School of Information Sciences, University of Illinois Urbana-Champaign, 501 Daniel Street, Champaign, 61820, IL, USA.
Department of Biological Sciences, Binghamton University, 4400 Vestal Parkway East, New York City, 13902, NY, USA.
J Biomed Inform. 2024 Apr;152:104628. doi: 10.1016/j.jbi.2024.104628. Epub 2024 Mar 26.
Acknowledging study limitations in a scientific publication is a crucial element in scientific transparency and progress. However, limitation reporting is often inadequate. Natural language processing (NLP) methods could support automated reporting checks, improving research transparency. In this study, our objective was to develop a dataset and NLP methods to detect and categorize self-acknowledged limitations (e.g., sample size, blinding) reported in randomized controlled trial (RCT) publications.
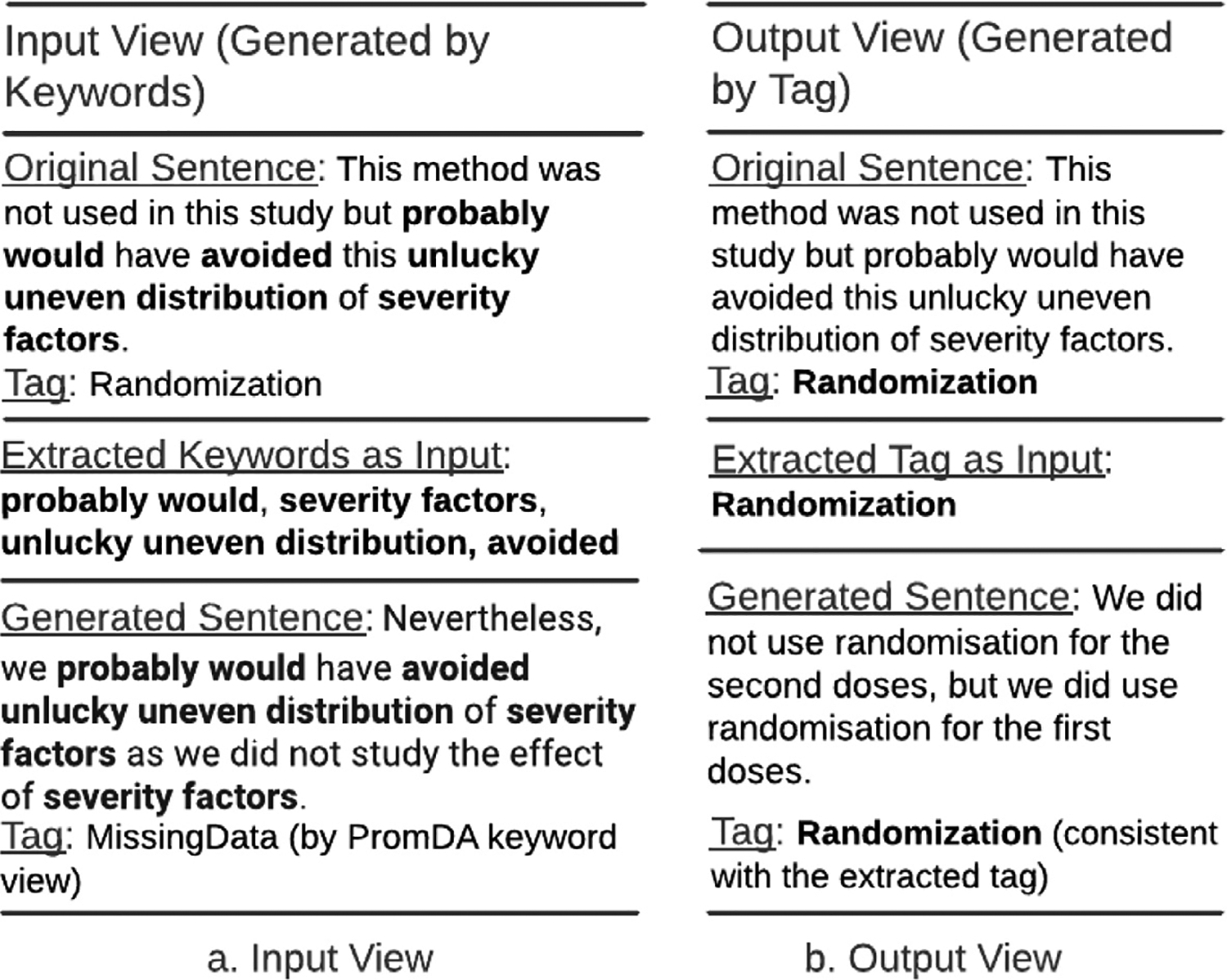
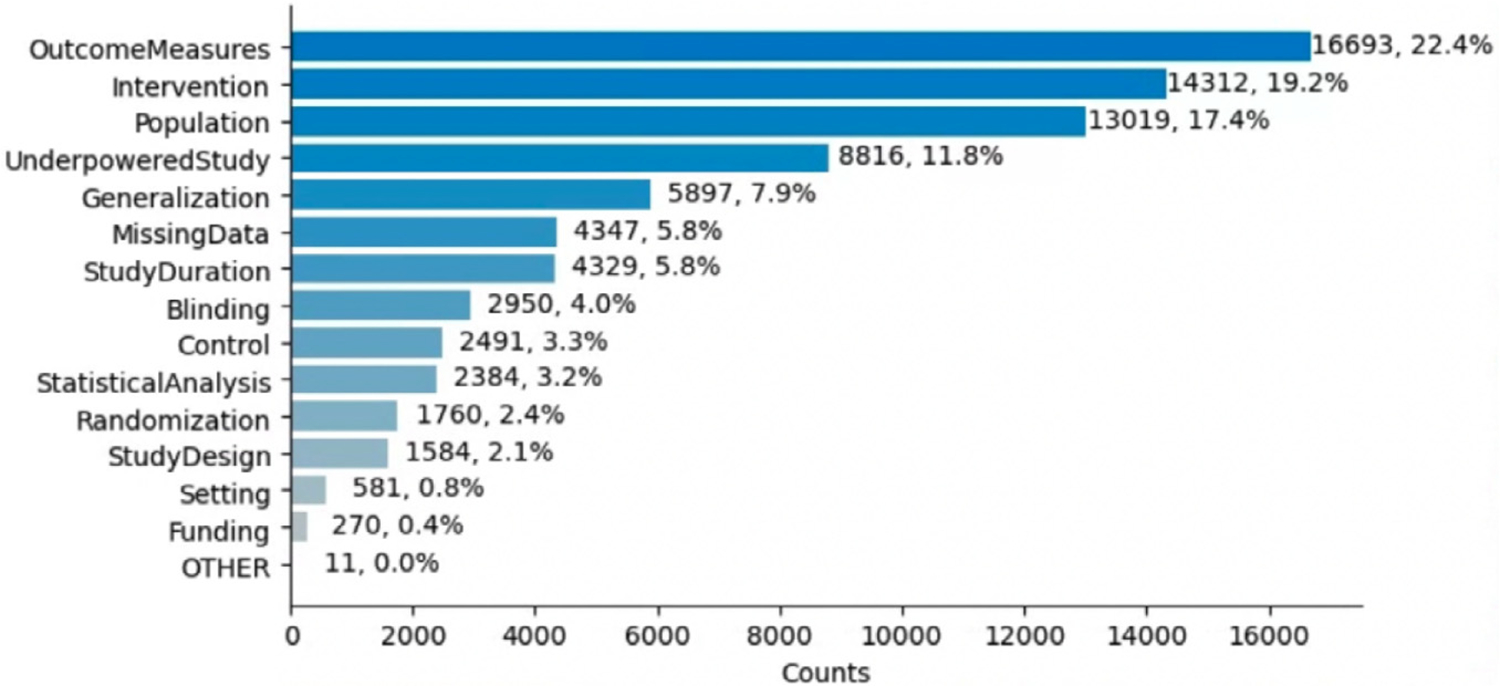
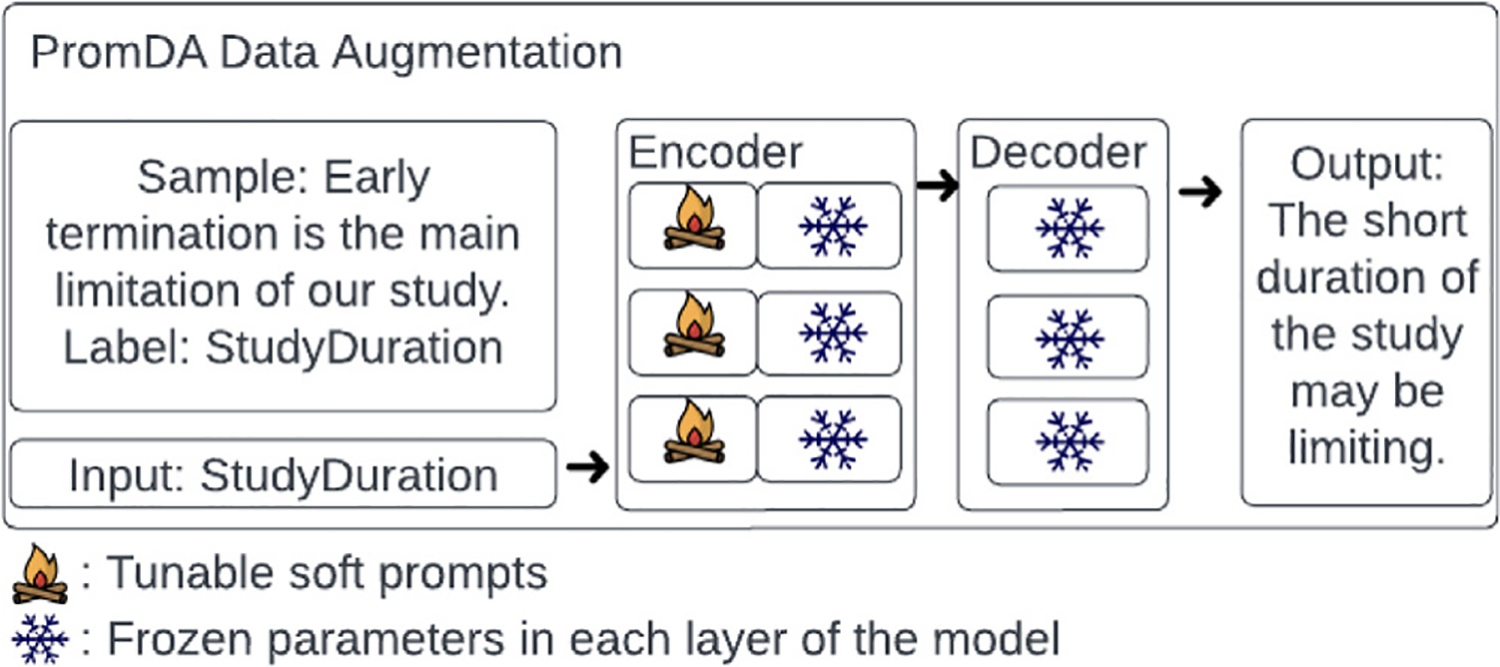
We created a data model of limitation types in RCT studies and annotated a corpus of 200 full-text RCT publications using this data model. We fine-tuned BERT-based sentence classification models to recognize the limitation sentences and their types. To address the small size of the annotated corpus, we experimented with data augmentation approaches, including Easy Data Augmentation (EDA) and Prompt-Based Data Augmentation (PromDA). We applied the best-performing model to a set of about 12K RCT publications to characterize self-acknowledged limitations at larger scale.
