Dept. of Computer Science and Engineering, Indian Institute of Technology Patna, Patna, Bihar, India.
Accenture Labs, Banglore, Karnataka, India.
PLoS One. 2021 Apr 1;16(4):e0249030. doi: 10.1371/journal.pone.0249030. eCollection 2021.
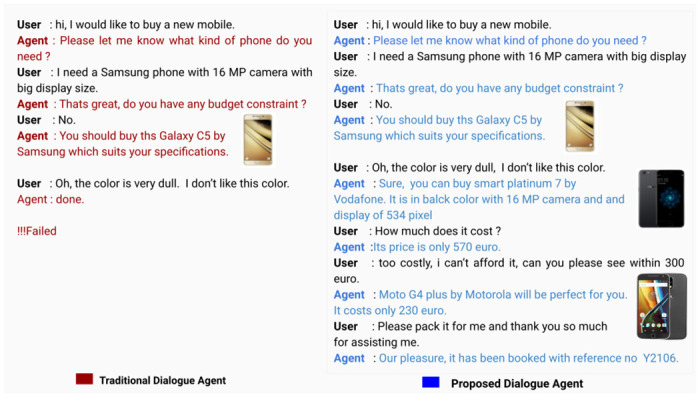
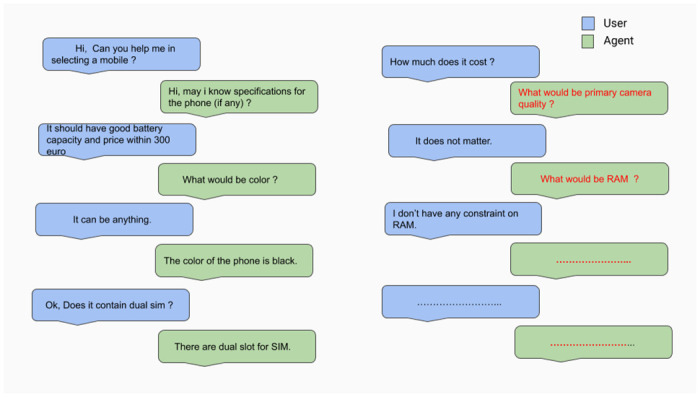
Existing virtual agents (VAs) present in dialogue systems are either information retrieval based or static goal-driven. However, in real-world situations, end-users might not have a known and fixed goal beforehand for the task, i.e., they may upgrade/downgrade/update their goal components in real-time to maximize their utility values. Existing VAs are unable to handle such dynamic goal-oriented situations.
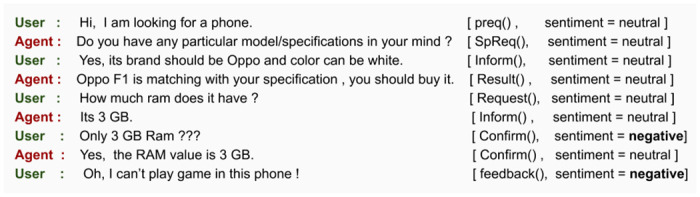
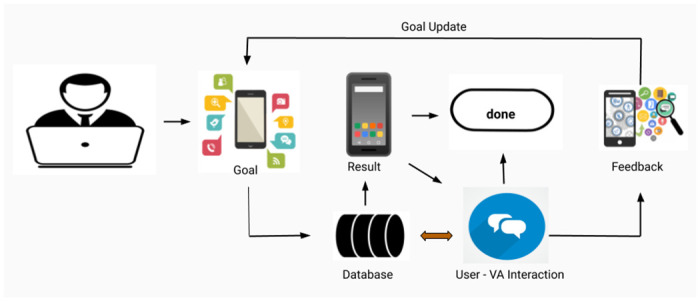
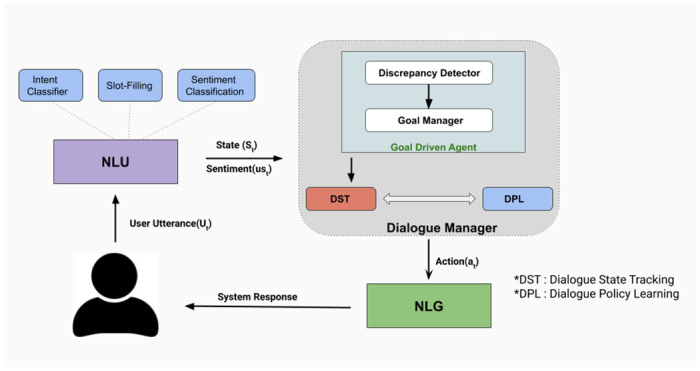
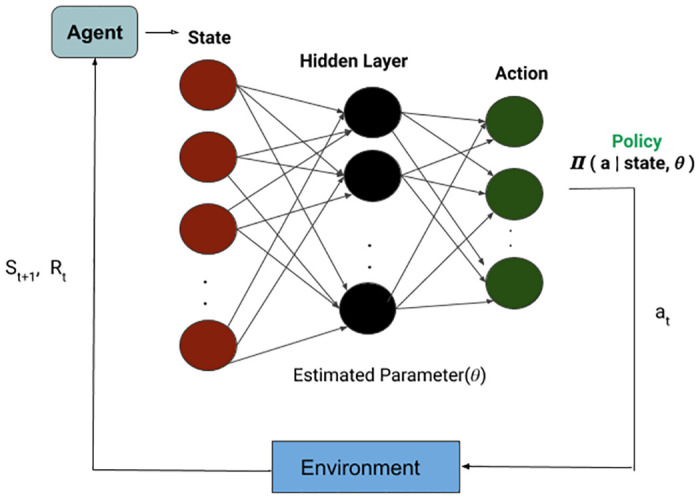
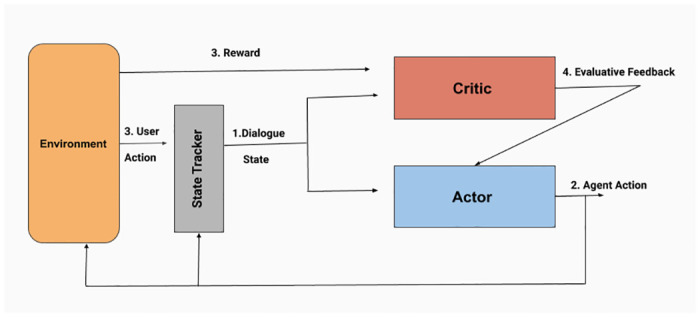
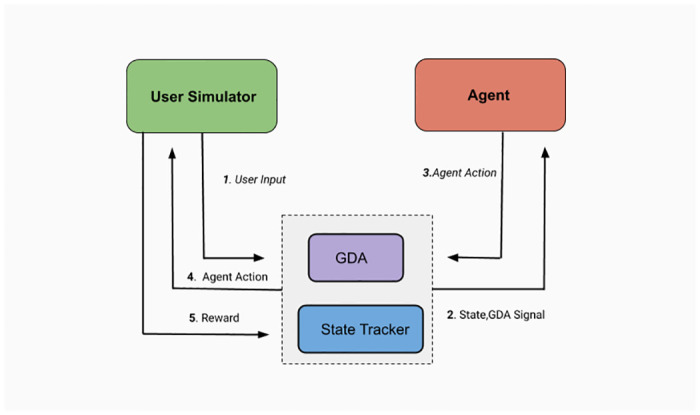
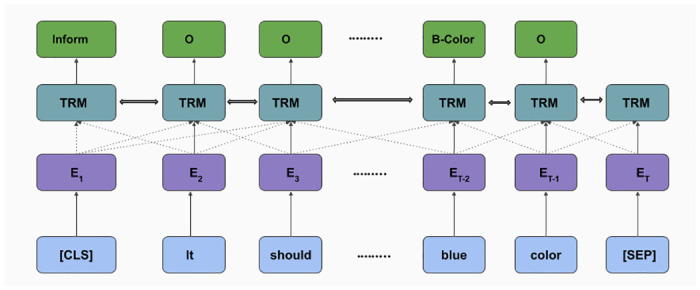
Due to the absence of any related dialogue dataset where such choice deviations are present, we have created a conversational dataset called Deviation adapted Virtual Agent(DevVA), with the manual annotation of its corresponding intents, slots, and sentiment labels. A Dynamic Goal Driven Dialogue Agent (DGDVA) has been developed by incorporating a Dynamic Goal Driven Module (GDM) on top of a deep reinforcement learning based dialogue manager. In the course of a conversation, the user sentiment provides grounded feedback about agent behavior, including goal serving action. User sentiment appears to be an appropriate indicator for goal discrepancy that guides the agent to complete the user's desired task with gratification. The negative sentiment expressed by the user about an aspect of the provided choice is treated as a discrepancy that is being resolved by the GDM depending upon the observed discrepancy and current dialogue state. The goal update capability and the VA's interactiveness trait enable end-users to accomplish their desired task satisfactorily.
