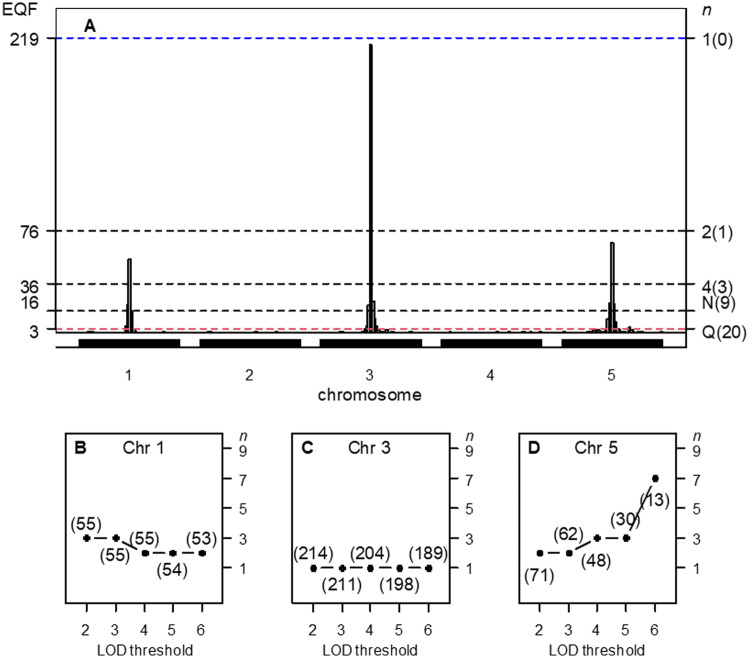
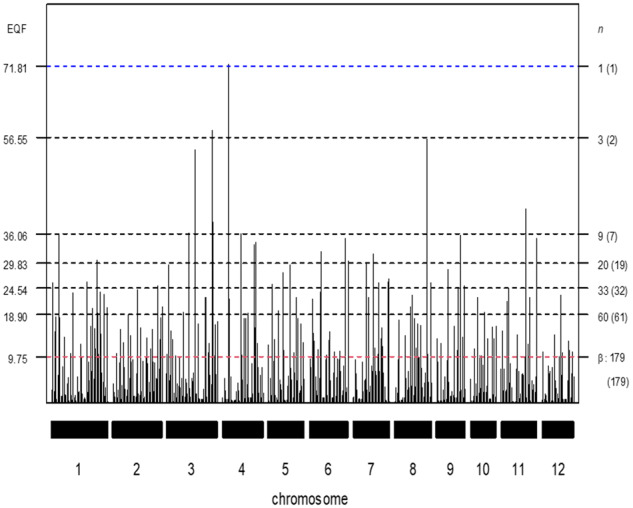
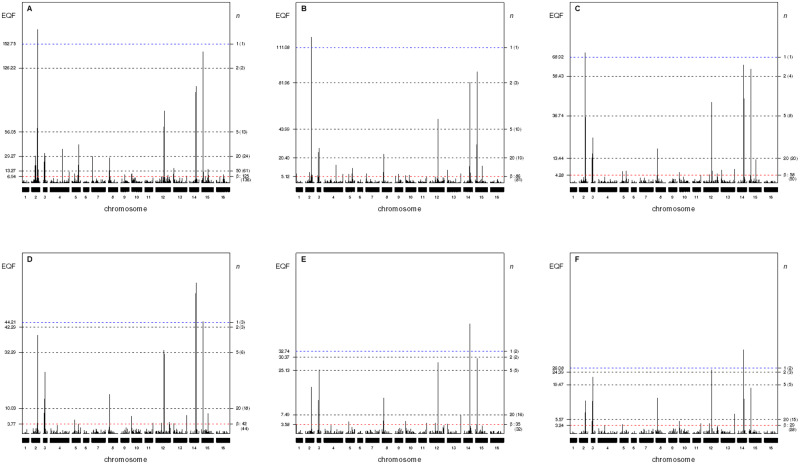
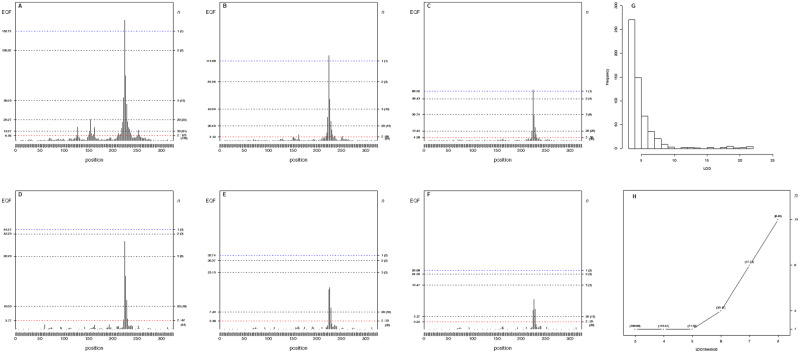
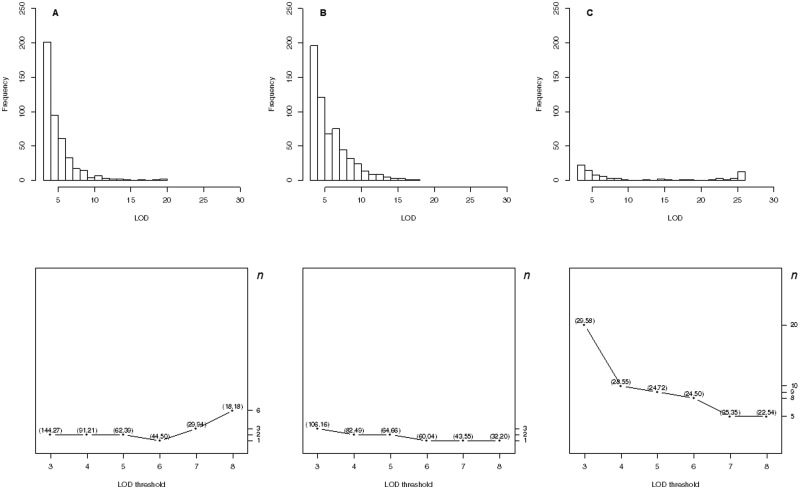
Quantitative trait loci (QTL) hotspots (genomic locations enriched in QTL) are a common and notable feature when collecting many QTL for various traits in many areas of biological studies. The QTL hotspots are important and attractive since they are highly informative and may harbor genes for the quantitative traits. So far, the current statistical methods for QTL hotspot detection use either the individual-level data from the genetical genomics experiments or the summarized data from public QTL databases to proceed with the detection analysis. These methods may suffer from the problems of ignoring the correlation structure among traits, neglecting the magnitude of LOD scores for the QTL, or paying a very high computational cost, which often lead to the detection of excessive spurious hotspots, failure to discover biologically interesting hotspots composed of a small-to-moderate number of QTL with strong LOD scores, and computational intractability, respectively, during the detection process. In this article, we describe a statistical framework that can handle both types of data as well as address all the problems at a time for QTL hotspot detection. Our statistical framework directly operates on the QTL matrix and hence has a very cheap computational cost and is deployed to take advantage of the QTL mapping results for assisting the detection analysis. Two special devices, trait grouping and top γn,α profile, are introduced into the framework. The trait grouping attempts to group the traits controlled by closely linked or pleiotropic QTL together