Department of Biostatistics, Johns Hopkins University, Baltimore, MD, United States.
Department of Biostatistics, Johns Hopkins University, Baltimore, MD, United States.
Neuroimage. 2021 Aug 15;237:118141. doi: 10.1016/j.neuroimage.2021.118141. Epub 2021 May 4.
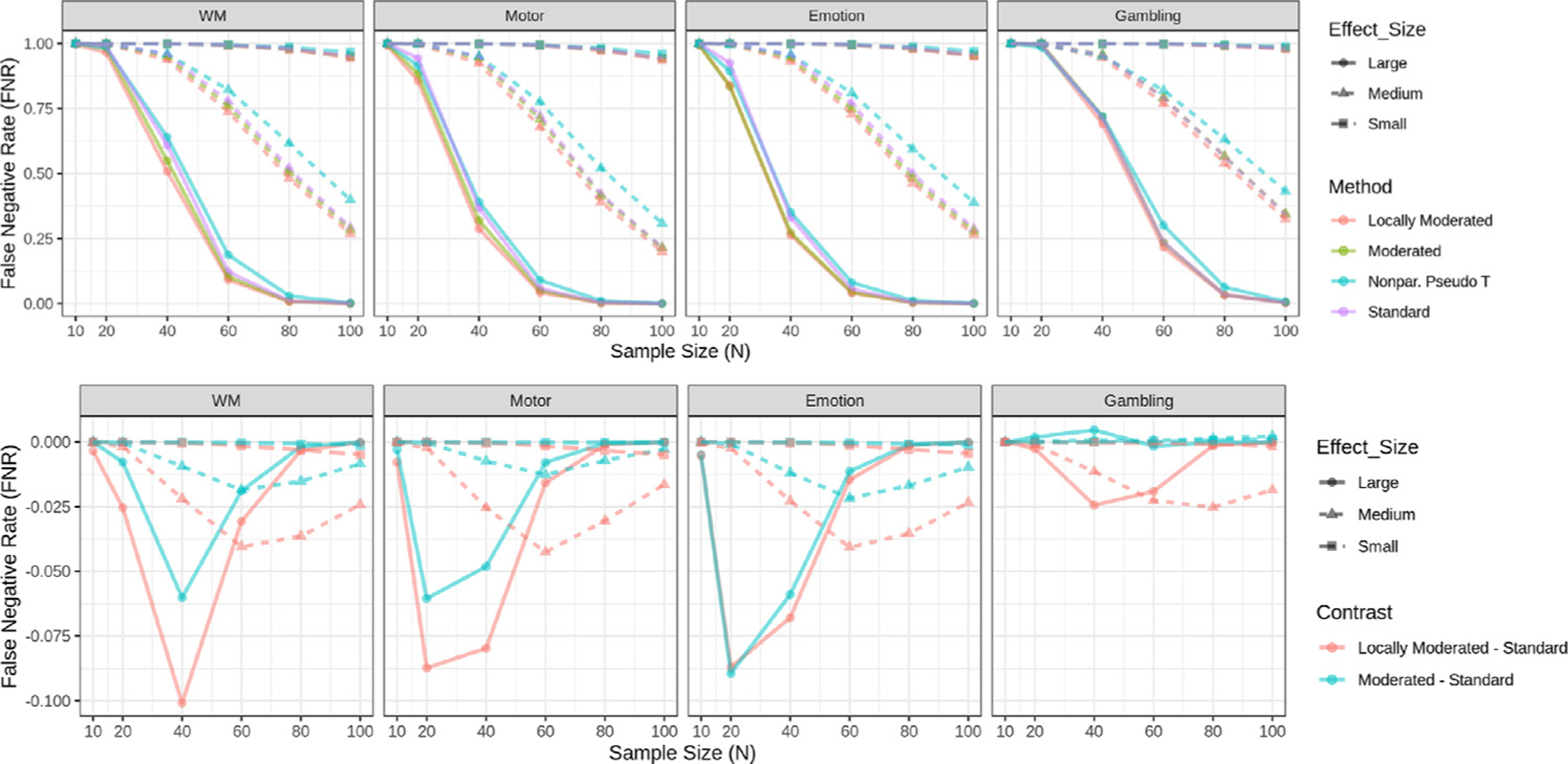
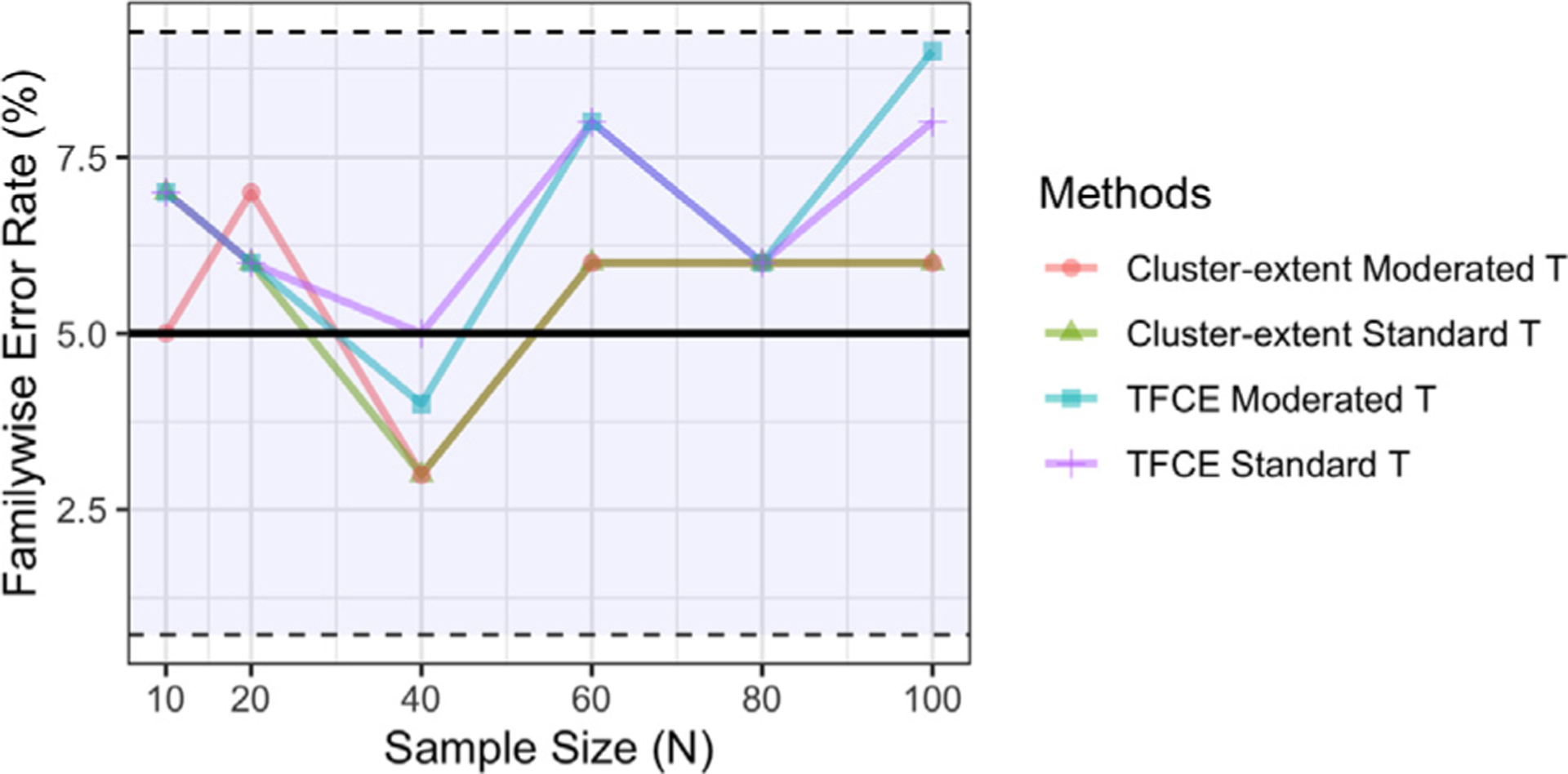
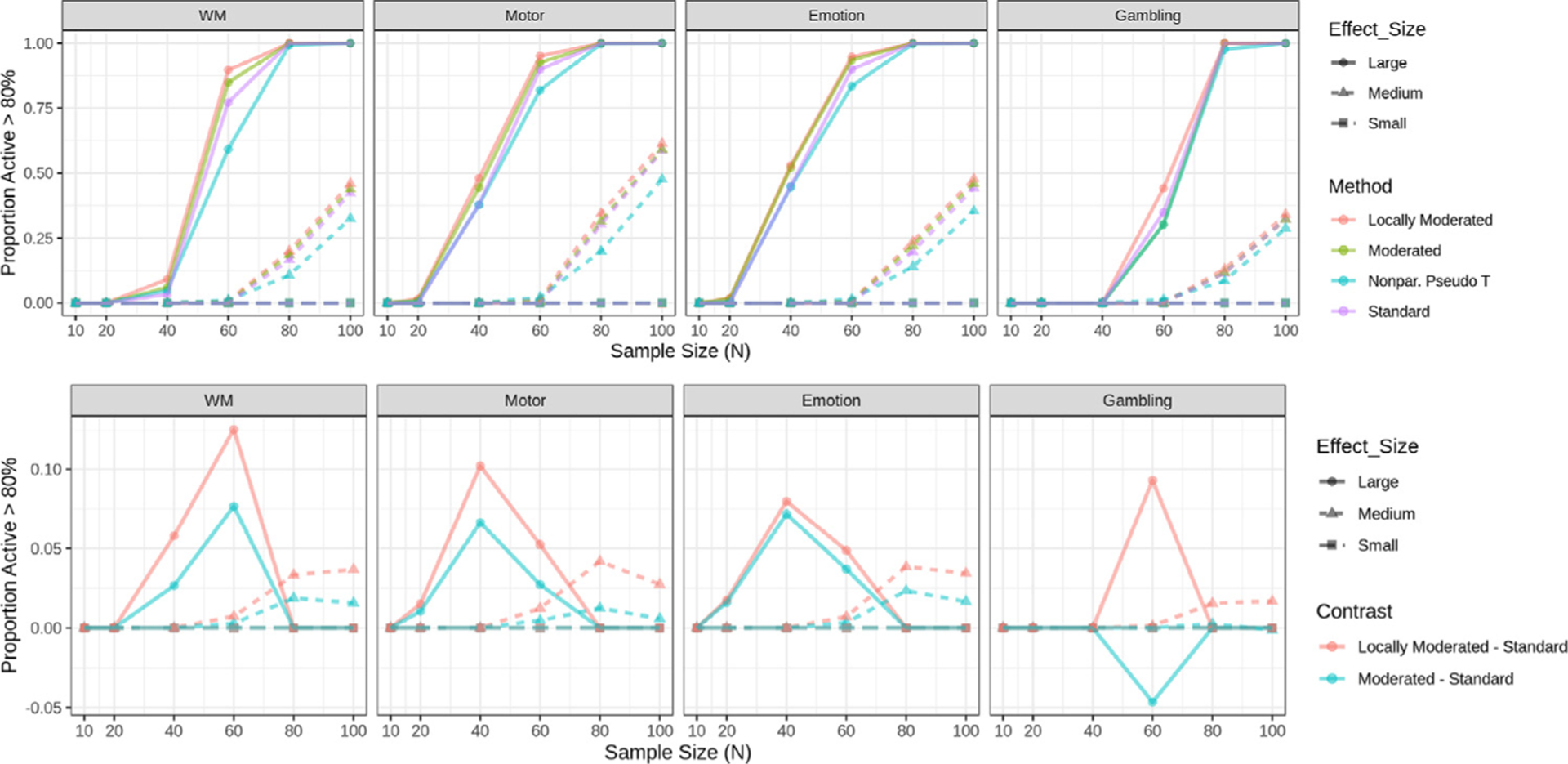
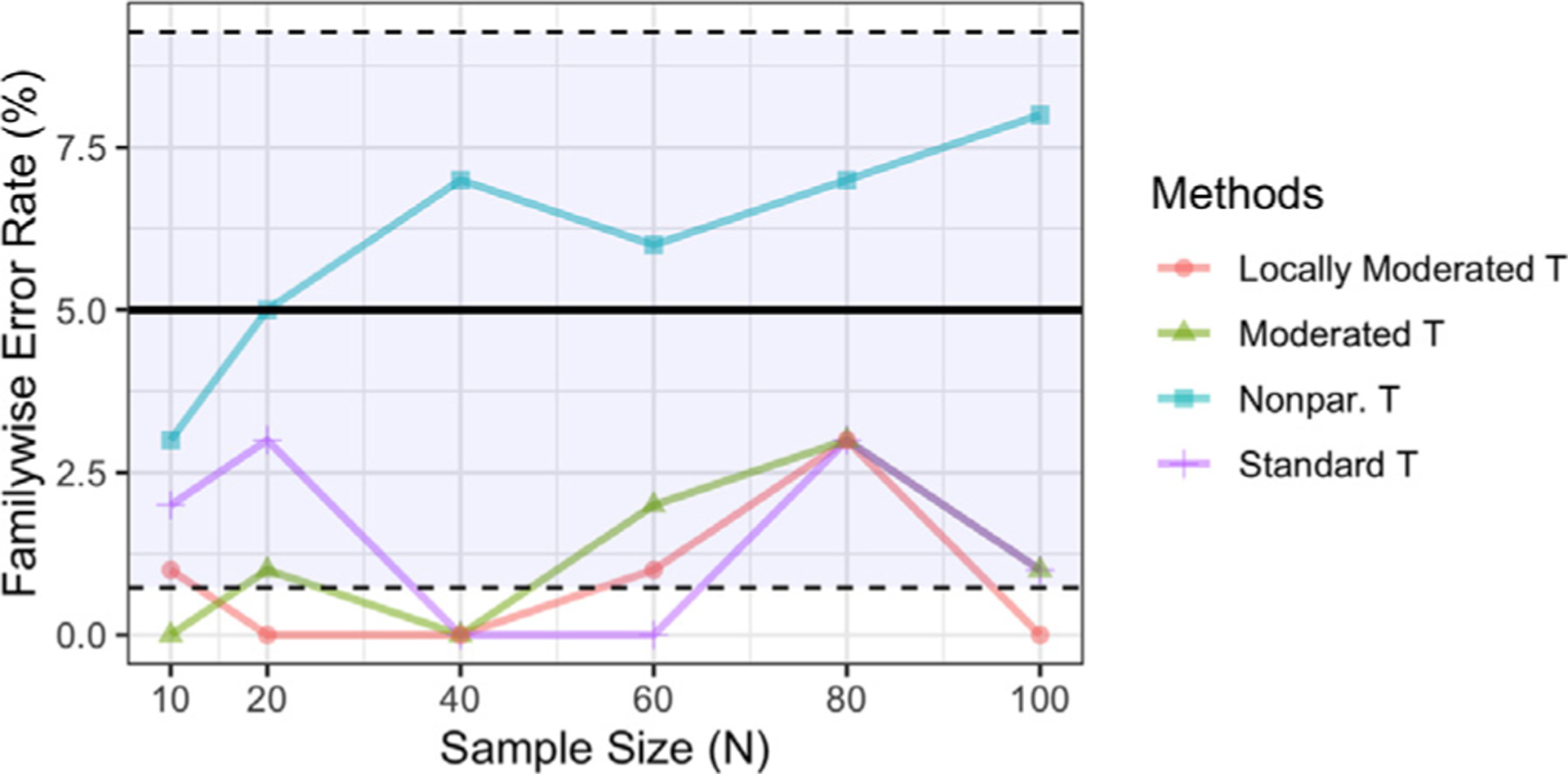
