Groningen Institute for Evolutionary Life Sciences, University of Groningen, Groningen, The Netherlands.
Department of Coastal Systems, NIOZ Royal Netherlands Institute for Sea Research, Den Burg, The Netherlands.
J Anim Ecol. 2022 Feb;91(2):287-307. doi: 10.1111/1365-2656.13610. Epub 2021 Nov 16.
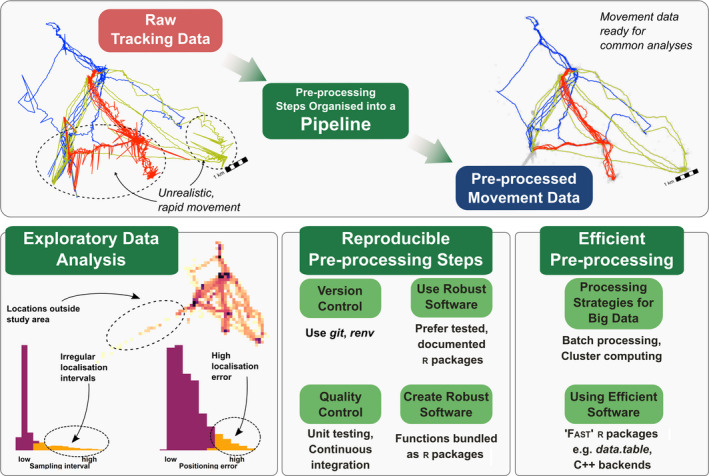
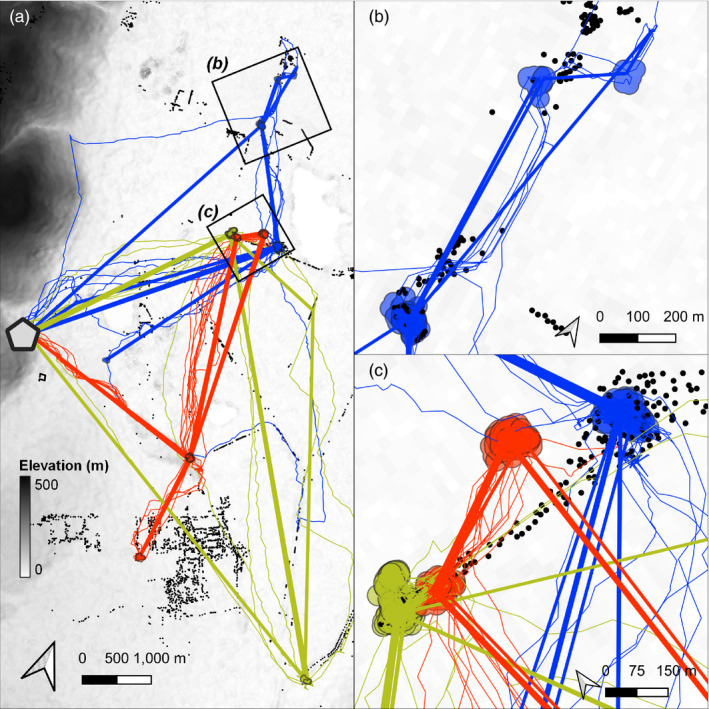
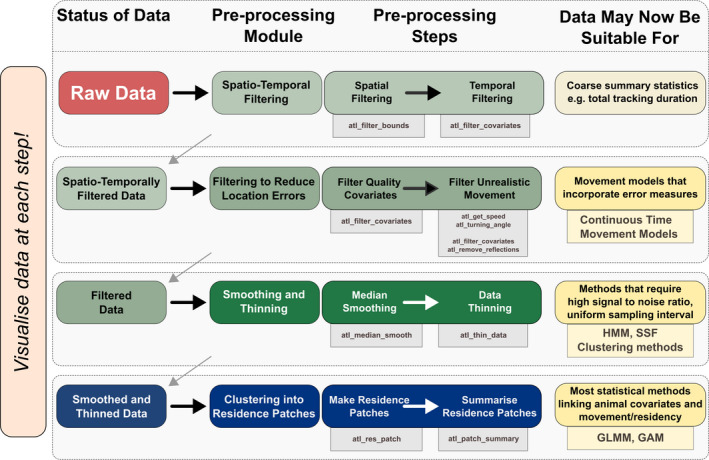
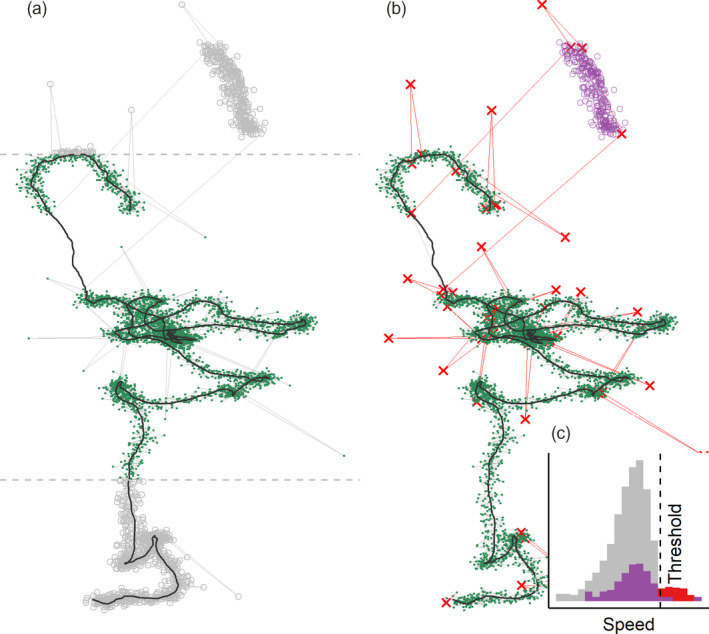
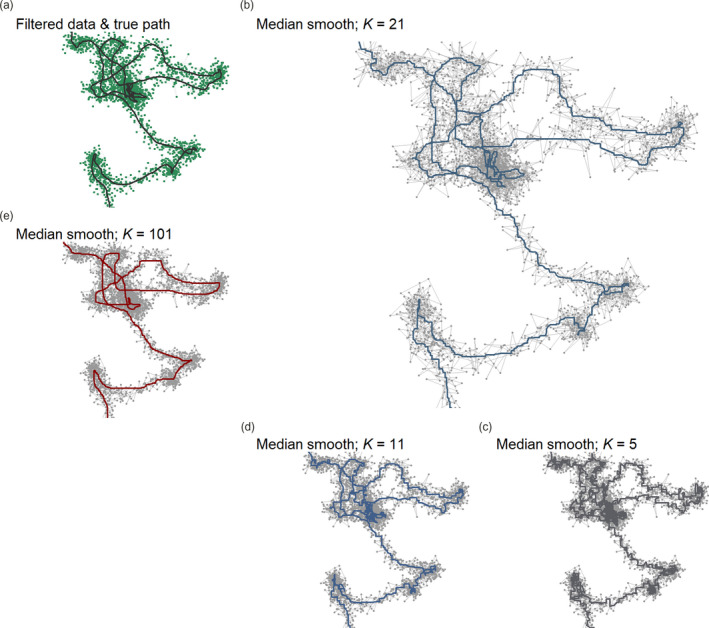
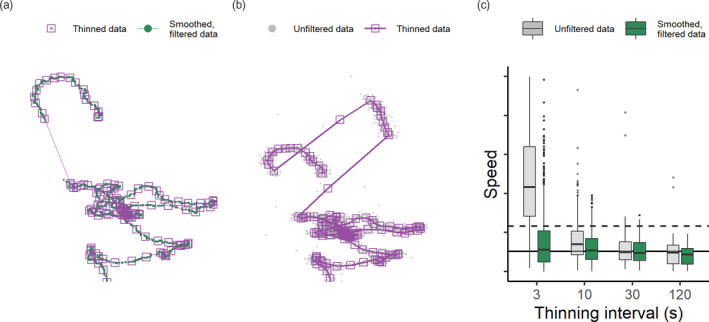
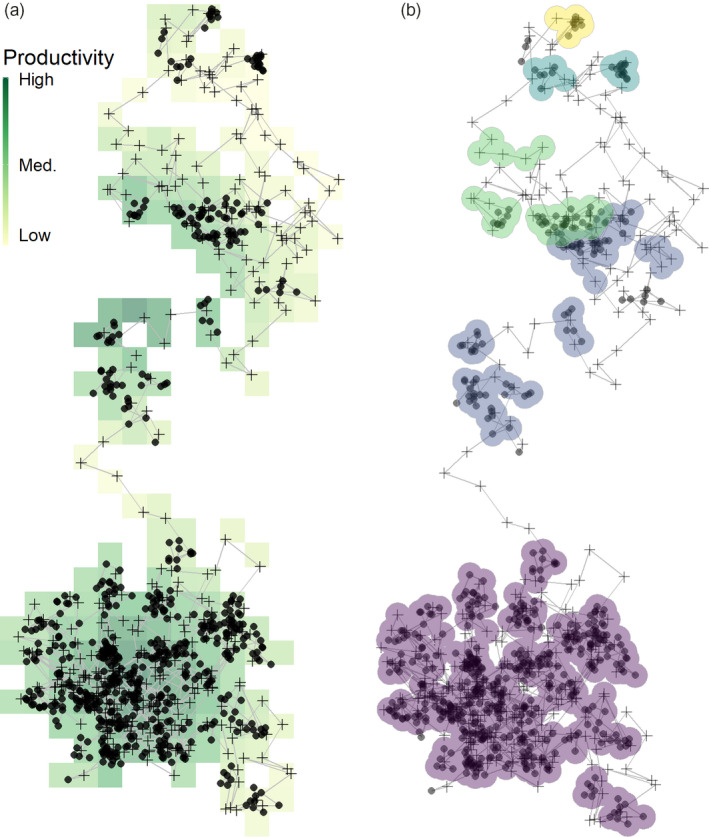
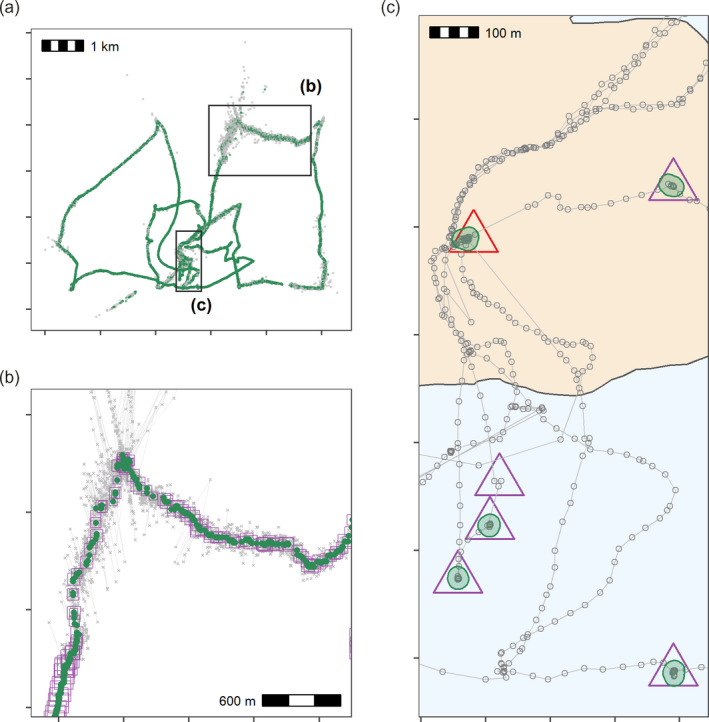
Modern, high-throughput animal tracking increasingly yields 'big data' at very fine temporal scales. At these scales, location error can exceed the animal's step size, leading to mis-estimation of behaviours inferred from movement. 