Observational Health Data Sciences and Informatics Community, New York, New York, USA
Epidemiology, Janssen Research and Development LLC, Raritan, New Jersey, USA.
BMJ Open. 2021 Dec 24;11(12):e050146. doi: 10.1136/bmjopen-2021-050146.
The internal validation of prediction models aims to quantify the generalisability of a model. We aim to determine the impact, if any, that the choice of development and internal validation design has on the internal performance bias and model generalisability in big data (n~500 000).
Retrospective cohort.
Primary and secondary care; three US claims databases.
1 200 769 patients pharmaceutically treated for their first occurrence of depression.
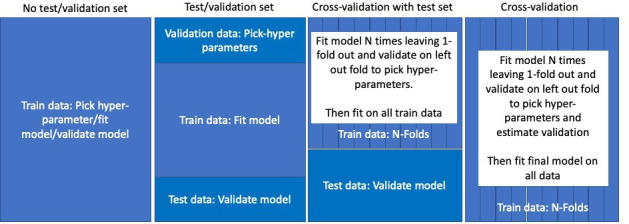
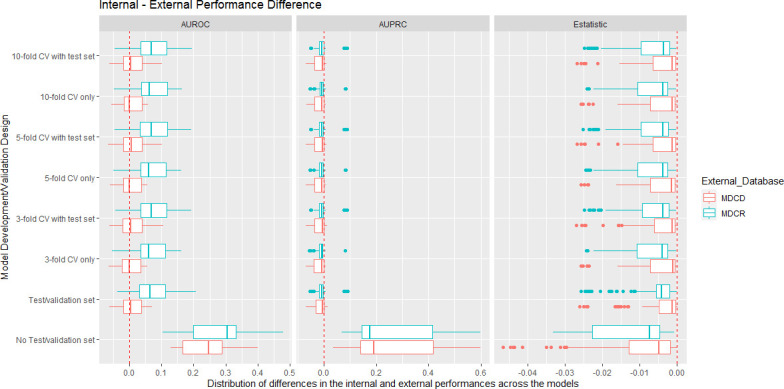
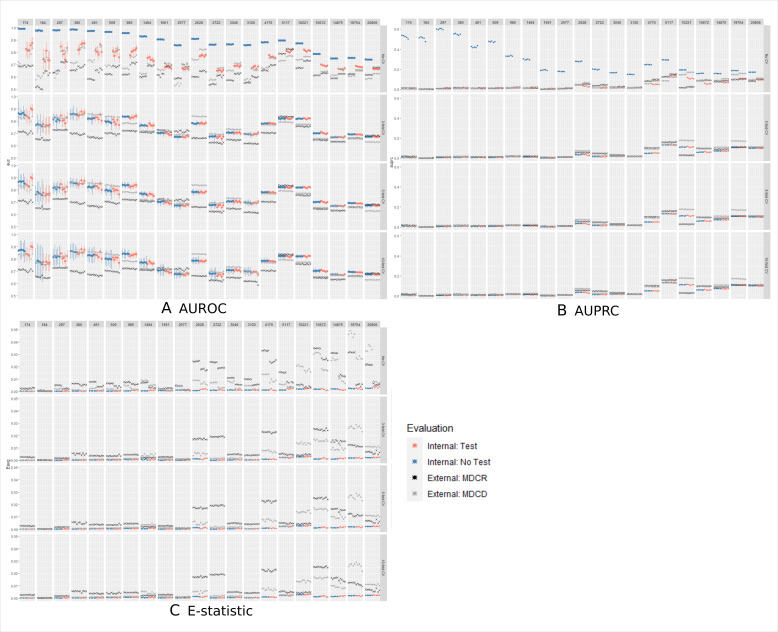
We investigated the impact of the development/validation design across 21 real-world prediction questions. Model discrimination and calibration were assessed. We trained LASSO logistic regression models using US claims data and internally validated the models using eight different designs: 'no test/validation set', 'test/validation set' and cross validation with 3-fold, 5-fold or 10-fold with and without a test set. We then externally validated each model in two new US claims databases. We estimated the internal validation bias per design by empirically comparing the differences between the estimated internal performance and external performance.
The differences between the models' internal estimated performances and external performances were largest for the 'no test/validation set' design. This indicates even with large data the 'no test/validation set' design causes models to overfit. The seven alternative designs included some validation process to select the hyperparameters and a fair testing process to estimate internal performance. These designs had similar internal performance estimates and performed similarly when externally validated in the two external databases.
Even with big data, it is important to use some validation process to select the optimal hyperparameters and fairly assess internal validation using a test set or cross-validation.
预测模型的内部验证旨在量化模型的通用性。我们旨在确定开发和内部验证设计的选择对大数据(n~500000)中模型内部性能偏差和通用性的影响。
回顾性队列。
初级和二级保健;三个美国索赔数据库。
1200769 名接受药物治疗首次出现抑郁症的患者。
我们调查了 21 个真实世界预测问题的开发/验证设计的影响。评估了模型的区分度和校准度。我们使用美国索赔数据训练了 LASSO 逻辑回归模型,并使用 8 种不同的设计进行了内部验证:“无测试/验证集”、“测试/验证集”和交叉验证,采用 3 折、5 折或 10 折,有无测试集。然后,我们在两个新的美国索赔数据库中对每个模型进行了外部验证。我们通过经验比较估计的内部性能和外部性能之间的差异,来估计每个设计的内部验证偏差。
“无测试/验证集”设计的模型内部估计性能与外部性能之间的差异最大。这表明,即使有大量数据,“无测试/验证集”设计也会导致模型过度拟合。其他 7 种设计包括一些验证过程来选择超参数,以及公平的测试过程来估计内部性能。这些设计具有相似的内部性能估计值,并且在两个外部数据库中进行外部验证时表现相似。
即使有大数据,使用一些验证过程来选择最优的超参数,并使用测试集或交叉验证公平地评估内部验证仍然很重要。