Department of Experimental Psychology, Justus-Liebig-University Giessen, Giessen, Germany.
Department of Computer Science and Engineering, Toyohashi University of Technology, Toyohashi, Aichi, Japan.
J Vis. 2021 Nov 1;21(12):14. doi: 10.1167/jov.21.12.14.
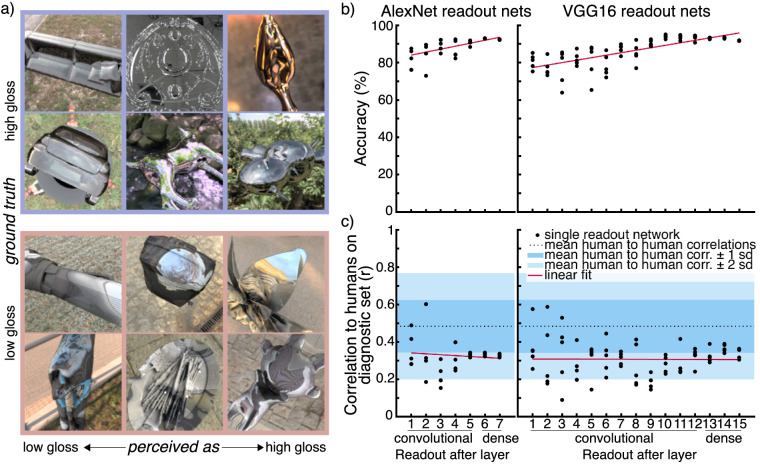
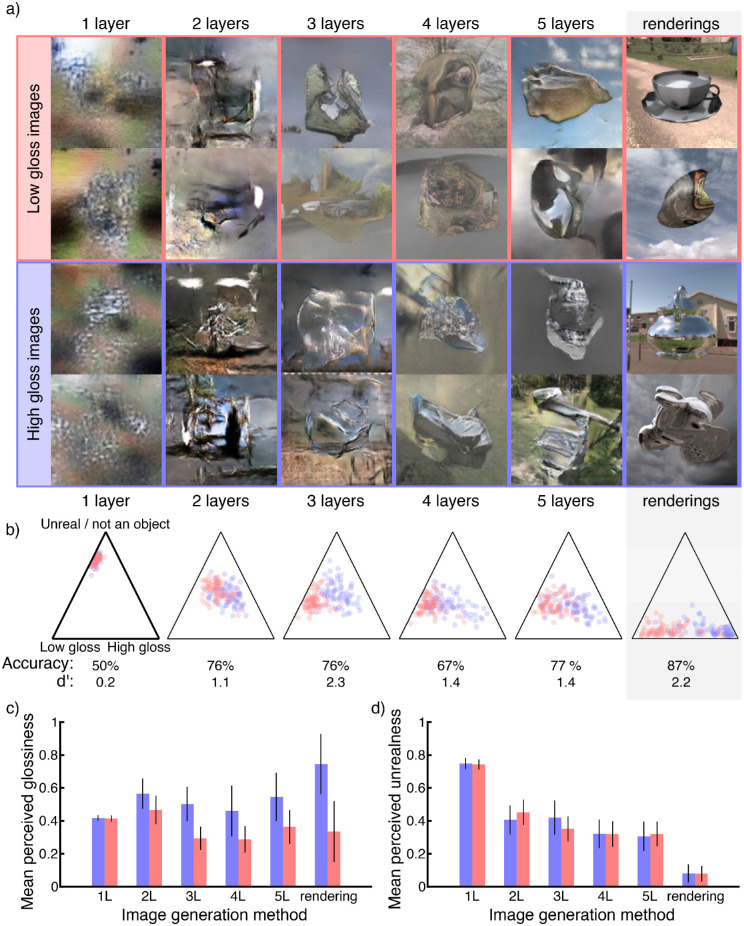
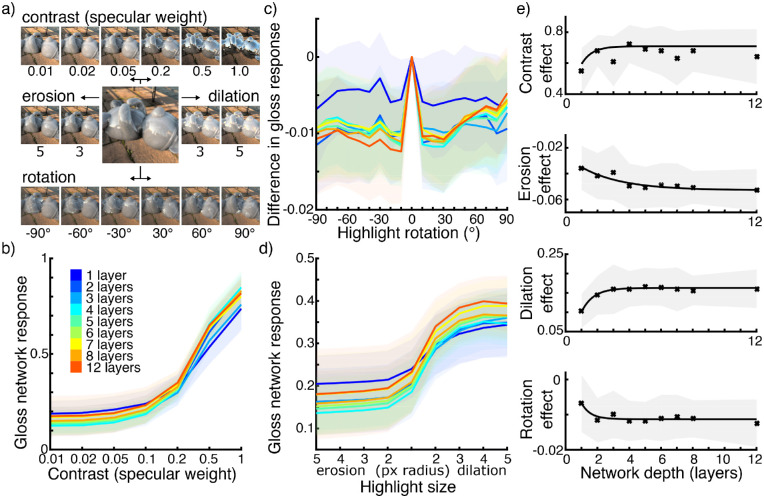
The visual computations underlying human gloss perception remain poorly understood, and to date there is no image-computable model that reproduces human gloss judgments independent of shape and viewing conditions. Such a model could provide a powerful platform for testing hypotheses about the detailed workings of surface perception. Here, we made use of recent developments in artificial neural networks to test how well we could recreate human responses in a high-gloss versus low-gloss discrimination task. We rendered >70,000 scenes depicting familiar objects made of either mirror-like or near-matte textured materials. We trained numerous classifiers to distinguish the two materials in our images-ranging from linear classifiers using simple pixel statistics to convolutional neural networks (CNNs) with up to 12 layers-and compared their classifications with human judgments. To determine which classifiers made the same kinds of errors as humans, we painstakingly identified a set of 