Kilicoglu Halil, Rosemblat Graciela, Hoang Linh, Wadhwa Sahil, Peng Zeshan, Malički Mario, Schneider Jodi, Ter Riet Gerben
School of Information Sciences, University of Illinois at Urbana-Champaign, Champaign, IL, USA; U.S. National Library of Medicine, National Institutes of Health, Bethesda, MD, USA.
U.S. National Library of Medicine, National Institutes of Health, Bethesda, MD, USA.
J Biomed Inform. 2021 Apr;116:103717. doi: 10.1016/j.jbi.2021.103717. Epub 2021 Feb 26.
To annotate a corpus of randomized controlled trial (RCT) publications with the checklist items of CONSORT reporting guidelines and using the corpus to develop text mining methods for RCT appraisal.
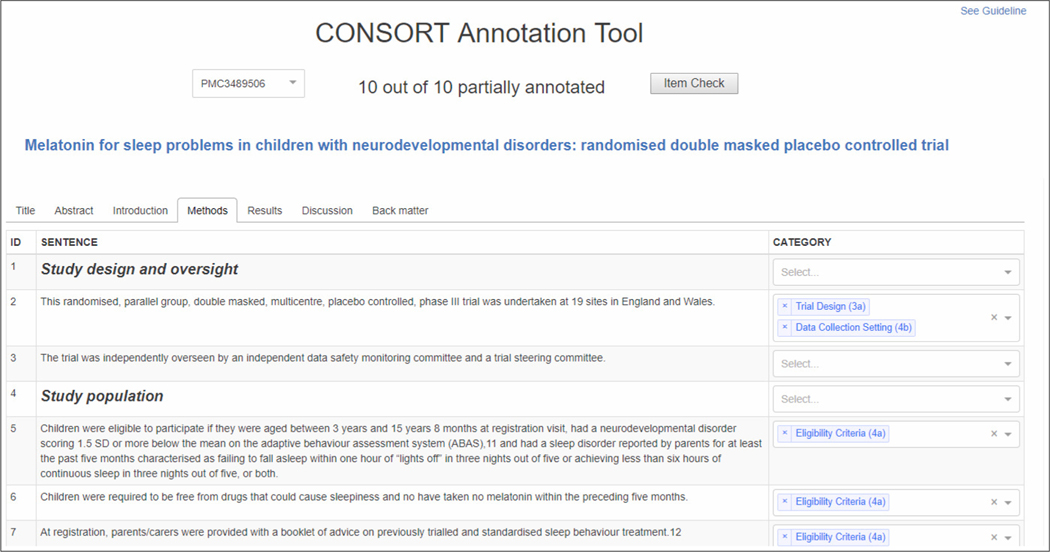
We annotated a corpus of 50 RCT articles at the sentence level using 37 fine-grained CONSORT checklist items. A subset (31 articles) was double-annotated and adjudicated, while 19 were annotated by a single annotator and reconciled by another. We calculated inter-annotator agreement at the article and section level using MASI (Measuring Agreement on Set-Valued Items) and at the CONSORT item level using Krippendorff's α. We experimented with two rule-based methods (phrase-based and section header-based) and two supervised learning approaches (support vector machine and BioBERT-based neural network classifiers), for recognizing 17 methodology-related items in the RCT Methods sections.
