Sandhu Karansher Singh, Aoun Meriem, Morris Craig F, Carter Arron H
Department of Crop and Soil Sciences, Washington State University, Pullman, WA 99164, USA.
USDA-ARS Western Wheat Quality Laboratory, E-202 Food Quality Building, Washington State University, Pullman, WA 99164, USA.
Biology (Basel). 2021 Jul 20;10(7):689. doi: 10.3390/biology10070689.
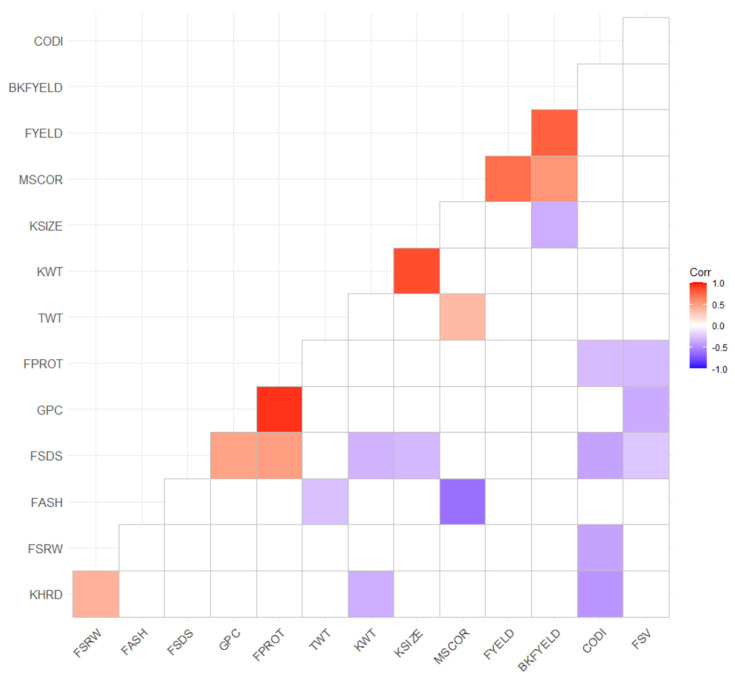
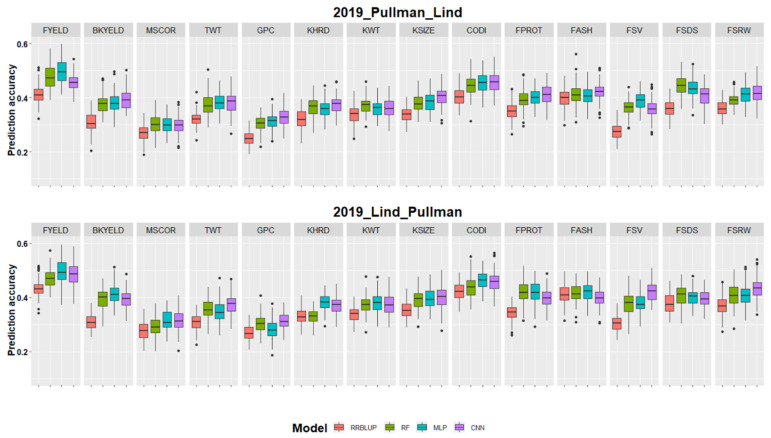
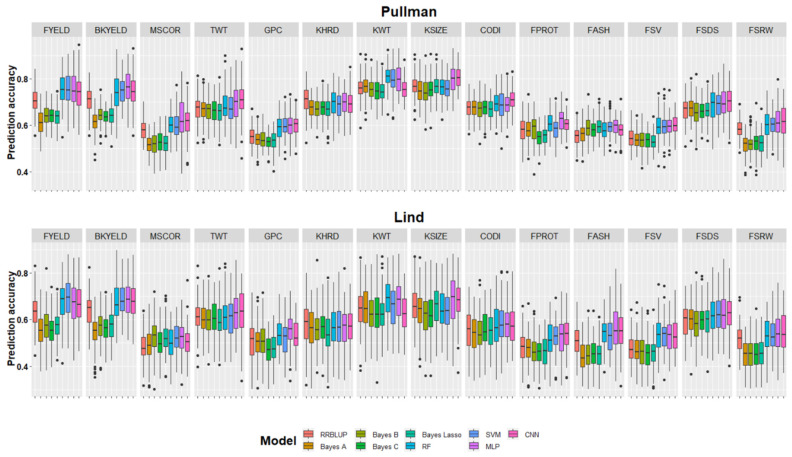
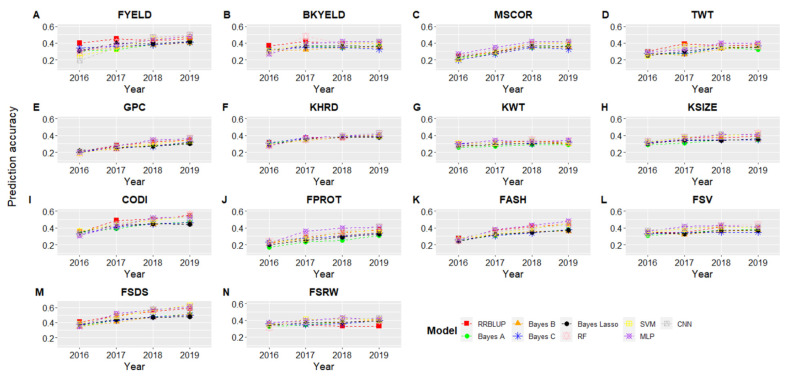
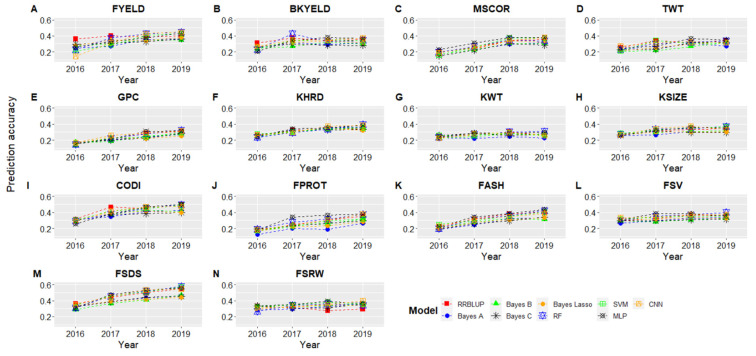
Breeding for grain yield, biotic and abiotic stress resistance, and end-use quality are important goals of wheat breeding programs. Screening for end-use quality traits is usually secondary to grain yield due to high labor needs, cost of testing, and large seed requirements for phenotyping. Genomic selection provides an alternative to predict performance using genome-wide markers under forward and across location predictions, where a previous year's dataset can be used to build the models. Due to large datasets in breeding programs, we explored the potential of the machine and deep learning models to predict fourteen end-use quality traits in a winter wheat breeding program. The population used consisted of 666 wheat genotypes screened for five years (2015-19) at two locations (Pullman and Lind, WA, USA). Nine different models, including two machine learning (random forest and support vector machine) and two deep learning models (convolutional neural network and multilayer perceptron) were