Gomez Christopher E, Sztainberg Marcelo O, Trana Rachel E
Department of Computer Science, Northeastern Illinois University, 5500 N St. Louis Ave, Chicago, IL 60625 USA.
Int J Bullying Prev. 2022;4(1):35-46. doi: 10.1007/s42380-021-00114-6. Epub 2021 Dec 22.
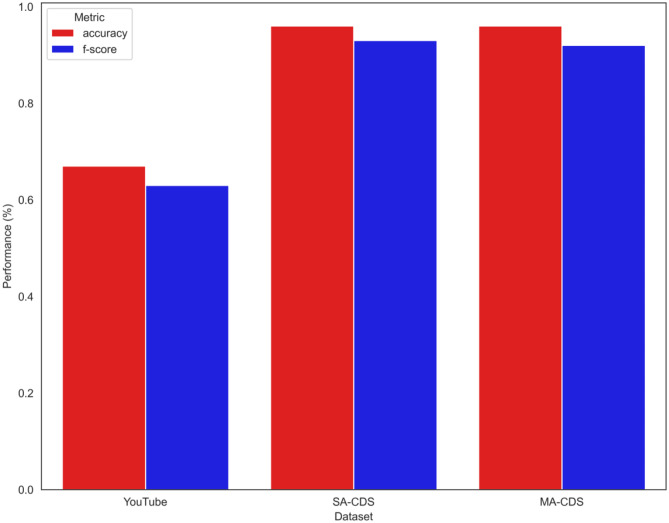
Cyberbullying is the use of digital communication tools and spaces to inflict physical, mental, or emotional distress. This serious form of aggression is frequently targeted at, but not limited to, vulnerable populations. A common problem when creating machine learning models to identify cyberbullying is the availability of accurately annotated, reliable, relevant, and diverse datasets. Datasets intended to train models for cyberbullying detection are typically annotated by human participants, which can introduce the following issues: (1) annotator bias, (2) incorrect annotation due to language and cultural barriers, and (3) the inherent subjectivity of the task can naturally create multiple valid labels for a given comment. The result can be a potentially inadequate dataset with one or more of these overlapping issues. We propose two machine learning approaches to identify and filter unambiguous comments in a cyberbullying dataset of roughly 19,000 comments collected from YouTube that was initially annotated using Amazon Mechanical Turk (AMT). Using consensus filtering methods, comments were classified as unambiguous when an agreement occurred between the AMT workers' majority label and the unanimous algorithmic filtering label. Comments identified as unambiguous were extracted and used to curate new datasets. We then used an artificial neural network to test for performance on these datasets. Compared to the original dataset, the classifier exhibits a large improvement in performance on modified versions of the dataset and can yield insight into the type of data that is consistently classified as bullying or non-bullying. This annotation approach can be expanded from cyberbullying datasets onto any classification corpus that has a similar complexity in scope.
网络欺凌是指利用数字通信工具和空间造成身体、心理或情感上的困扰。这种严重的攻击形式通常针对弱势群体,但不限于这些群体。在创建用于识别网络欺凌的机器学习模型时,一个常见问题是缺乏准确标注、可靠、相关且多样的数据集。用于训练网络欺凌检测模型的数据集通常由人类参与者进行标注,这可能会引发以下问题:(1)标注者偏差;(2)由于语言和文化障碍导致的错误标注;(3)任务本身的主观性自然会为给定评论产生多个有效标签。结果可能是一个存在上述一个或多个重叠问题的潜在不充分数据集。我们提出了两种机器学习方法,用于识别和筛选从YouTube收集的约19000条评论的网络欺凌数据集中的明确评论,该数据集最初是使用亚马逊土耳其机器人(AMT)进行标注的。使用共识过滤方法,当AMT工作者的多数标签与一致的算法过滤标签达成一致时,评论被分类为明确评论。被识别为明确的评论被提取出来用于整理新的数据集。然后我们使用人工神经网络在这些数据集上测试性能。与原始数据集相比,分类器在数据集的修改版本上表现出大幅性能提升,并且可以深入了解始终被分类为欺凌或非欺凌的数据类型。这种标注方法可以从网络欺凌数据集扩展到任何范围复杂度相似的分类语料库。