Department of Biostatistics, Epidemiology, and Informatics, University of Pennsylvania, Philadelphia, PA, USA.
Department of Biostatistics, Vanderbilt University, Nashville, TN, USA.
Biom J. 2021 Jun;63(5):1006-1027. doi: 10.1002/bimj.202000187. Epub 2021 Mar 11.
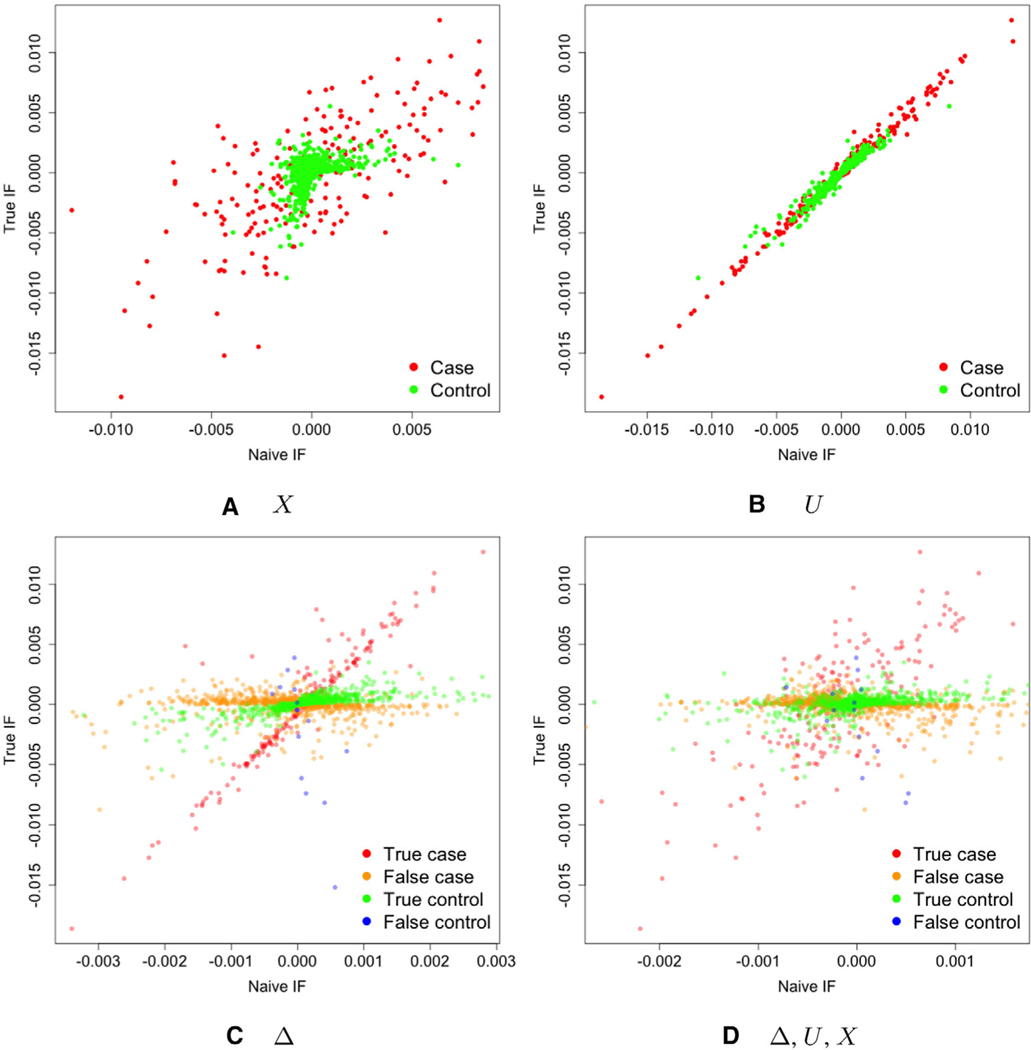
Biomedical studies that use electronic health records (EHR) data for inference are often subject to bias due to measurement error. The measurement error present in EHR data is typically complex, consisting of errors of unknown functional form in covariates and the outcome, which can be dependent. To address the bias resulting from such errors, generalized raking has recently been proposed as a robust method that yields consistent estimates without the need to model the error structure. We provide rationale for why these previously proposed raking estimators can be expected to be inefficient in failure-time outcome settings involving misclassification of the event indicator. We propose raking estimators that utilize multiple imputation, to impute either the target variables or auxiliary variables, to improve the efficiency. We also consider outcome-dependent sampling designs and investigate their impact on the efficiency of the raking estimators, either with or without multiple imputation. We present an extensive numerical study to examine the performance of the proposed estimators across various measurement error settings. We then apply the proposed methods to our motivating setting, in which we seek to analyze HIV outcomes in an observational cohort with EHR data from the Vanderbilt Comprehensive Care Clinic.
生物医学研究经常会受到电子健康记录 (EHR) 数据推断中的测量误差的影响。EHR 数据中的测量误差通常很复杂,包括协变量和结果中未知函数形式的误差,并且这些误差可能是相关的。为了解决这些误差引起的偏差,最近提出了广义耙式估计法作为一种稳健的方法,它可以在不需要对误差结构进行建模的情况下得到一致的估计值。我们提供了为什么在涉及事件指标错误分类的失效时间结果设置中,这些之前提出的耙式估计量可能效率低下的原因。我们提出了利用多重插补的耙式估计量,以插补目标变量或辅助变量,以提高效率。我们还考虑了依赖于结果的抽样设计,并研究了它们对耙式估计量效率的影响,无论是有还是没有多重插补。我们进行了广泛的数值研究,以检查各种测量误差设置下提出的估计量的性能。然后,我们将提出的方法应用于我们的动机设置,我们试图在范德比尔特综合护理诊所的 EHR 数据中分析观察队列中的 HIV 结果。