El Rifai Hozayfa, Al Qadi Leen, Elnagar Ashraf
Department of Computer Science, University of Sharjah, Sharjah, UAE.
Neural Comput Appl. 2022;34(2):1135-1159. doi: 10.1007/s00521-021-06390-z. Epub 2021 Sep 1.
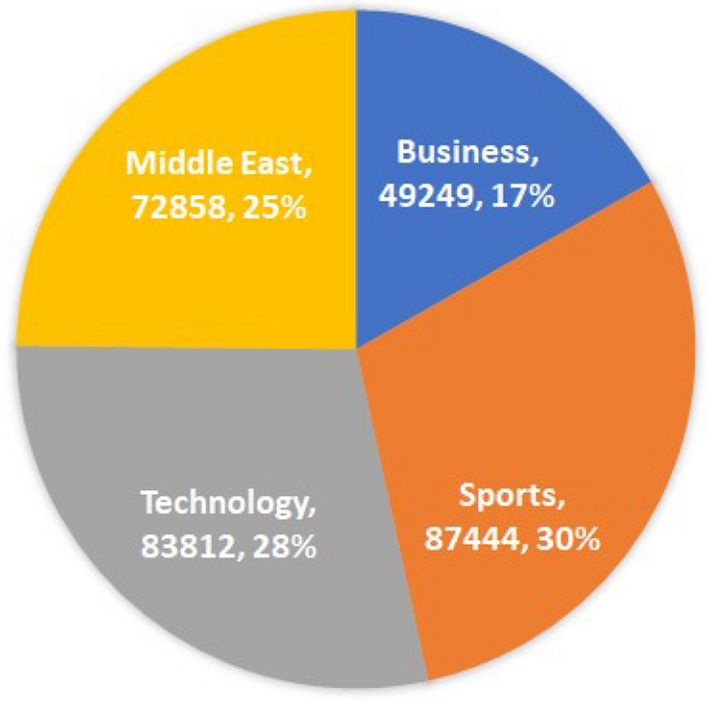
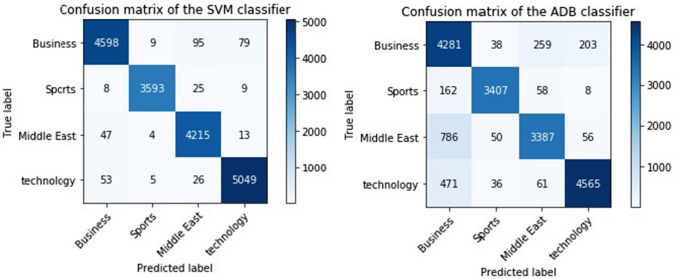
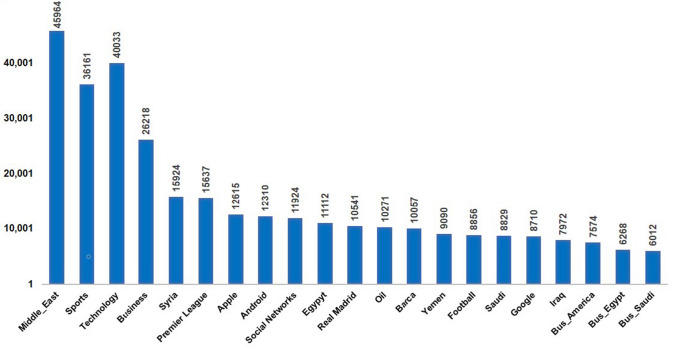
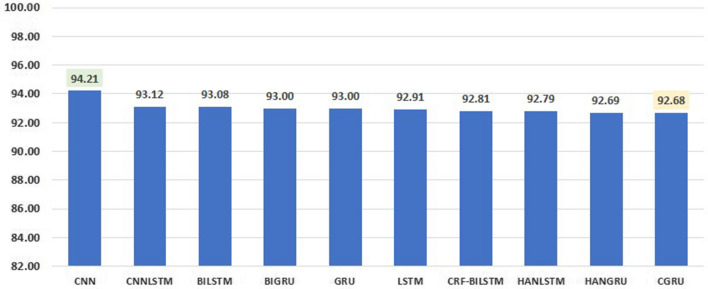
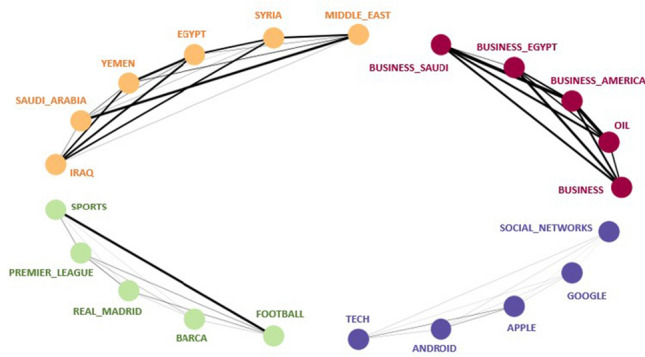
The process of tagging a given text or document with suitable labels is known as text categorization or classification. The aim of this work is to automatically tag a news article based on its vocabulary features. To accomplish this objective, 2 large datasets have been constructed from various Arabic news portals. The first dataset contains of 90k single-labeled articles from 4 domains (Business, Middle East, Technology and Sports). The second dataset has over 290 k multi-tagged articles. To examine the single-label dataset, we employed an array of ten shallow learning classifiers. Furthermore, we added an ensemble model that adopts the majority-voting technique of all studied classifiers. The performance of the classifiers on the first dataset ranged between 87.7% (AdaBoost) and 97.9% (SVM). Analyzing some of the misclassified articles confirmed the need for a multi-label opposed to single-label categorization for better classification