Saeed Mozamel M, Al Aghbari Zaher, Alsharidah Mohammed
Department of Computer Science, Prince Sattam Bin Abdul Aziz, Riyadh, Saudi Arabia.
Department of Computer Science, University of Sharjah, Sharjah, United Arab Emirates.
PeerJ Comput Sci. 2020 Nov 30;6:e321. doi: 10.7717/peerj-cs.321. eCollection 2020.
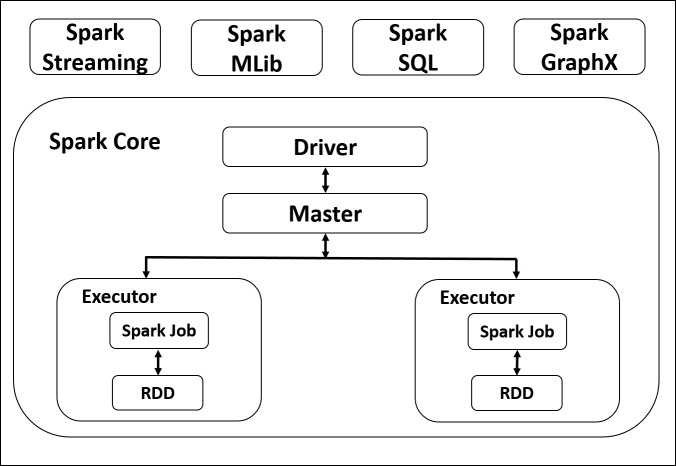
A popular unsupervised learning method, known as clustering, is extensively used in data mining, machine learning and pattern recognition. The procedure involves grouping of single and distinct points in a group in such a way that they are either similar to each other or dissimilar to points of other clusters. Traditional clustering methods are greatly challenged by the recent massive growth of data. Therefore, several research works proposed novel designs for clustering methods that leverage the benefits of Big Data platforms, such as Apache Spark, which is designed for fast and distributed massive data processing. However, Spark-based clustering research is still in its early days. In this systematic survey, we investigate the existing Spark-based clustering methods in terms of their support to the characteristics Big Data. Moreover, we propose a new taxonomy for the Spark-based clustering methods. To the best of our knowledge, no survey has been conducted on Spark-based clustering of Big Data. Therefore, this survey aims to present a comprehensive summary of the previous studies in the field of Big Data clustering using Apache Spark during the span of 2010-2020. This survey also highlights the new research directions in the field of clustering massive data.
一种广为人知的无监督学习方法——聚类,在数据挖掘、机器学习和模式识别中被广泛使用。该过程涉及将单个且不同的点分组到一个组中,使得它们彼此相似或与其他簇中的点不同。传统的聚类方法受到近期数据大量增长的巨大挑战。因此,一些研究工作提出了新颖的聚类方法设计,利用大数据平台(如为快速分布式海量数据处理而设计的Apache Spark)的优势。然而,基于Spark的聚类研究仍处于早期阶段。在这项系统综述中,我们从对大数据特征的支持方面研究了现有的基于Spark的聚类方法。此外,我们为基于Spark的聚类方法提出了一种新的分类法。据我们所知,尚未对基于Spark的大数据聚类进行过综述。因此,本综述旨在全面总结2010年至2020年期间使用Apache Spark进行大数据聚类领域的先前研究。本综述还突出了海量数据聚类领域的新研究方向。