Gu Shanzhi, Geng Mingyang, Lan Long
College of Computer, National University of Defense Technology, Changsha 410073, China.
High Performance Computing Laboratory, National University of Defense Technology, Changsha 410073, China.
Entropy (Basel). 2021 Aug 31;23(9):1133. doi: 10.3390/e23091133.
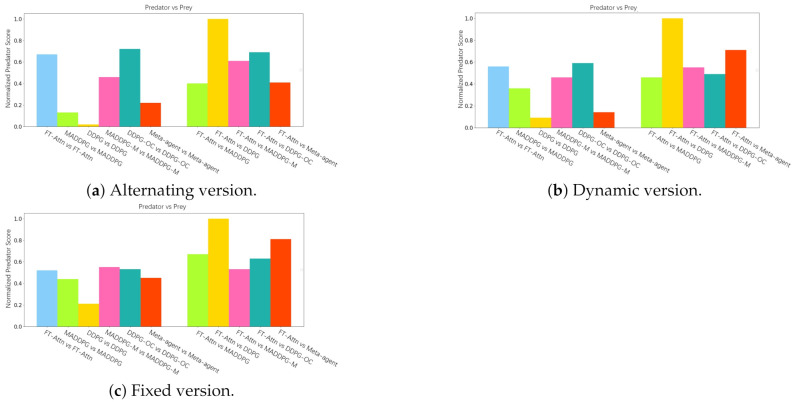
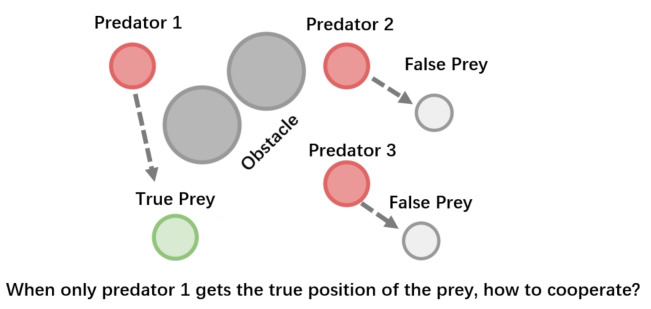
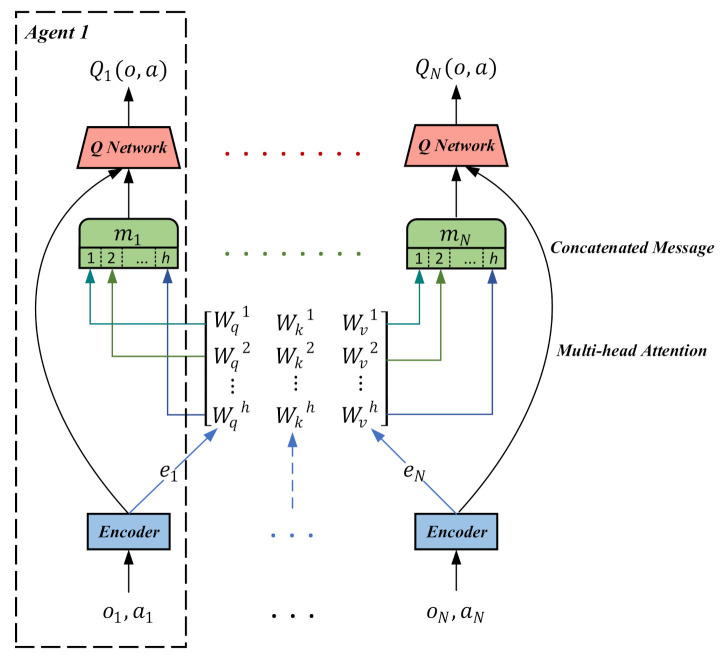
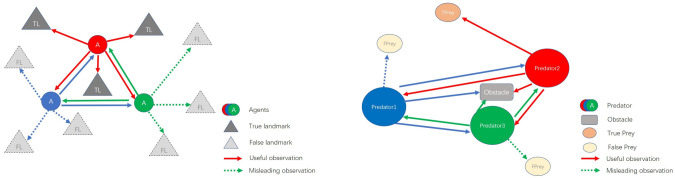
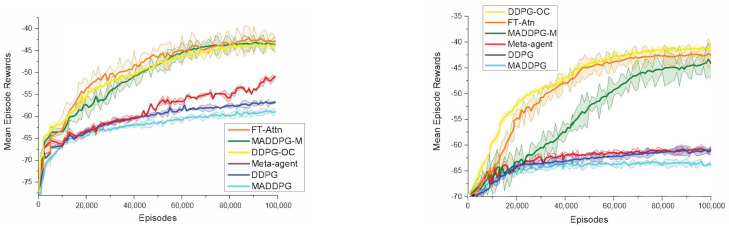
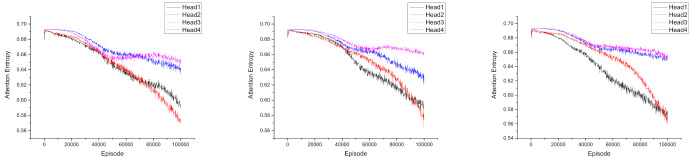
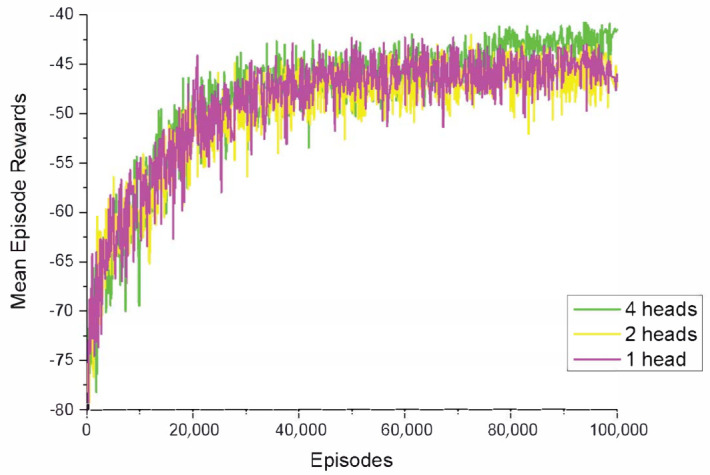
The aim of multi-agent reinforcement learning systems is to provide interacting agents with the ability to collaboratively learn and adapt to the behavior of other agents. Typically, an agent receives its private observations providing a partial view of the true state of the environment. However, in realistic settings, the harsh environment might cause one or more agents to show arbitrarily faulty or malicious behavior, which may suffice to allow the current coordination mechanisms fail. In this paper, we study a practical scenario of multi-agent reinforcement learning systems considering the security issues in the presence of agents with arbitrarily faulty or malicious behavior. The previous state-of-the-art work that coped with extremely noisy environments was designed on the basis that the noise intensity in the environment