Interdisciplinary Centre for Security, Reliability and Trust, University of Luxembourg, 6 Rue Richard Coudenhove-Kalergi, L-1359 Luxembourg, Luxembourg.
Cebi Luxembourg S.A, 30 rue J.F. Kennedy, L-7327 Steinsel, Luxembourg.
Sensors (Basel). 2021 Sep 15;21(18):6195. doi: 10.3390/s21186195.
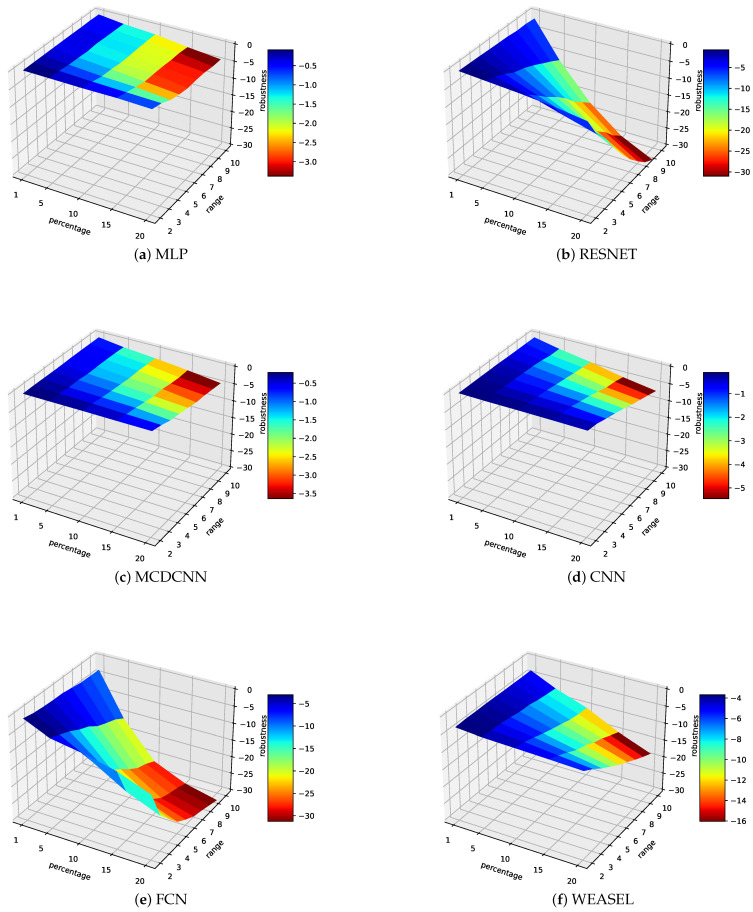
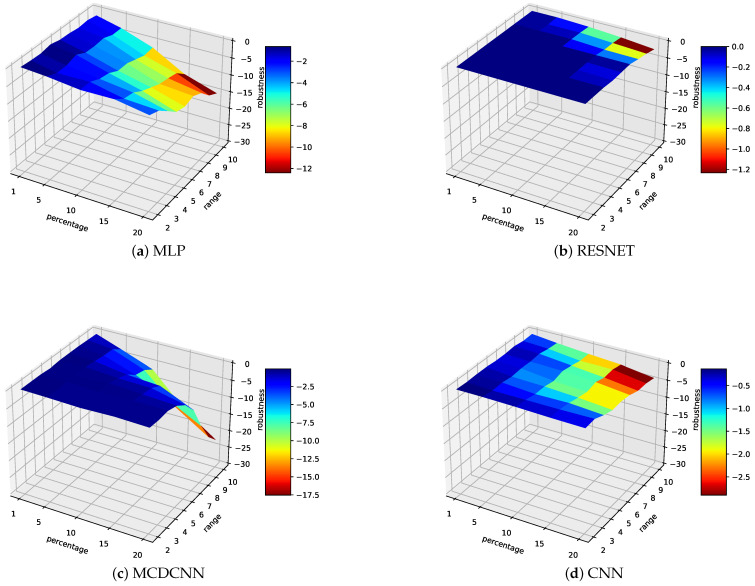
Artificial Intelligence (AI) is one of the hottest topics in our society, especially when it comes to solving data-analysis problems. Industry are conducting their digital shifts, and AI is becoming a cornerstone technology for making decisions out of the huge amount of (sensors-based) data available in the production floor. However, such technology may be disappointing when deployed in real conditions. Despite good theoretical performances and high accuracy when trained and tested in isolation, a Machine-Learning (M-L) model may provide degraded performances in real conditions. One reason may be fragility in treating properly unexpected or perturbed data. The objective of the paper is therefore to study the robustness of seven M-L and Deep-Learning (D-L) algorithms, when classifying univariate time-series under perturbations. A systematic approach is proposed for artificially injecting perturbations in the data and for evaluating the robustness of the models. This approach focuses on two perturbations that are likely to happen during data collection. Our experimental study, conducted on twenty sensors' datasets from the public University of California Riverside (UCR) repository, shows a great disparity of the models' robustness under data quality degradation. Those results are used to analyse whether the impact of such robustness can be predictable-thanks to decision trees-which would prevent us from testing all perturbations scenarios. Our study shows that building such a predictor is not straightforward and suggests that such a systematic approach needs to be used for evaluating AI models' robustness.
人工智能(AI)是我们社会中最热门的话题之一,特别是在解决数据分析问题方面。企业正在进行数字化转型,人工智能正在成为从生产现场大量(基于传感器)数据中做出决策的基石技术。然而,当这种技术在实际条件下部署时,可能会令人失望。尽管在单独训练和测试时具有良好的理论性能和高精度,但机器学习(ML)模型在实际条件下可能会提供降级的性能。一个原因可能是在正确处理意外或干扰数据方面的脆弱性。因此,本文的目的是研究在扰动下对单变量时间序列进行分类时,七种机器学习和深度学习(DL)算法的鲁棒性。提出了一种系统的方法来人为地在数据中注入扰动,并评估模型的鲁棒性。该方法侧重于在数据收集过程中可能发生的两种扰动。我们在来自加利福尼亚大学河滨分校(UCR)公共数据库的二十个传感器数据集上进行的实验研究表明,在数据质量下降下,模型的鲁棒性存在很大差异。这些结果用于分析这种鲁棒性的影响是否可以通过决策树来预测,这将防止我们测试所有的扰动场景。我们的研究表明,构建这样的预测器并不简单,并表明需要使用这种系统方法来评估人工智能模型的鲁棒性。