Lu Hao, Wei Zhiqiang, Wang Cunji, Guo Jingjing, Zhou Yuandong, Wang Zhuoya, Liu Hao
College of Computer Science and Technology, Ocean University of China, Qingdao, China.
Pilot National Laboratory for Marine Science and Technology, Qingdao, China.
Front Chem. 2021 Oct 28;9:750325. doi: 10.3389/fchem.2021.750325. eCollection 2021.
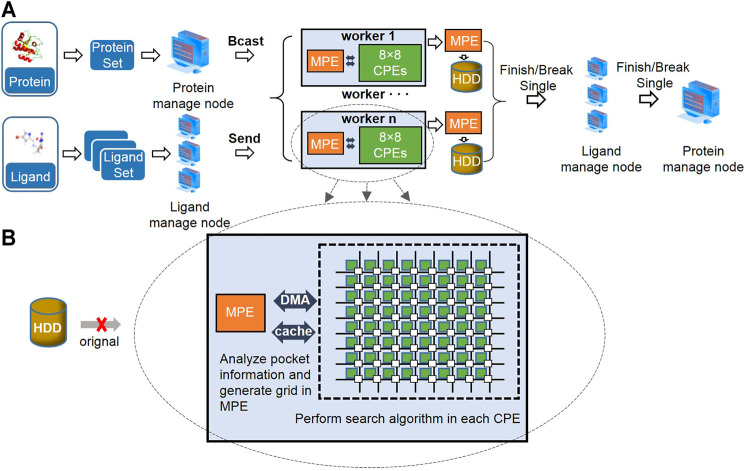
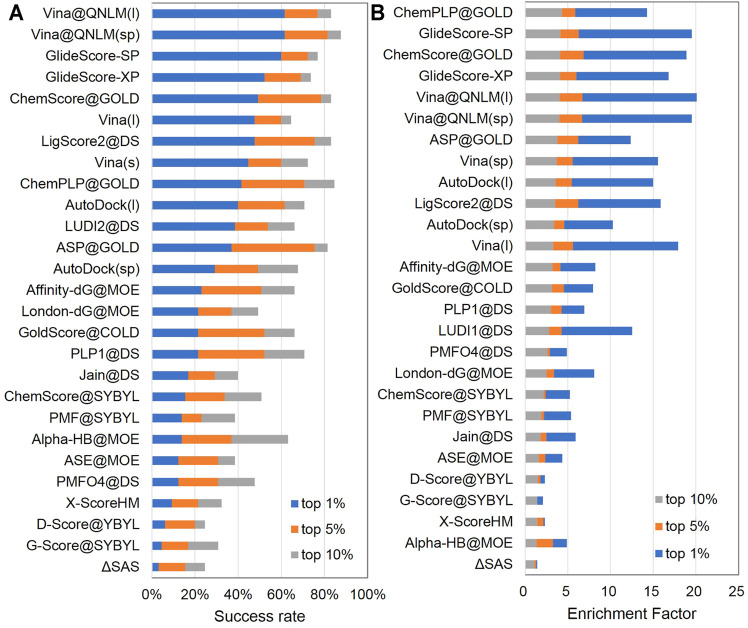
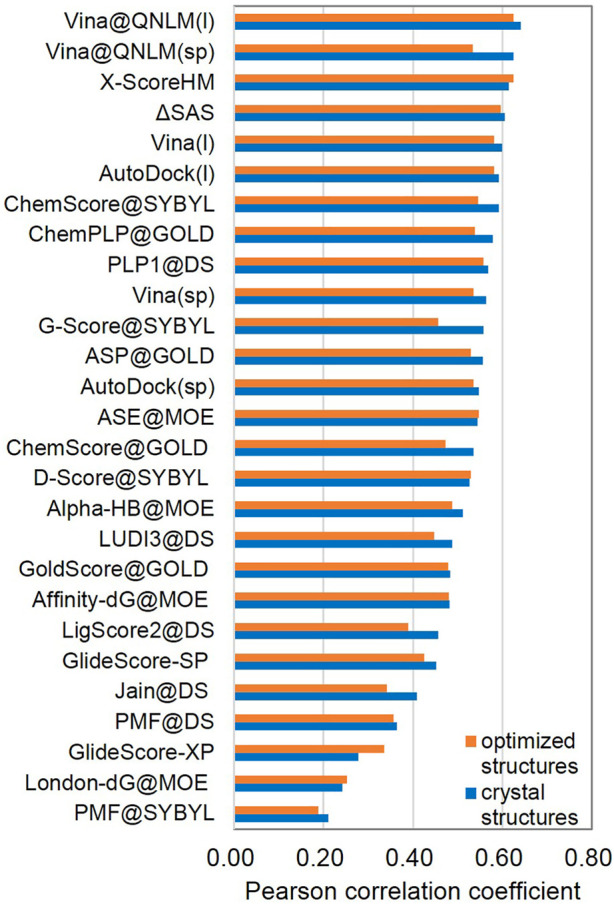
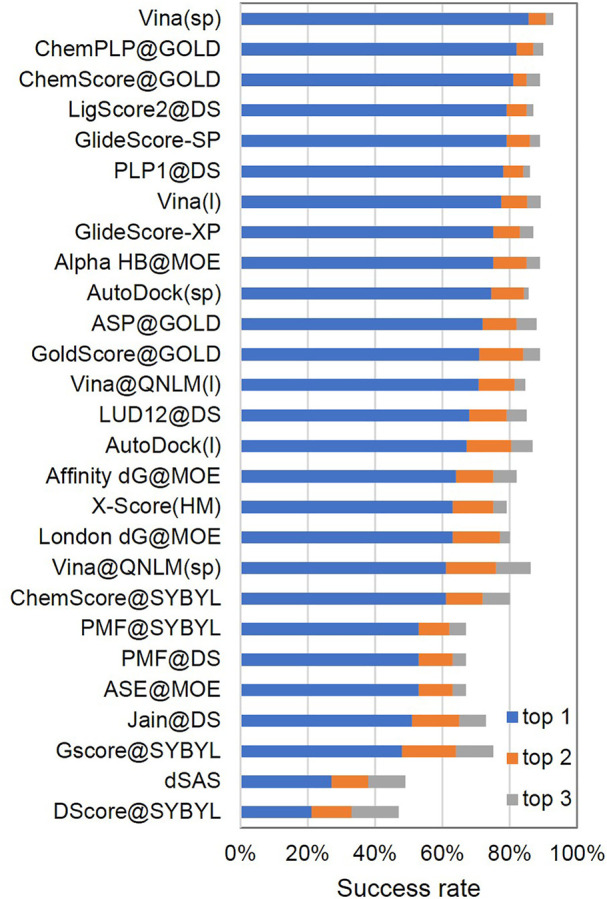
Ultra-large-scale molecular docking can improve the accuracy of lead compounds in drug discovery. In this study, we developed a molecular docking piece of software, Vina@QNLM, which can use more than 4,80,000 parallel processes to search for potential lead compounds from hundreds of millions of compounds. We proposed a task scheduling mechanism for large-scale parallelism based on Vinardo and Sunway supercomputer architecture. Then, we readopted the core docking algorithm to incorporate the full advantage of the heterogeneous multicore processor architecture in intensive computing. We successfully expanded it to 10, 465, 065 cores (1,61,001 management process elements and 0, 465, 065 computing process elements), with a strong scalability of 