'Cleaning' the data to reduce location errors is one of the main ways to deal with position uncertainty. Although data cleaning is widely recommended, inclusive, uniform guidance on this crucial step, and on how to organise the cleaning of massive datasets, is relatively scarce. A pipeline for cleaning massive high-throughput datasets must balance ease of use and computationally efficiency, in which location errors are rejected while preserving valid animal movements. Another useful feature of a pre-processing pipeline is efficiently segmenting and clustering location data for statistical methods while also being scalable to large datasets and robust to imperfect sampling. Manual methods being prohibitively time-consuming, and to boost reproducibility, pre-processing pipelines must be automated. We provide guidance on building pipelines for pre-processing high-throughput animal tracking data to prepare it for subsequent analyses. We apply our proposed pipeline to simulated movement data with location errors, and also show how large volumes of cleaned data can be transformed into biologically meaningful 'residence patches', for exploratory inference on animal space use. We use tracking data from the Wadden Sea ATLAS system (WATLAS) to show how pre-processing improves its quality, and to verify the usefulness of the residence patch method. Finally, with tracks from Egyptian fruit bats Rousettus aegyptiacus, we demonstrate the pre-processing pipeline and residence patch method in a fully worked out example. To help with fast implementation of standardised methods, we developed the R package atlastools, which we also introduce here. Our pre-processing pipeline and atlastools can be used with any high-throughput animal movement data in which the high data-volume combined with knowledge of the tracked individuals' movement capacity can be used to reduce location errors. atlastools is easy to use for beginners while providing