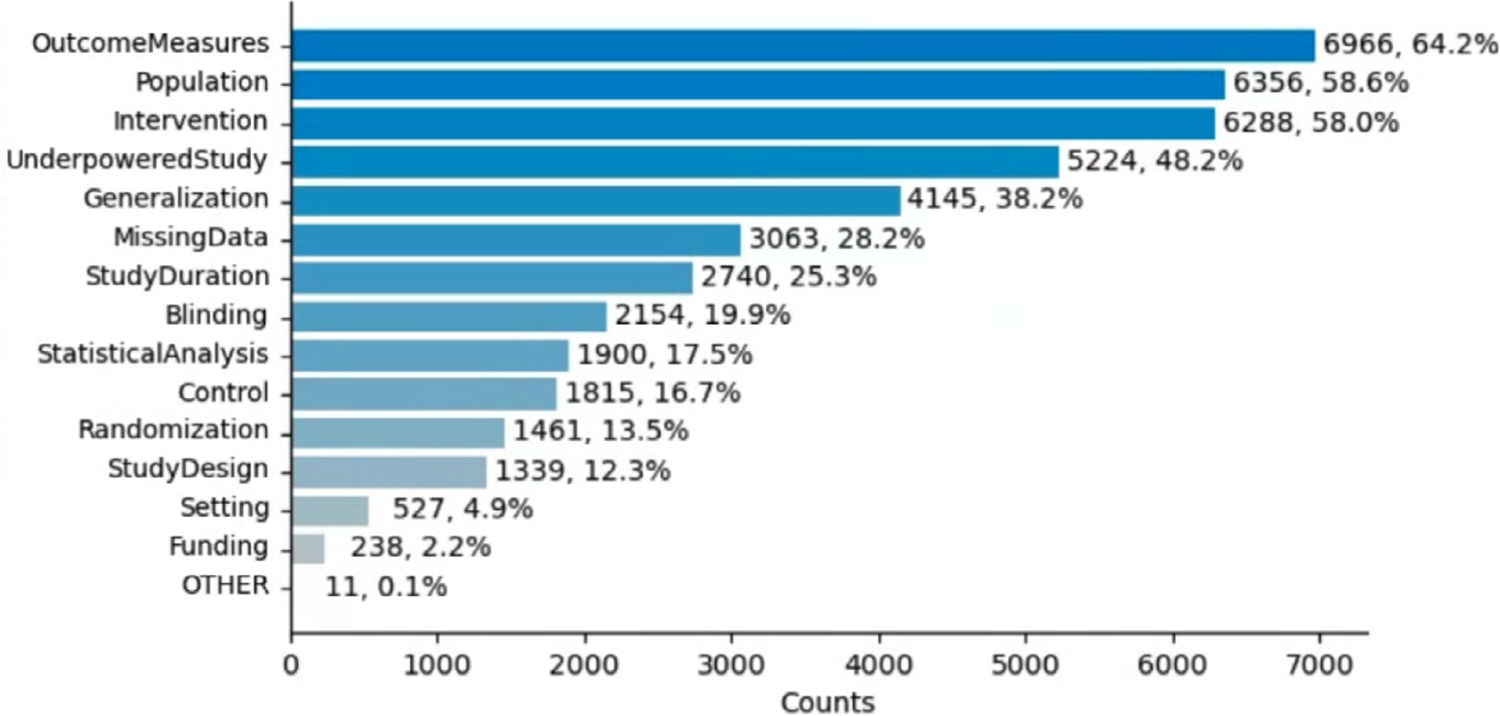
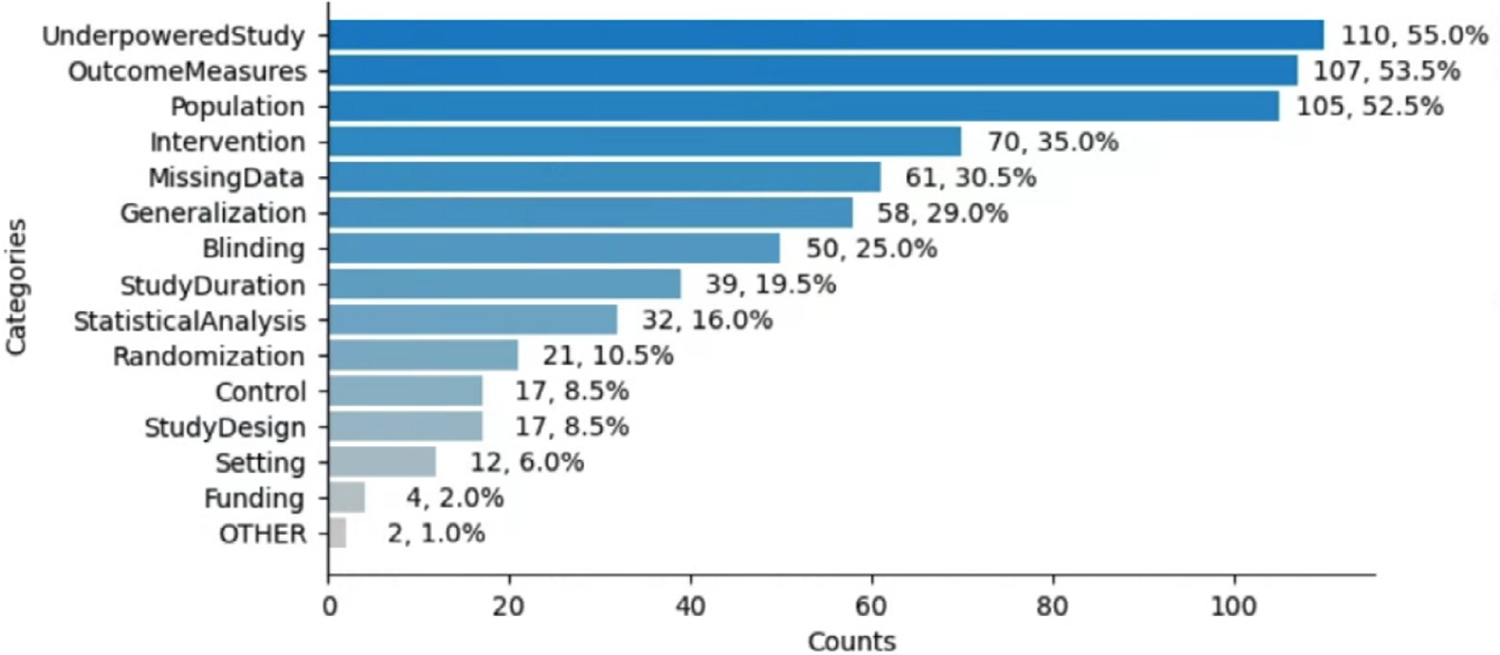
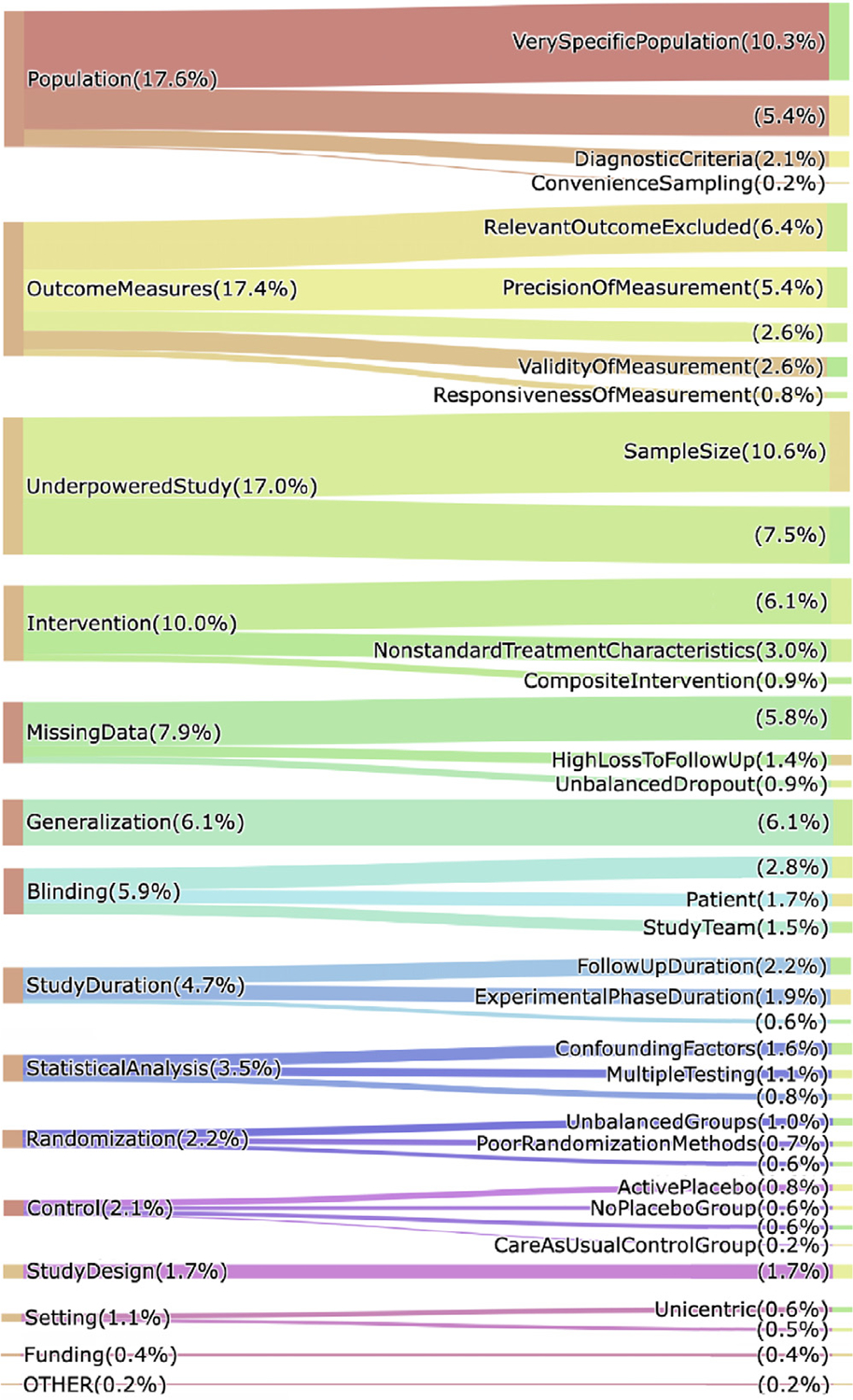
Our data model consists of 15 categories and 24 sub-categories (e.g., Population and its sub-category DiagnosticCriteria). We annotated 1090 instances of limitation types in 952 sentences (4.8 limitation sentences and 5.5 limitation types per article). A fine-tuned PubMedBERT model for limitation sentence classification improved upon our earlier model by about 1.5 absolute percentage points in F score (0.821 vs. 0.8) with statistical significance (p<.001). Our best-performing limitation type classification