Díaz Gabriel, Peralta Billy, Caro Luis, Nicolis Orietta
Departamento de Ciencias de Ingeniería, Facultad de Ingeniería, Universidad Andres Bello, Antonio Varas 880, 8370146 Santiago, Chile.
Departamento de Ingeniería Informática, Facultad de Ingeniería, Universidad Católica de Temuco, Rudecindo Ortega 2950, 4781312 Temuco, Chile.
Entropy (Basel). 2021 Apr 1;23(4):423. doi: 10.3390/e23040423.
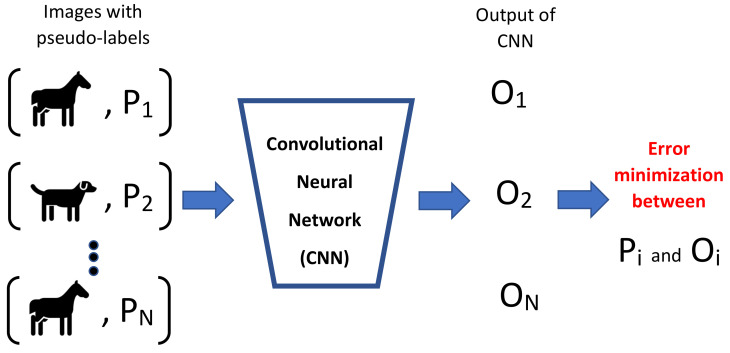
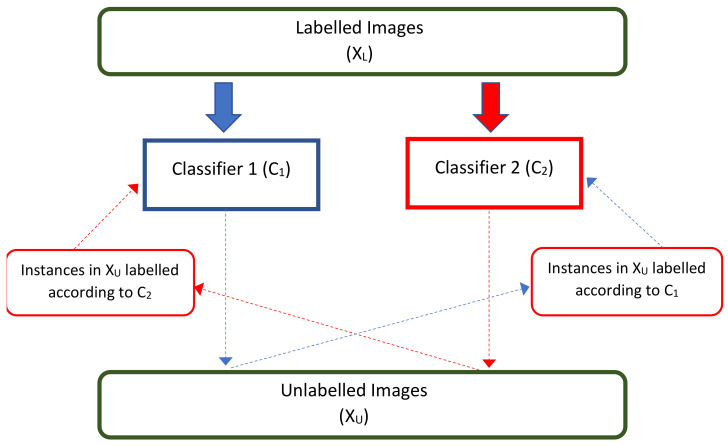
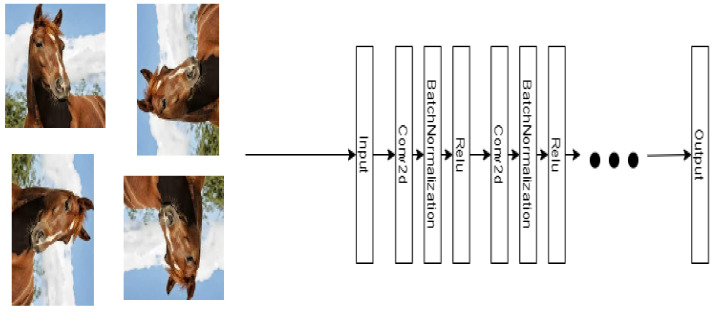
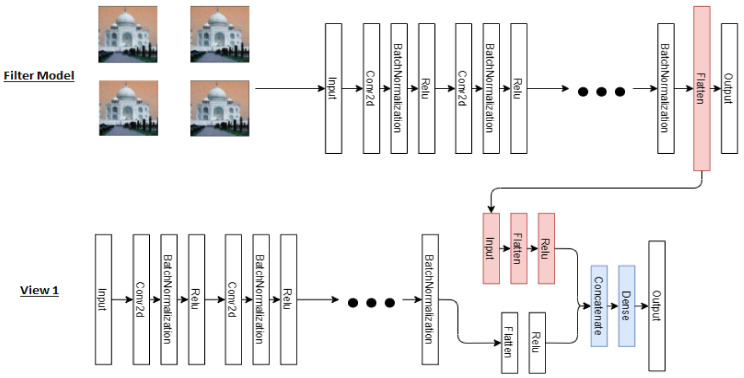
Automatic recognition of visual objects using a deep learning approach has been successfully applied to multiple areas. However, deep learning techniques require a large amount of labeled data, which is usually expensive to obtain. An alternative is to use semi-supervised models, such as co-training, where multiple complementary views are combined using a small amount of labeled data. A simple way to associate views to visual objects is through the application of a degree of rotation or a type of filter. In this work, we propose a co-training model for visual object recognition using deep neural networks by adding layers of self-supervised neural networks as intermediate inputs to the views, where the views are diversified through the cross-entropy regularization of their outputs. Since the model merges the concepts of co-training and self-supervised learning by considering the differentiation of outputs, we called it Differential Self-Supervised Co-Training (DSSCo-Training). This paper presents some experiments using the DSSCo-Training model to well-known image datasets such as MNIST, CIFAR-100, and SVHN. The results indicate that the proposed model is competitive with the state-of-art models and shows an average relative improvement of 5% in accuracy for several datasets, despite its greater simplicity with respect to more recent approaches.
使用深度学习方法自动识别视觉对象已成功应用于多个领域。然而,深度学习技术需要大量的标注数据,而获取这些数据通常成本很高。一种替代方法是使用半监督模型,如协同训练,即使用少量标注数据来组合多个互补视图。将视图与视觉对象相关联的一种简单方法是通过应用一定程度的旋转或某种类型的滤波器。在这项工作中,我们提出了一种用于视觉对象识别的协同训练模型,该模型使用深度神经网络,通过添加自监督神经网络层作为视图的中间输入,其中视图通过其输出的交叉熵正则化实现多样化。由于该模型通过考虑输出的差异融合了协同训练和自监督学习的概念,我们将其称为差分自监督协同训练(DSSCo-Training)。本文展示了一些使用DSSCo-Training模型对MNIST、CIFAR-100和SVHN等知名图像数据集进行的实验。结果表明,所提出的模型与当前最先进的模型具有竞争力,并且在几个数据集上的准确率平均相对提高了5%,尽管相对于最新方法它更为简单。