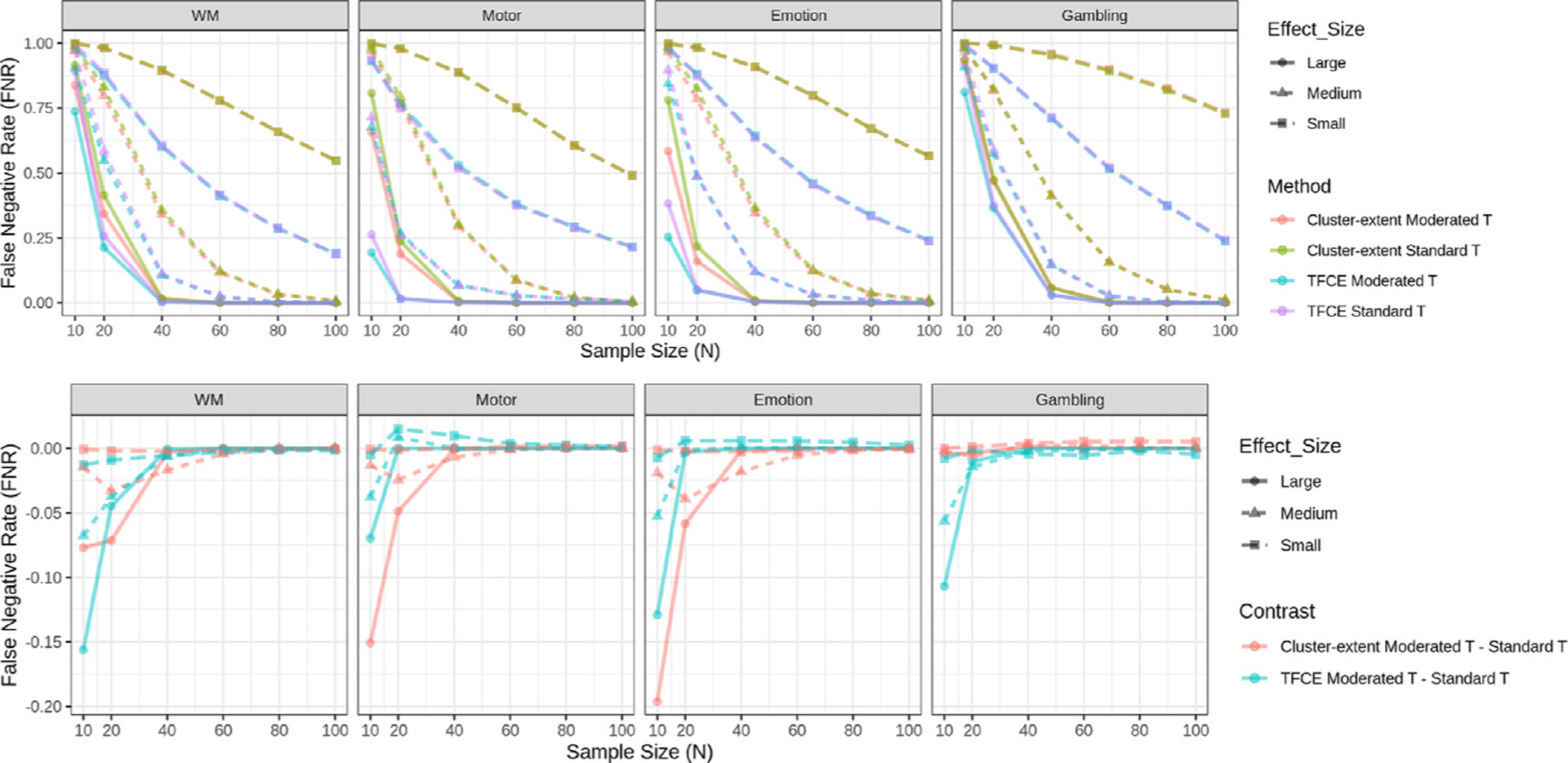
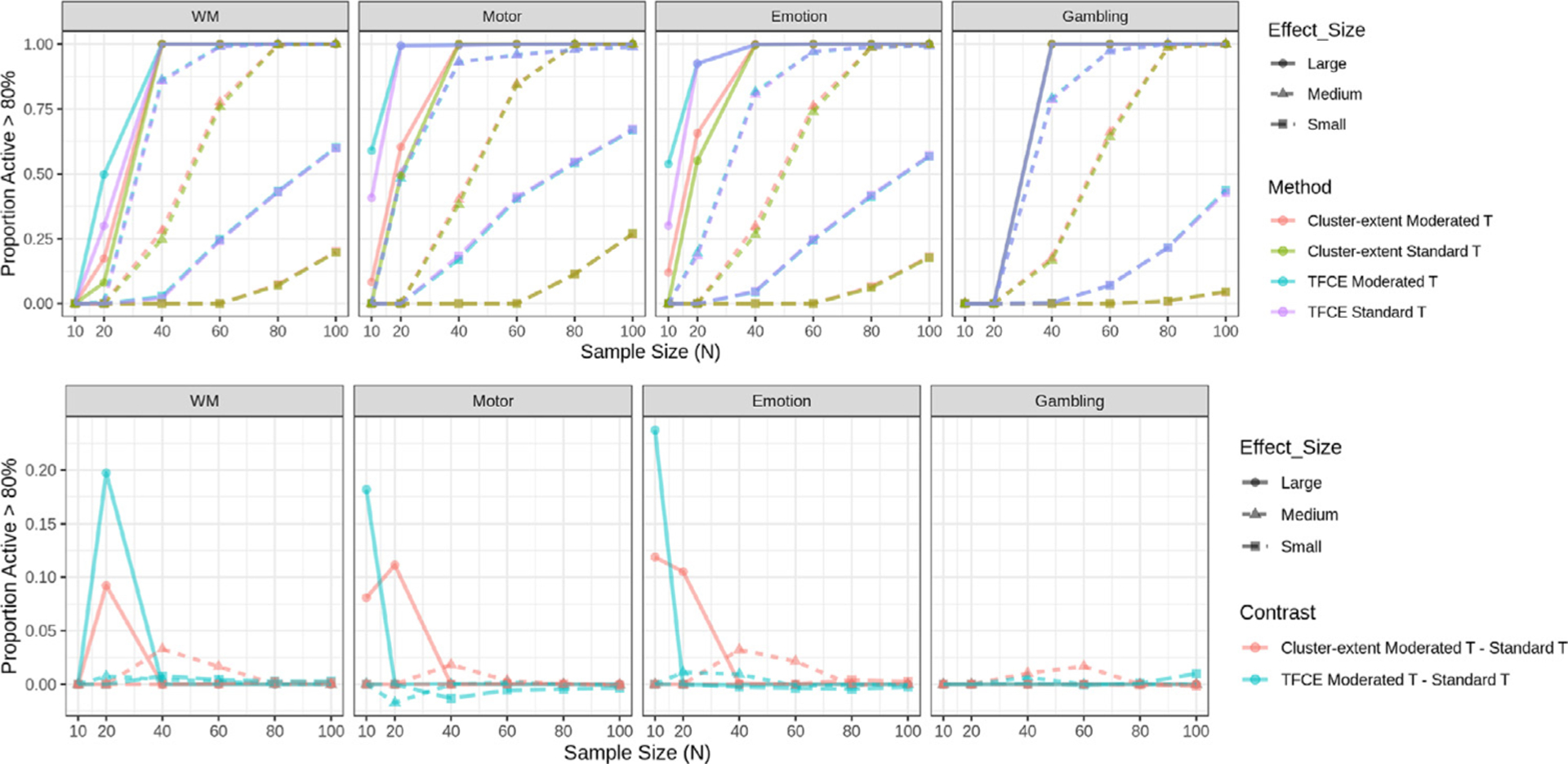
In recent years, there has been significant criticism of functional magnetic resonance imaging (fMRI) studies with small sample sizes. The argument is that such studies have low statistical power, as well as reduced likelihood for statistically significant results to be true effects. The prevalence of these studies has led to a situation