explored for cross-validation, forward, and across locations predictions. The prediction accuracies for different traits varied from 0.45-0.81, 0.29-0.55, and 0.27-0.50 under cross-validation, forward, and across location predictions. In general, forward prediction accuracies kept increasing over time due to increments in training data size and was more evident for machine and deep learning models. Deep learning models were superior over the traditional ridge regression best linear unbiased prediction (RRBLUP) and Bayesian models under all prediction scenarios. The high accuracy observed for end-use quality traits in this study support predicting them in early generations, leading to the advancement of superior genotypes to more extensive grain yield trails. Furthermore, the superior performance of machine and deep learning models strengthens the idea to include them in large scale breeding programs for predicting complex traits.
培育高产、抗生物和非生物胁迫以及具备最终用途品质的小麦是小麦育种计划的重要目标。由于检测所需劳动力多、测试成本高以及表型分析对种子需求量大,最终用途品质性状的筛选通常次于产量筛选。基因组选择提供了一种替代方法,可在向前预测和跨地点预测中使用全基因组标记来预测性能,其中上一年的数据集可用于构建模型。鉴于育种计划中的数据集规模庞大,我们探索了机器学习和深度学习模型在冬小麦育种计划中预测14种最终用途品质性状的潜力。所使用的群体由666个小麦基因型组成,在美国华盛顿州普尔曼和林德的两个地点进行了为期五年(2015 - 2019年)的筛选。我们探索了九种不同的模型,包括两种机器学习模型(随机森林和支持向量机)和两种深度学习模型(卷积神经网络和多层感知器),用于交叉验证、向前预测和跨地点预测。在交叉验证、向前预测和跨地点预测下,不同性状的预测准确率分别为0.45 - 0.81、0.29 - 0.55和0.27 - 0.50。一般来说,由于训练数据量的增加,向前预测准确率随时间不断提高,这在机器学习和深度学习模型中更为明显。在所有预测场景下,深度学习模型均优于传统的岭回归最佳线性无偏预测(RRBLUP)和贝叶斯模型。本研究中观察到的最终用途品质性状的高精度支持在早期世代对其进行预测,从而使优良基因型能够进入更广泛的产量试验。此外,机器学习和深度学习模型的卓越性能强化了将它们纳入大规模育种计划以预测复杂性状的想法。