Schmidt Maria, Hopp Lydia, Arakelyan Arsen, Kirsten Holger, Engel Christoph, Wirkner Kerstin, Krohn Knut, Burkhardt Ralph, Thiery Joachim, Loeffler Markus, Loeffler-Wirth Henry, Binder Hans
IZBI, Interdisciplinary Centre for Bioinformatics, Universität Leipzig, Leipzig, Germany.
BIG, Group of Bioinformatics, Institute of Molecular Biology, National Academy of Sciences, Yerevan, Armenia.
Front Big Data. 2020 Oct 30;3:548873. doi: 10.3389/fdata.2020.548873. eCollection 2020.
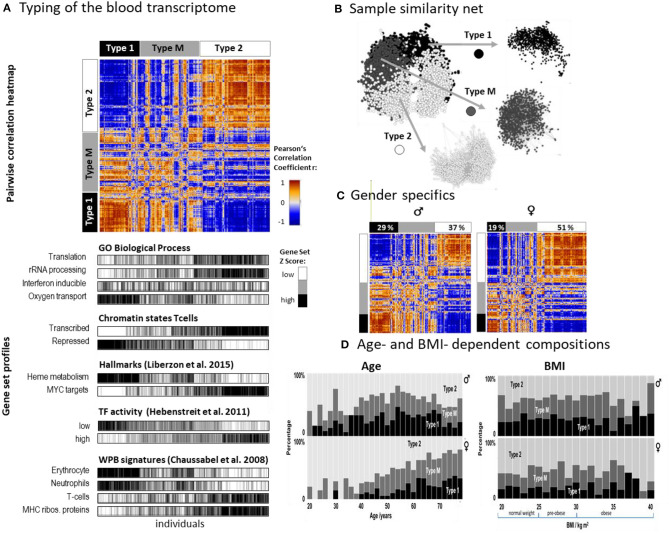
The blood transcriptome is expected to provide a detailed picture of an organism's physiological state with potential outcomes for applications in medical diagnostics and molecular and epidemiological research. We here present the analysis of blood specimens of 3,388 adult individuals, together with phenotype characteristics such as disease history, medication status, lifestyle factors, and body mass index (BMI). The size and heterogeneity of this data challenges analytics in terms of dimension reduction, knowledge mining, feature extraction, and data integration. Self-organizing maps (SOM)-machine learning was applied to study transcriptional states on a population-wide scale. This method permits a detailed description and visualization of the molecular heterogeneity of transcriptomes and of their association with different phenotypic features. The diversity of transcriptomes is described by personalized SOM-portraits, which specify the samples in terms of modules of co-expressed genes of different functional context. We identified two major blood transcriptome types where type 1 was found more in men, the elderly, and overweight people and it upregulated genes associated with inflammation and increased heme metabolism, while type 2 was predominantly found in women, younger, and normal weight participants and it was associated with activated immune responses, transcriptional, ribosomal, mitochondrial, and telomere-maintenance cell-functions. We find a striking overlap of signatures shared by multiple diseases, aging, and obesity driven by an underlying common pattern, which was associated with the immune response and the increase of inflammatory processes. Machine learning applications for large and heterogeneous omics data provide a holistic view on the diversity of the human blood transcriptome. It provides a tool for comparative analyses of transcriptional signatures and of associated phenotypes in population studies and medical applications.
血液转录组有望提供生物体生理状态的详细图景,在医学诊断、分子和流行病学研究中具有潜在应用价值。我们在此展示了对3388名成年人血液样本的分析,以及诸如疾病史、用药情况、生活方式因素和体重指数(BMI)等表型特征。该数据的规模和异质性在降维、知识挖掘、特征提取和数据整合方面对分析提出了挑战。自组织映射(SOM)机器学习被应用于在全人群范围内研究转录状态。这种方法允许对转录组的分子异质性及其与不同表型特征的关联进行详细描述和可视化。转录组的多样性通过个性化的SOM画像来描述,这些画像根据不同功能背景的共表达基因模块来指定样本。我们确定了两种主要的血液转录组类型,其中1型在男性、老年人和超重人群中更为常见,它上调了与炎症和血红素代谢增加相关的基因,而2型主要在女性、年轻人和正常体重参与者中发现,它与激活的免疫反应、转录、核糖体、线粒体和端粒维持细胞功能相关。我们发现多种疾病、衰老和肥胖所共有的特征存在显著重叠,这是由一种潜在的共同模式驱动的,该模式与免疫反应和炎症过程的增加有关。机器学习在大型和异质组学数据中的应用为人类血液转录组的多样性提供了一个整体视角。它为人群研究和医学应用中转录特征及相关表型的比较分析提供了一种工具。