Jälkö Joonas, Lagerspetz Eemil, Haukka Jari, Tarkoma Sasu, Honkela Antti, Kaski Samuel
Helsinki Institute for Information Technology (HIIT), Department of Computer Science, Aalto University, Espoo, 00076, Finland.
Helsinki Institute for Information Technology (HIIT), Department of Computer Science, University of Helsinki, Helsinki 00014, Finland.
Patterns (N Y). 2021 Jun 7;2(7):100271. doi: 10.1016/j.patter.2021.100271. eCollection 2021 Jul 9.
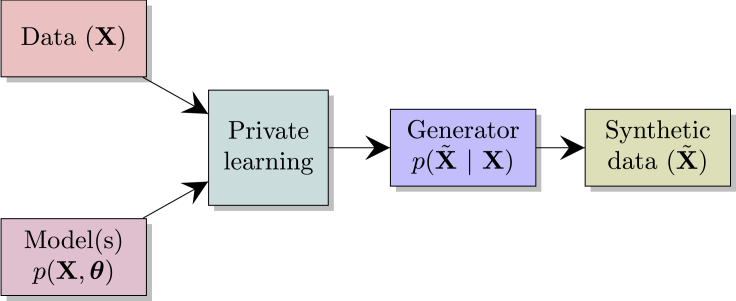
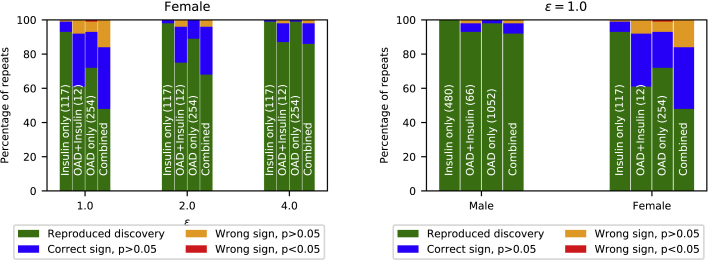
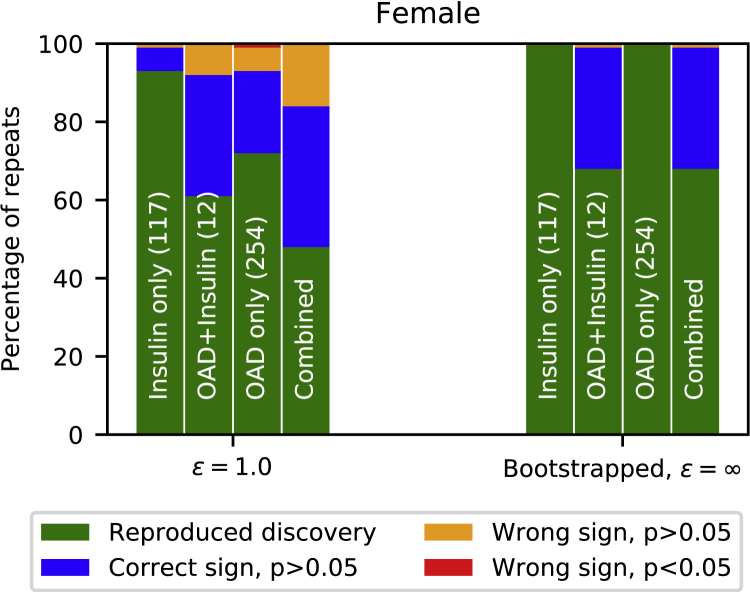
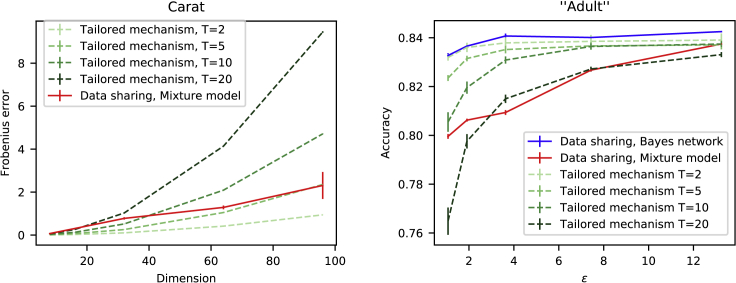
Differential privacy allows quantifying privacy loss resulting from accession of sensitive personal data. Repeated accesses to underlying data incur increasing loss. Releasing data as privacy-preserving synthetic data would avoid this limitation but would leave open the problem of designing what kind of synthetic data. We propose formulating the problem of private data release through probabilistic modeling. This approach transforms the problem of designing the synthetic data into choosing a model for the data, allowing also the inclusion of prior knowledge, which improves the quality of the synthetic data. We demonstrate empirically, in an epidemiological study, that statistical discoveries can be reliably reproduced from the synthetic data. We expect the method to have broad use in creating high-quality anonymized data twins of key datasets for research.
差分隐私允许对因加入敏感个人数据而导致的隐私损失进行量化。对基础数据的重复访问会导致越来越大的损失。以隐私保护合成数据的形式发布数据将避免这一限制,但会留下设计何种合成数据的问题。我们建议通过概率建模来阐述私有数据发布问题。这种方法将设计合成数据的问题转化为为数据选择一个模型,同时还允许纳入先验知识,从而提高合成数据的质量。我们在一项流行病学研究中通过实证证明,可以从合成数据中可靠地再现统计发现。我们期望该方法在为研究创建关键数据集的高质量匿名数据孪生体方面有广泛应用。