where a large number of published results are not replicable and likely false. Despite this growing body of evidence, small sample fMRI studies continue to be regularly performed; likely due to the high cost of scanning. In this report we investigate the use of a moderated t-statistic for performing group-level fMRI analysis to help alleviate problems related to small sample sizes. The proposed approach, implemented in the popular R-package LIMMA (linear models for microarray data), has found wide usage in the genomics literature for dealing with similar issues. Utilizing task-based fMRI data from the Human Connectome Project (HCP), we compare the performance of the moderated t-statistic with the standard t-statistic, as well as the pseudo t-statistic commonly used in non-parametric fMRI analysis. We find that the moderated t-test significantly outperforms both alternative approaches for studies with sample sizes less than 40 subjects. Further, we find that the results were consistent both when using voxel-based and cluster-based thresholding. We also introduce an R-package, LIMMI (linear models for medical images), that provides a quick and convenient way to apply the method to fMRI data.
近年来,针对小样本量的功能磁共振成像(fMRI)研究,出现了大量的批评意见。这些研究的统计功效较低,且统计上显著的结果更有可能是虚假效应,因此人们认为这些研究的可信度较低。这些研究的普遍存在导致了大量已发表的结果不可复制,并且很可能是错误的。尽管有越来越多的证据表明,小样本 fMRI 研究仍在定期进行;这可能是由于扫描成本高昂所致。在本报告中,我们研究了使用经过修正的 t 统计量进行组水平 fMRI 分析,以帮助缓解与小样本量相关的问题。该方法在基因组学文献中得到了广泛应用,用于处理类似问题,它是在流行的 R 包 LIMMA(用于微阵列数据的线性模型)中实现的。我们利用人类连接组计划(HCP)的基于任务的 fMRI 数据,将经过修正的 t 统计量与标准 t 统计量以及常用于非参数 fMRI 分析的伪 t 统计量进行了比较。我们发现,对于样本量小于 40 个的研究,修正 t 检验明显优于其他两种方法。此外,当使用体素和基于聚类的阈值方法时,结果都是一致的。我们还引入了一个 R 包 LIMMI(用于医学图像的线性模型),它提供了一种快速方便的方法,将该方法应用于 fMRI 数据。