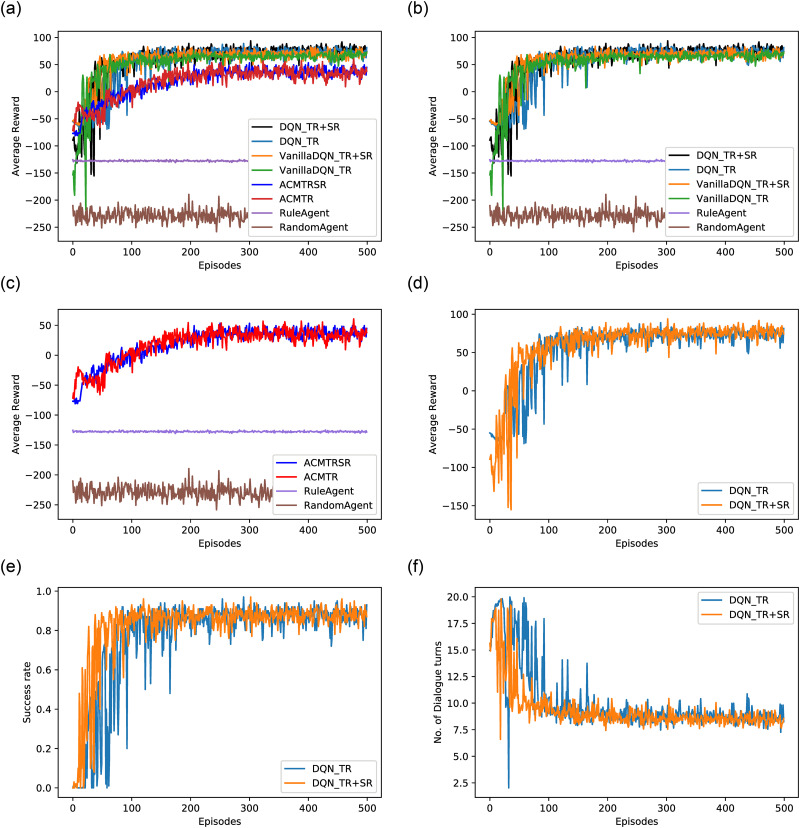
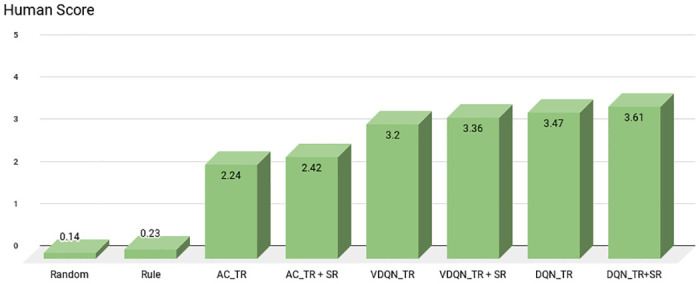
The obtained experimental results illustrate that DGDVA can handle dynamic goals with maximum user satisfaction and a significantly higher success rate. The interaction drives the user to decide its final goal through the latent specification of possible choices and information retrieved and provided by the dialogue agent. Through the experimental results (qualitative and quantitative), we firmly conclude that the proposed sentiment-aware VA adapts users' dynamic behavior for its goal setting with substantial efficacy in terms of primary objective i.e., task success rate (0.88).
