Pulakuntla Swetha, Lokhande Kiran Bharat, Padmavathi Pannuru, Pal Meena, Swamy Kakumani Venkateswara, Sadasivam Jayashree, Singh Shri Abhiav, Aramgam Sree Latha, Reddy Vaddi Damodara
Department of Biochemistry, REVA University, Bangalore, Karnataka 560064 India.
Bioinformatics Research Laboratory, Biotechnology and Bioinformatics Institute, Dr. D. Y. Patil Vidyapeeth, Pune, Maharashtra 411033 India.
Virusdisease. 2021 Dec;32(4):690-702. doi: 10.1007/s13337-021-00720-4. Epub 2021 Jul 15.
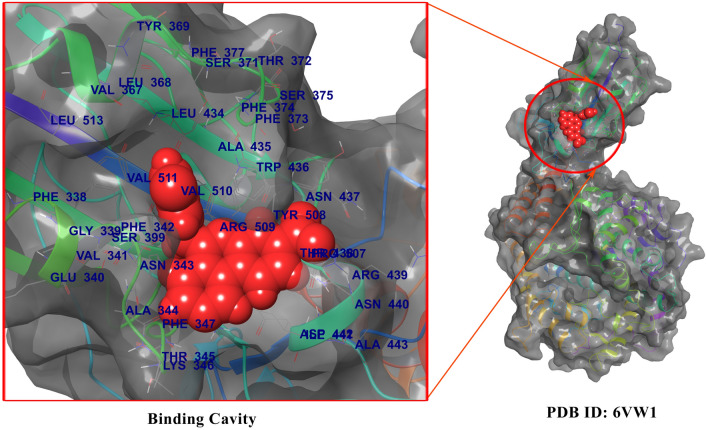
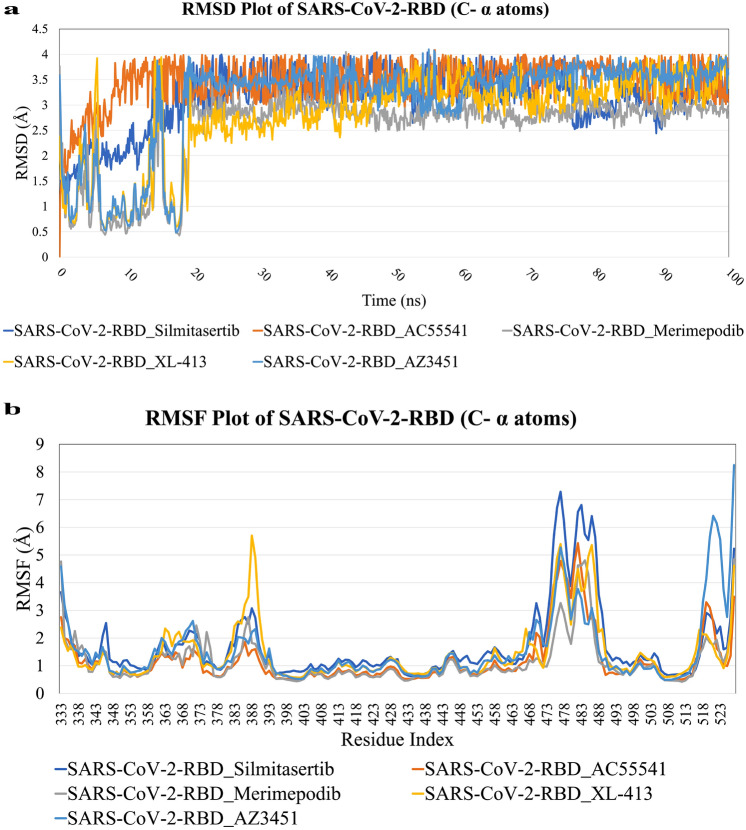
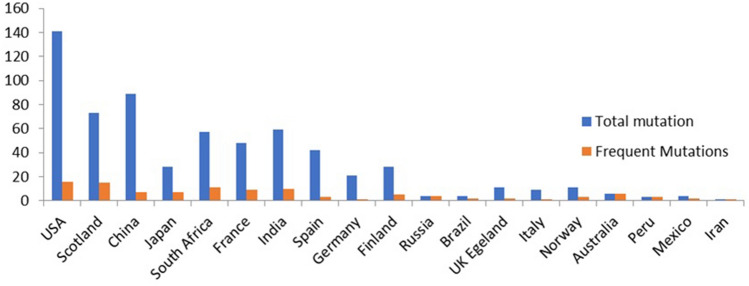
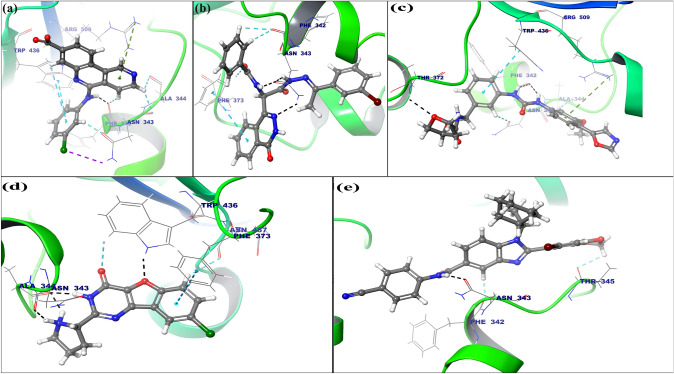
The novel SARS-CoV-2 (severe acute respiratory syndrome coronavirus-2) is spreading, as the causative pathogen of coronavirus disease-19 (COVID-19). It has infected more than 1.65 billion people all over the world since it was discovered and reported 3.43 million deaths by mid of May 2021. SARS-CoV-2 enters the host cell by binding to viral surface glycoprotein (S protein) with human ACE2 (angiotensin-converting enzyme2). Spike protein (contains S1 and S2 sub-domains) molecular interaction with the host cells is considered as a major step in the viral entry and disease initiation and progression and this identifies spike protein as a promising therapeutic target against antiviral drugs. Currently, there are no efficient antiviral drugs for the prevention of COVID-19 infection. In this study, we have analyzed global 8719 spike protein sequences from patients infected with SAR-CoV-2. These SAR-CoV-2 genome sequences were downloaded from the GISAID database. By using an open reading frame (ORF) tool we have identified the spike protein sequence. With these, all spike protein amino acid sequences are subjected to multiple sequence