Center for Bioinformatics, University of Oslo (UiO), Oslo, Norway.
European Molecular Biology Laboratory, European Bioinformatics Institute, Hinxton, UK.
F1000Res. 2021 Apr 1;10. doi: 10.12688/f1000research.28449.1. eCollection 2021.
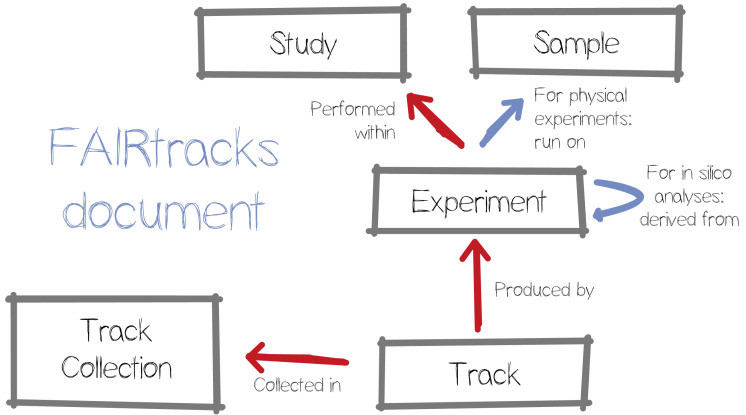
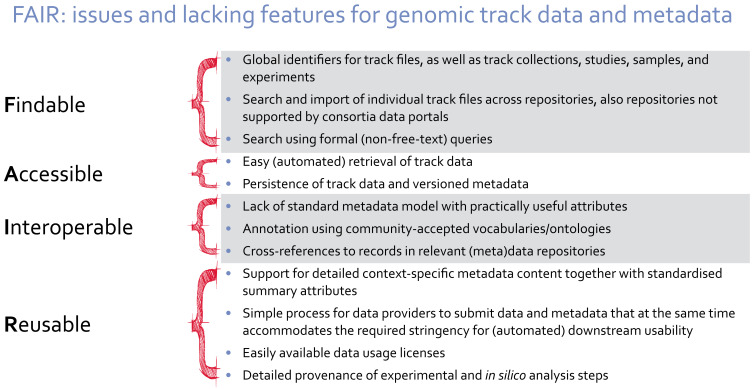
Many types of data from genomic analyses can be represented as genomic tracks, features linked to the genomic coordinates of a reference genome. Examples of such data are epigenetic DNA methylation data, ChIP-seq peaks, germline or somatic DNA variants, as well as RNA-seq expression levels. Researchers often face difficulties in locating, accessing and combining relevant tracks from external sources, as well as locating the raw data, reducing the value of the generated information. We propose to advance the application of FAIR data principles (Findable, Accessible, Interoperable, and Reusable) to produce searchable metadata for genomic tracks. Findability and Accessibility of metadata can then be ensured by a track search service that integrates globally identifiable metadata from various track hubs in the Track Hub Registry and other relevant repositories. Interoperability and Reusability need to be ensured by the specification and implementation of a basic set of recommendations for metadata. We have tested this concept by developing such a specification in a JSON Schema, called FAIRtracks, and have integrated it into a novel track search service, called TrackFind. We demonstrate practical usage by importing datasets through TrackFind into existing examples of relevant analytical tools for genomic tracks: EPICO and the GSuite HyperBrowser. We here provide a first iteration of a draft standard for genomic track metadata, as well as the accompanying software ecosystem. It can easily be adapted or extended to future needs of the research community regarding data, methods and tools, balancing the requirements of both data submitters and analytical end-users.
许多类型的基因组分析数据可以表示为基因组轨迹,这些轨迹与参考基因组的基因组坐标相关联。此类数据的示例包括表观遗传 DNA 甲基化数据、ChIP-seq 峰、种系或体细胞 DNA 变体以及 RNA-seq 表达水平。研究人员经常面临从外部来源定位、访问和组合相关轨迹以及定位原始数据的困难,从而降低了生成信息的价值。我们建议推进 FAIR 数据原则(可发现、可访问、可互操作和可重用)的应用,为基因组轨迹生成可搜索的元数据。然后,可以通过一个轨迹搜索服务来确保元数据的可发现性和可访问性,该服务整合了来自 Track Hub Registry 中的各种轨迹中心以及其他相关存储库中的全球可识别元数据。互操作性和可重用性需要通过规范和实现一组基本的元数据建议来确保。我们通过以 JSON 模式(称为 FAIRtracks)开发这种规范并将其集成到一个名为 TrackFind 的新型轨迹搜索服务中,测试了这个概念。我们通过通过 TrackFind 将数据集导入到现有的基因组轨迹相关分析工具(EPICO 和 GSuite HyperBrowser)中,展示了其实用性。我们在此提供了基因组轨迹元数据的标准草案的第一个迭代,以及伴随的软件生态系统。它可以轻松适应或扩展到研究社区在数据、方法和工具方面的未来需求,平衡数据提交者和分析最终用户的要求。