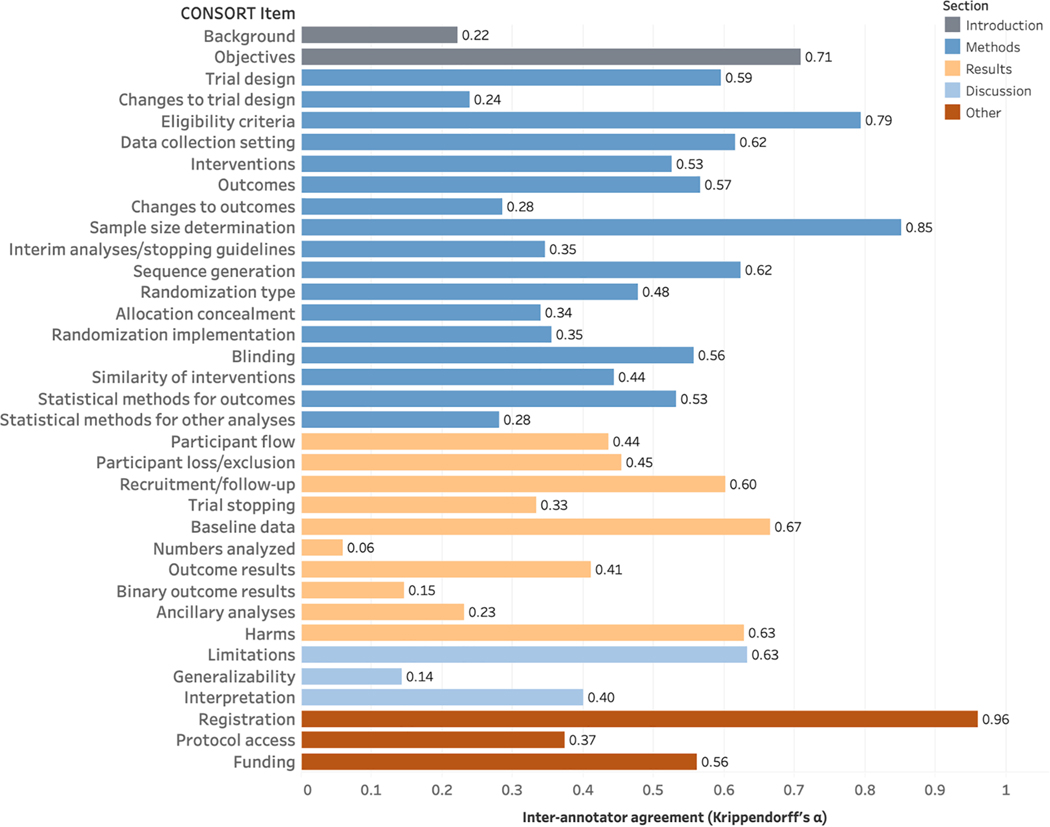
We created CONSORT-TM consisting of 10,709 sentences, 4,845 (45%) of which were annotated with 5,246 labels. A median of 28 CONSORT items (out of possible 37) were annotated per article. Agreement was moderate at the article and section levels (average MASI: 0.60 and 0.64, respectively). Agreement varied considerably among individual checklist items (Krippendorff's α= 0.06-0.96). The model based on BioBERT performed best overall for recognizing methodology-related items (micro-precision: 0.82, micro-recall: 0.63, micro-F1: 0.71). Combining models using majority vote and label aggregation further improved precision and recall, respectively.
Our annotated corpus, CONSORT-TM, contains more fine-grained information than earlier RCT corpora. Low frequency of some CONSORT items made it difficult to train effective text mining models to recognize them. For the items commonly reported, CONSORT-TM can serve as a testbed for text mining methods that assess RCT transparency, rigor, and reliability, and support methods for peer review and authoring assistance. Minor modifications to the annotation scheme and a larger corpus could facilitate improved text mining models. CONSORT-TM is publicly available at https://github.com/kilicogluh/CONSORT-TM.
用CONSORT报告指南的清单项目注释随机对照试验(RCT)出版物语料库,并使用该语料库开发用于RCT评估的文本挖掘方法。
我们使用37个细粒度的CONSORT清单项目在句子层面注释了一个包含50篇RCT文章的语料库。一个子集(31篇文章)进行了双人注释和裁决,而19篇由一名注释者注释并由另一名注释者核对。我们使用MASI(集值项目一致性测量)在文章和章节层面以及使用Krippendorff's α在CONSORT项目层面计算注释者间一致性。我们试验了两种基于规则的方法(基于短语和基于章节标题)和两种监督学习方法(支持向量机和基于BioBERT的神经网络分类器),用于识别RCT方法部分中的17个与方法相关的项目。
我们创建了CONSORT-TM,它由10,709个句子组成,其中4,845个(45%)被标注了5,246个标签。每篇文章标注的CONSORT项目中位数为28个(可能的37个项目中)。在文章和章节层面一致性为中等(平均MASI分别为0.60和0.64)。各个清单项目之间的一致性差异很大(Krippendorff's α = 0.06 - 0.96)。基于BioBERT的模型在识别与方法相关的项目方面总体表现最佳(微精度:0.82,微召回率:0.63,微F1值:0.71)。使用多数投票和标签聚合组合模型分别进一步提高了精度和召回率。
我们注释的语料库CONSORT-TM比早期的RCT语料库包含更细粒度的信息。一些CONSORT项目的低频使得难以训练有效的文本挖掘模型来识别它们。对于常见报告的项目,CONSORT-TM可以作为评估RCT透明度、严谨性和可靠性的文本挖掘方法的测试平台,并支持同行评审和作者辅助方法。对注释方案进行小的修改并增加语料库规模可以促进改进文本挖掘模型。CONSORT-TM可在https://github.com/kilicogluh/CONSORT-TM上公开获取。