into the same trait groups and randomly allocates these QTL together across the genomic positions separately by trait group to account for the correlation structure among traits, so as to have the ability to obtain much stricter thresholds and dismiss spurious hotspots. The top γn,α profile is designed to outline the LOD-score pattern of QTL in a hotspot across the different hotspot architectures, so that it can serve to identify and characterize the types of QTL hotspots with varying sizes and LOD-score distributions. Real examples, numerical analysis, and simulation study are performed to validate our statistical framework, investigate the detection properties, and also compare with the current methods in QTL hotspot detection. The results demonstrate that the proposed statistical framework can effectively accommodate the correlation structure among traits, identify the types of hotspots, and still keep the notable features of easy implementation and fast computation for practical QTL hotspot detection.
数量性状基因座(QTL)热点(富含 QTL 的基因组位置)是在生物研究的许多领域中收集各种性状的许多 QTL 时的常见和显著特征。QTL 热点非常重要和有吸引力,因为它们提供了丰富的信息,并且可能包含数量性状的基因。到目前为止,用于 QTL 热点检测的当前统计方法要么使用来自遗传基因组学实验的个体水平数据,要么使用公共 QTL 数据库的汇总数据来进行检测分析。这些方法可能会遇到忽略性状之间相关性结构、忽略 QTL 的 LOD 得分大小或付出非常高的计算成本的问题,这通常会导致检测到过多的虚假热点,无法发现由少数几个具有强 LOD 得分的 QTL 组成的生物学上有趣的热点,以及计算上的不可行性,分别在检测过程中。在本文中,我们描述了一个统计框架,该框架可以同时处理这两种类型的数据,并解决 QTL 热点检测过程中的所有问题。我们的统计框架直接作用于 QTL 矩阵,因此计算成本非常低,并利用 QTL 映射结果来辅助检测分析。引入了两个特殊设备,性状分组和 top γn,α 轮廓,到框架中。性状分组尝试将由紧密连锁或多效性 QTL 控制的性状分组到同一个性状组中,并通过性状组将这些 QTL 随机分配到基因组位置上,以解释性状之间的相关性结构,从而能够获得更严格的阈值并排除虚假热点。top γn,α 轮廓旨在描绘 QTL 在不同热点结构中的 LOD 得分模式,以便能够识别和描述具有不同大小和 LOD 得分分布的 QTL 热点类型。实际示例、数值分析和模拟研究用于验证我们的统计框架,研究检测特性,并与 QTL 热点检测中的当前方法进行比较。结果表明,所提出的统计框架能够有效地适应性状之间的相关性结构,识别热点类型,并且仍然保持易于实现和快速计算的显著特征,适用于实际的 QTL 热点检测。