Connected and Autonomous Vehicles Lab, University of Surrey, Guildford GU2 7XH, UK.
Centre for Vision Speech and Signal Processing, University of Surrey, Guildford GU2 7XH, UK.
Sensors (Basel). 2021 Mar 13;21(6):2032. doi: 10.3390/s21062032.
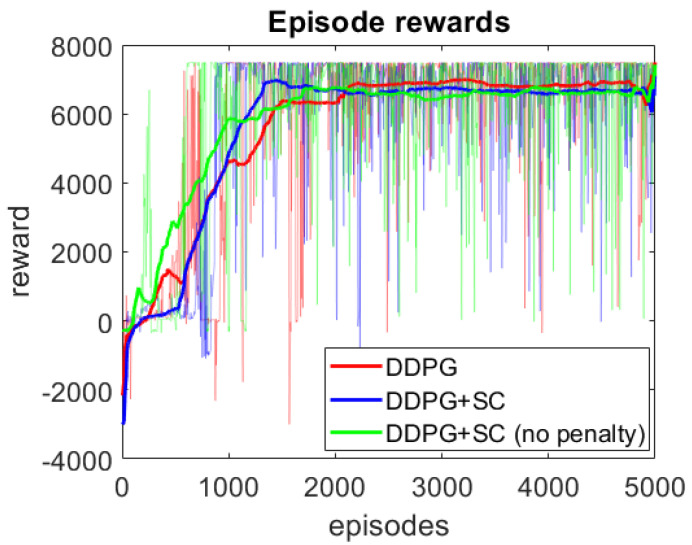
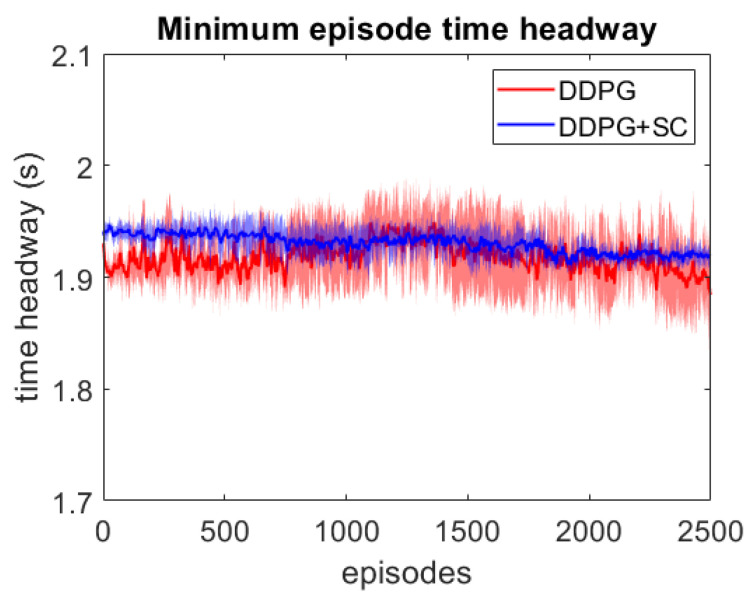
The use of neural networks and reinforcement learning has become increasingly popular in autonomous vehicle control. However, the opaqueness of the resulting control policies presents a significant barrier to deploying neural network-based control in autonomous vehicles. In this paper, we present a reinforcement learning based approach to autonomous vehicle longitudinal control, where the rule-based safety cages provide enhanced safety for the vehicle as well as weak supervision to the reinforcement learning agent. By guiding the agent to meaningful states and actions, this weak supervision improves the convergence during training and enhances the safety of the final trained policy. This rule-based supervisory controller has the further advantage of being fully interpretable, thereby enabling traditional validation and verification approaches to ensure the safety of the vehicle. We compare models with and without safety cages, as well as models with optimal and constrained model parameters, and show that the weak supervision consistently improves the safety of exploration, speed of convergence, and model performance. Additionally, we show that when the model parameters are constrained or sub-optimal, the safety cages can enable a model to learn a safe driving policy even when the model could not be trained to drive through reinforcement learning alone.
神经网络和强化学习在自动驾驶控制中的应用变得越来越流行。然而,由此产生的控制策略的不透明性对在自动驾驶汽车中部署基于神经网络的控制提出了重大挑战。在本文中,我们提出了一种基于强化学习的自动驾驶汽车纵向控制方法,其中基于规则的安全笼为车辆提供了增强的安全性以及对强化学习代理的弱监督。通过引导代理进入有意义的状态和动作,这种弱监督可以在训练过程中提高收敛速度,并增强最终训练策略的安全性。这种基于规则的监督控制器具有完全可解释的优点,从而能够采用传统的验证和确认方法来确保车辆的安全性。我们比较了有无安全笼的模型、具有最优和约束模型参数的模型,并表明弱监督始终可以提高探索的安全性、收敛速度和模型性能。此外,我们还表明,当模型参数受到约束或次优时,安全笼可以使模型即使在仅通过强化学习无法训练出安全驾驶策略的情况下,也能够学习到安全的驾驶策略。