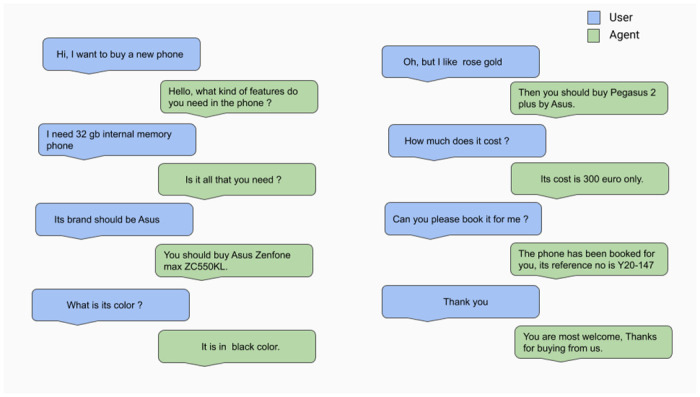
In real world, it can be argued that many people do not have a predefined and fixed goal for tasks such as online shopping, movie booking & restaurant booking, etc. They tend to explore the available options first which are aligned with their minimum requirements and then decide one amongst them. The DGDVA provides maximum user satisfaction as it enables them to accomplish a dynamic goal that leads to additional utilities along with the essential ones.
To the best of our knowledge, this is the first effort towards the development of A Dynamic Goal Adapted Task-Oriented Dialogue Agent that can serve user goals dynamically until the user is satisfied.
现有的对话系统中的虚拟代理(VA)要么是基于信息检索的,要么是静态目标驱动的。然而,在现实世界的情况下,终端用户可能事先没有一个已知的、固定的任务目标,也就是说,他们可能会实时升级/降级/更新他们的目标组件,以最大化他们的效用值。现有的 VA 无法处理这种动态目标导向的情况。
由于没有任何包含这种选择偏差的相关对话数据集,我们创建了一个名为 Deviation adapted Virtual Agent(DevVA)的对话数据集,其中包含了其对应意图、插槽和情感标签的手动注释。通过在基于深度强化学习的对话管理器之上集成一个动态目标驱动模块(GDM),开发了一个动态目标驱动的对话代理(DGDVA)。在对话过程中,用户情感为代理行为提供了基于情境的反馈,包括目标服务行为。用户情感似乎是目标差异的一个合适指标,它指导代理以满意的方式完成用户的期望任务。用户对提供的选择的某个方面表达的负面情绪被视为一种差异,GDM 将根据观察到的差异和当前对话状态来解决这种差异。目标更新能力和 VA 的交互性特征使最终用户能够满意地完成他们期望的任务。
实验结果表明,DGDVA 可以在最大用户满意度和显著更高的成功率的情况下处理动态目标。交互通过潜在的可能选择规范以及对话代理检索和提供的信息来驱动用户决定其最终目标。通过实验结果(定性和定量),我们坚定地得出结论,所提出的情感感知 VA 通过其在主要目标(即任务成功率(0.88)方面的目标设置中适应用户的动态行为,具有显著的功效。
在现实世界中,可以说许多人对在线购物、电影预订和餐厅预订等任务没有预先设定和固定的目标。他们倾向于首先探索可用的选项,这些选项与他们的最低要求相匹配,然后从中选择一个。DGDVA 提供了最大的用户满意度,因为它允许他们完成一个动态目标,从而带来额外的效用,以及基本的效用。
据我们所知,这是第一个开发动态目标适应任务导向的对话代理的努力,它可以在用户满意之前动态地为用户服务目标。