60 images in which human judgments are consistently decoupled from ground truth. We then conducted a Bayesian hyperparameter search to identify which out of several thousand CNNs most resembled humans. We found that, although architecture has only a relatively weak effect, high correlations with humans are somewhat more typical in networks of shallower to intermediate depths (three to five layers). We also trained deep convolutional generative adversarial networks (DCGANs) of different depths to recreate images based on our high- and low-gloss database. Responses from human observers show that two layers in a DCGAN can recreate gloss recognizably for human observers. Together, our results indicate that human gloss classification can best be explained by computations resembling early to mid-level vision.
人类光泽感知的基础视觉计算仍然知之甚少,迄今为止,没有任何可计算图像的模型可以独立于形状和观察条件再现人类光泽判断。这样的模型可以为测试关于表面感知详细工作机制的假设提供一个强大的平台。在这里,我们利用人工神经网络的最新进展,测试我们在高光泽度与低光泽度区分任务中能够在多大程度上重现人类的反应。我们渲染了 >70,000 个场景,描绘了由类似镜子或近哑光纹理材料制成的熟悉物体。我们训练了许多分类器来区分我们图像中的两种材料——从使用简单像素统计信息的线性分类器到具有多达 12 层的卷积神经网络 (CNN)——并将它们的分类与人类判断进行比较。为了确定哪些分类器与人类犯了相同的错误,我们煞费苦心地确定了一组 60 张图像,在这些图像中,人类的判断与地面实况始终不一致。然后,我们进行了贝叶斯超参数搜索,以确定在数千个 CNN 中,哪一个最像人类。我们发现,尽管架构的影响相对较弱,但与人类的高相关性在较浅到中等深度(三到五层)的网络中更为典型。我们还训练了不同深度的深度卷积生成对抗网络 (DCGAN),根据我们的高光泽度和低光泽度数据库来重建图像。人类观察者的反应表明,DCGAN 中的两层可以为人类观察者可识别地重建光泽度。总之,我们的结果表明,人类光泽分类可以通过类似于早期到中期视觉的计算来最好地解释。