Cortés-Ibañez Francisco O, Belur Nagaraj Sunil, Cornelissen Ludo, Sidorenkov Grigory, de Bock Geertruida H
Department of Epidemiology, University Medical Center Groningen, University of Groningen, 9713 GZ Groningen, The Netherlands.
Department of Clinical Pharmacy & Pharmacology, University Medical Center Groningen, University of Groningen, 9713 GZ Groningen, The Netherlands.
Cancers (Basel). 2021 May 12;13(10):2335. doi: 10.3390/cancers13102335.
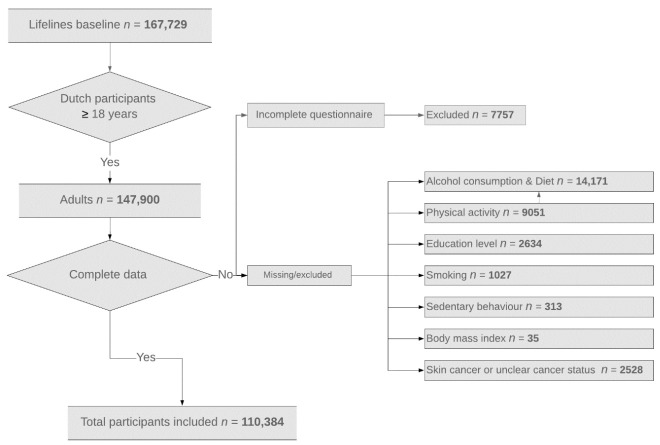
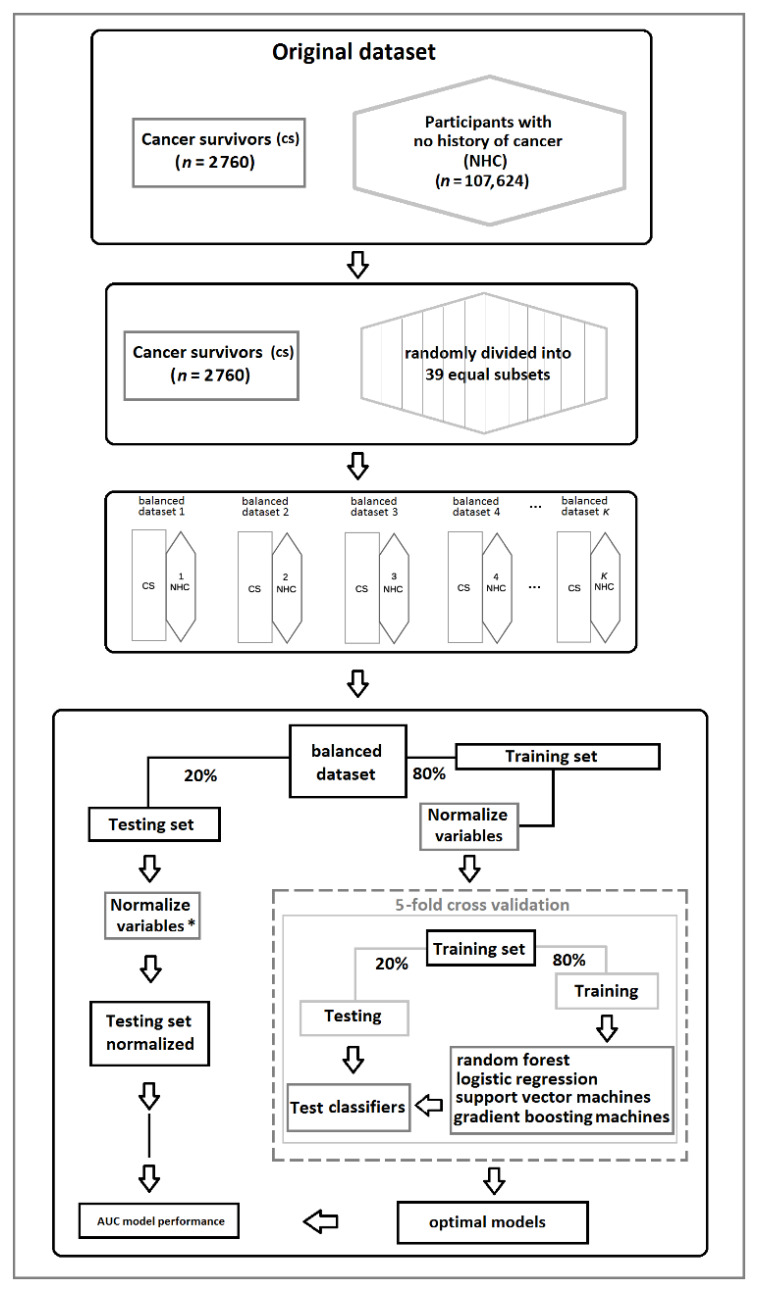
Health behaviors affect health status in cancer survivors. We hypothesized that nonlinear algorithms would identify distinct key health behaviors compared to a linear algorithm and better classify cancer survivors. We aimed to use three nonlinear algorithms to identify such key health behaviors and compare their performances with that of a logistic regression for distinguishing cancer survivors from those without cancer in a population-based cohort study. We used six health behaviors and three socioeconomic factors for analysis. Participants from the Lifelines population-based cohort were binary classified into a cancer-survivors group and a cancer-free group using either nonlinear algorithms or logistic regression, and their performances were compared by the area under the curve (AUC). In addition, we performed case-control analyses (matched by age, sex, and education level) to evaluate classification performance only by health behaviors. Data were collected for 107,624 cancer free participants and 2760 cancer survivors. Using all variables resulted an AUC of 0.75 ± 0.01, using only six health behaviors, the logistic regression and nonlinear algorithms differentiated cancer survivors from cancer-free participants with AUCs of 0.62 ± 0.01 and 0.60 ± 0.01, respectively. The main distinctive classifier was age. Though not relevant to classification, the main distinctive health behaviors were body mass index and alcohol consumption. In the case-control analyses, algorithms produced AUCs of 0.52 ± 0.01. No key health behaviors were identified by linear and nonlinear algorithms to differentiate cancer survivors from cancer-free participants in this population-based cohort.
健康行为会影响癌症幸存者的健康状况。我们假设,与线性算法相比,非线性算法能够识别出不同的关键健康行为,并能更好地对癌症幸存者进行分类。我们旨在使用三种非线性算法来识别此类关键健康行为,并在一项基于人群的队列研究中,将它们的性能与逻辑回归的性能进行比较,以区分癌症幸存者和非癌症患者。我们使用六种健康行为和三个社会经济因素进行分析。在基于人群的生命线队列研究中,参与者使用非线性算法或逻辑回归被二元分类为癌症幸存者组和无癌症组,并通过曲线下面积(AUC)比较它们的性能。此外,我们进行了病例对照分析(按年龄、性别和教育水平匹配),仅根据健康行为来评估分类性能。收集了107624名无癌症参与者和2760名癌症幸存者的数据。使用所有变量时,AUC为0.75±0.01;仅使用六种健康行为时,逻辑回归和非线性算法区分癌症幸存者和无癌症参与者的AUC分别为0.62±0.01和0.60±0.01。主要的区分因素是年龄。虽然与分类无关,但主要的显著健康行为是体重指数和饮酒量。在病例对照分析中,算法产生的AUC为0.52±0.01。在这个基于人群的队列中,线性和非线性算法均未识别出区分癌症幸存者和无癌症参与者的关键健康行为。