results. For the second dataset, we tested both shallow learning and deep learning multi-labeling approaches. A custom accuracy metric, designed for the multi-labeling task, has been developed for performance evaluation along with hamming loss metric. Firstly, we used classifiers that were compatible with multi-labeling tasks such as Logistic Regression and XGBoost, by wrapping each in a OneVsRest classifier. XGBoost gave the higher accuracy, scoring 84.7%, while Logistic Regression scored 81.3%. Secondly, ten neural networks were constructed (CNN, CLSTM, LSTM, BILSTM, GRU, CGRU, BIGRU, HANGRU, CRF-BILSTM and HANLSTM). CGRU proved to be the best multi-labeling classifier scoring an accuracy of 94.85%, higher than the rest of the classifies.
用合适的标签标记给定文本或文档的过程称为文本分类。这项工作的目的是根据新闻文章的词汇特征自动为其添加标签。为实现这一目标,从各种阿拉伯新闻门户网站构建了两个大型数据集。第一个数据集包含来自4个领域(商业、中东、科技和体育)的90000篇单标签文章。第二个数据集有超过290000篇多标签文章。为了检验单标签数据集,我们使用了一系列十个浅层学习分类器。此外,我们添加了一个采用所有研究分类器的多数投票技术的集成模型。分类器在第一个数据集上的性能介于87.7%(AdaBoost)和97.9%(支持向量机)之间。对一些错误分类的文章进行分析后证实,为了获得更好的分类结果,需要采用多标签而非单标签分类。对于第二个数据集,我们测试了浅层学习和深度学习多标签方法。为了进行性能评估,开发了一种专为多标签任务设计的自定义准确率指标以及汉明损失指标。首先,我们使用了与多标签任务兼容的分类器,如逻辑回归和XGBoost,将它们分别包装在一个一对其余分类器中。XGBoost的准确率更高,得分为84.7%,而逻辑回归的得分为81.3%。其次,构建了十个神经网络(卷积神经网络、卷积长短期记忆网络、长短期记忆网络、双向长短期记忆网络、门控循环单元、卷积门控循环单元、双向门控循环单元、层次注意力网络门控循环单元、条件随机场双向长短期记忆网络和层次注意力网络长短期记忆网络)。卷积门控循环单元被证明是最好的多标签分类器,准确率为94.85%,高于其他分类器。