55.92%. To the best of our knowledge, this is the first time that 10 million cores are used for molecular docking on Sunway. The introduction of the heterogeneous multicore processor architecture achieved the best speedup, which is 11x more than that of the management process element of Sunway. The performance of Vina@QNLM was comprehensively evaluated using the CASF-2013 and CASF-2016 protein-ligand benchmarks, and the screening power was the highest out of the 27 pieces of software tested in the CASF-2013 benchmark. In some existing applications, we used Vina@QNLM to dock more than 10 million molecules to nine rigid proteins related to SARS-CoV-2 within 8.5 h on 10 million cores. We also developed a platform for the general public to use the software.
超大规模分子对接可以提高药物研发中先导化合物的准确性。在本研究中,我们开发了一款分子对接软件Vina@QNLM,它可以使用超过48万个并行进程从数亿种化合物中搜索潜在的先导化合物。我们基于天河和神威超级计算机架构提出了一种用于大规模并行的任务调度机制。然后,我们重新采用核心对接算法,以充分利用异构多核处理器架构在密集计算方面的优势。我们成功地将其扩展到10465065个核心(161001个管理处理单元和465065个计算处理单元),具有55.92%的强扩展性。据我们所知,这是首次在神威上使用1000万个核心进行分子对接。异构多核处理器架构的引入实现了最佳加速比,比神威的管理处理单元快11倍。使用CASF - 2013和CASF - 2016蛋白质 - 配体基准对Vina@QNLM的性能进行了全面评估,在CASF - 2013基准测试的27款软件中,其筛选能力最高。在一些现有应用中,我们使用Vina@QNLM在1000万个核心上于8.5小时内将超过1000万个分子与9种与SARS-CoV-2相关的刚性蛋白进行对接。我们还开发了一个供公众使用该软件的平台。