was known in advance. However, when the noise intensity changes, the existing method has to adjust the configuration of the model to learn in new environments, which limits the practical applications. To overcome these difficulties, we present an Attention-based Fault-Tolerant (FT-Attn) model, which can select not only correct, but also relevant information for each agent at every time step in noisy environments. The multihead attention mechanism enables the agents to learn effective communication policies through experience concurrent with the action policies. Empirical results showed that FT-Attn beats previous state-of-the-art methods in some extremely noisy environments in both cooperative and competitive scenarios, much closer to the upper-bound performance. Furthermore, FT-Attn maintains a more general fault tolerance ability and does not rely on the prior knowledge about the noise intensity of the environment.
多智能体强化学习系统的目标是为相互作用的智能体提供协同学习和适应其他智能体行为的能力。通常,一个智能体接收其私有观测值,这些观测值提供了环境真实状态的部分视图。然而,在现实场景中,恶劣的环境可能会导致一个或多个智能体表现出任意的故障或恶意行为,这可能足以使当前的协调机制失效。在本文中,我们研究了多智能体强化学习系统在存在具有任意故障或恶意行为的智能体时的安全问题的实际场景。之前应对极端噪声环境的最先进工作是在环境噪声强度提前已知的基础上设计的。然而,当噪声强度发生变化时,现有方法必须调整模型配置以在新环境中学习,这限制了实际应用。为了克服这些困难,我们提出了一种基于注意力的容错(FT-Attn)模型,该模型在噪声环境中的每个时间步不仅可以为每个智能体选择正确的信息,还可以选择相关信息。多头注意力机制使智能体能够在学习动作策略的同时通过经验学习有效的通信策略。实证结果表明,在合作和竞争场景中的一些极端噪声环境中,FT-Attn优于先前的最先进方法,更接近上限性能。此外,FT-Attn保持了更通用的容错能力,并且不依赖于关于环境噪声强度的先验知识。