a template for further development. The common use of simple yet robust pre-processing steps promotes standardised methods in the field of movement ecology and leads to better inferences from data.
现代高通量动物追踪技术在非常精细的时间尺度上产生了“大数据”。在这些尺度上,位置误差可能超过动物的步长,从而导致对运动推断行为的错误估计。“清理”数据以减少位置误差是处理位置不确定性的主要方法之一。尽管数据清理被广泛推荐,但关于这一关键步骤以及如何组织大规模数据集的清理,缺乏全面、统一的指导。清理大规模高通量数据集的流水线必须平衡易用性和计算效率,在保留有效动物运动的同时拒绝位置误差。预处理流水线的另一个有用特征是能够有效地分割和聚类位置数据,以便进行统计方法分析,同时还可以扩展到大规模数据集,并对不完美的采样具有鲁棒性。手动方法非常耗时,为了提高可重复性,预处理流水线必须自动化。我们提供了关于构建预处理高通量动物追踪数据流水线的指导,以准备对后续分析进行处理。我们将我们提出的流水线应用于具有位置误差的模拟运动数据,还展示了如何将大量清理后的数据转换为生物上有意义的“居留斑块”,以便对动物空间使用进行探索性推断。我们使用 Wadden 海 ATLAS 系统(WATLAS)的跟踪数据来展示预处理如何提高其质量,并验证居留斑块方法的有用性。最后,我们使用埃及果蝠 Rousettus aegyptiacus 的跟踪数据,演示了预处理流水线和居留斑块方法的完整示例。为了帮助快速实现标准化方法,我们开发了 R 包 atlastools,我们也在这里介绍它。我们的预处理流水线和 atlastools 可以与任何高通量动物运动数据一起使用,这些数据与所跟踪个体的运动能力的高数据量相结合,可以用于减少位置误差。atlastools 易于初学者使用,同时为进一步发展提供了模板。简单而稳健的预处理步骤的共同使用促进了运动生态学领域的标准化方法,并导致从数据中得出更好的推断。