alignment (MSA) with Wuhan strain spike protein sequence as a query sequence, and it shows all SAR-CoV strain spike proteins are 99.8% identical. In the mutational analysis, we found 639 mutations in the spike protein sequence of SARS-CoV-2 and identified/highlighted 20 common mutations L5F, T22I, T29I, H49Y, L54F, V90F, S98F, S221L, S254F, V367F, A520S, T572I, D614G, H655Y, P809S, A879S, D936Y, A1020S, A1078S, and H1101Y. Further, we have analyzed the crystal structure of the 2019-nCoV chimeric receptor-binding complex with ACE2 (PDB ID: 6VW1) as a major target protein. The spike receptor binding protein (RBD) used as target region for our studies with FDA-approved drugs for repurposing, and identified few anti-SARS-CoV2 potential drugs (Silmitasertib, AC-55541, Merimepodib, XL413, AZ3451) based on their docking score and binding mode calculations expected to strongly bind to motifs of ACE2 receptor and may show impart relief in COVID-19 patients.
新型严重急性呼吸综合征冠状病毒2(SARS-CoV-2)正在传播,它是冠状病毒病19(COVID-19)的致病病原体。自发现并报告以来,它已感染了全球超过16.5亿人,截至2021年5月中旬导致343万人死亡。SARS-CoV-2通过其病毒表面糖蛋白(S蛋白)与人血管紧张素转换酶2(ACE2)结合进入宿主细胞。刺突蛋白(包含S1和S2亚结构域)与宿主细胞的分子相互作用被认为是病毒进入、疾病起始和进展的关键步骤,这使得刺突蛋白成为抗病毒药物的一个有前景的治疗靶点。目前,尚无有效的抗病毒药物可预防COVID-19感染。在本研究中,我们分析了来自感染SARS-CoV-2患者的8719条全球刺突蛋白序列。这些SARS-CoV-2基因组序列从全球共享流感数据倡议组织(GISAID)数据库下载。通过使用开放阅读框(ORF)工具,我们确定了刺突蛋白序列。利用这些序列,所有刺突蛋白氨基酸序列以武汉株刺突蛋白序列作为查询序列进行多序列比对(MSA),结果显示所有SARS-CoV株刺突蛋白的序列一致性为99.8%。在突变分析中,我们在SARS-CoV-2刺突蛋白序列中发现了639个突变,并识别/突出显示了20个常见突变,即L5F、T22I、T29I、H49Y、L54F、V90F、S98F、S221L、S254F、V367F、A520S、T572I、D614G、H655Y、P809S、A879S、D936Y、A1020S、A1078S和H1101Y。此外,我们以2019-nCoV与ACE2的嵌合受体结合复合物的晶体结构(PDB ID:6VW1)作为主要靶蛋白进行了分析。刺突受体结合蛋白(RBD)作为我们研究的靶区域,使用美国食品药品监督管理局(FDA)批准的药物进行重新利用,并根据其对接分数和结合模式计算确定了几种抗SARS-CoV-2潜在药物(西洛他赛、AC-55541、美立波地、XL413、AZ3451),预计这些药物会与ACE2受体基序紧密结合,并可能缓解COVID-19患者的症状。