model, PubMedBERT fine-tuning with PromDA (Output View), achieved an F score of 0.7, improving upon the vanilla PubMedBERT model by 2.7 percentage points, with statistical significance (p<.001).
The model could support automated screening tools which can be used by journals to draw the authors' attention to reporting issues. Automatic extraction of limitations from RCT publications could benefit peer review and evidence synthesis, and support advanced methods to search and aggregate the evidence from the clinical trial literature.
在科学出版物中承认研究局限性是科学透明性和进展的关键要素。然而,局限性报告往往不够充分。自然语言处理(NLP)方法可以支持自动化报告检查,从而提高研究的透明度。在这项研究中,我们的目标是开发一个数据集和 NLP 方法,以检测和分类随机对照试验(RCT)出版物中自我承认的局限性(例如,样本量、盲法)。
我们创建了 RCT 研究中局限性类型的数据模型,并使用该数据模型对 200 篇全文 RCT 出版物进行注释。我们微调了基于 BERT 的句子分类模型,以识别限制句子及其类型。为了解决注释语料库规模较小的问题,我们尝试了数据增强方法,包括简单数据增强(EDA)和基于提示的数据增强(PromDA)。我们将表现最好的模型应用于大约 12K RCT 出版物集,以更大规模地描述自我承认的局限性。
我们的数据模型由 15 个类别和 24 个子类别组成(例如,人群及其子类别诊断标准)。我们在 952 个句子中注释了 1090 个局限性类型实例(每个文章有 4.8 个限制句子和 5.5 个限制类型)。用于限制句子分类的微调 PubMedBERT 模型在 F 分数(0.821 对 0.8)上比我们早期的模型提高了约 1.5 个百分点,具有统计学意义(p<.001)。我们表现最好的局限性类型分类模型,使用 PromDA(Output View)的微调 PubMedBERT,实现了 0.7 的 F 分数,比原始的 PubMedBERT 模型提高了 2.7 个百分点,具有统计学意义(p<.001)。
该模型可以支持自动筛选工具,期刊可以使用这些工具提请作者注意报告问题。从 RCT 出版物中自动提取局限性可以使同行评审和证据综合受益,并支持从临床试验文献中搜索和汇总证据的高级方法。