Oden Institute for Computational Engineering and Sciences, The University of Texas at Austin, Austin, Texas, United States of America.
Department of Molecular Biosciences, Center for Systems and Synthetic Biology, The University of Texas at Austin, Austin, Texas, United States of America.
PLoS One. 2021 Dec 31;16(12):e0262056. doi: 10.1371/journal.pone.0262056. eCollection 2021.
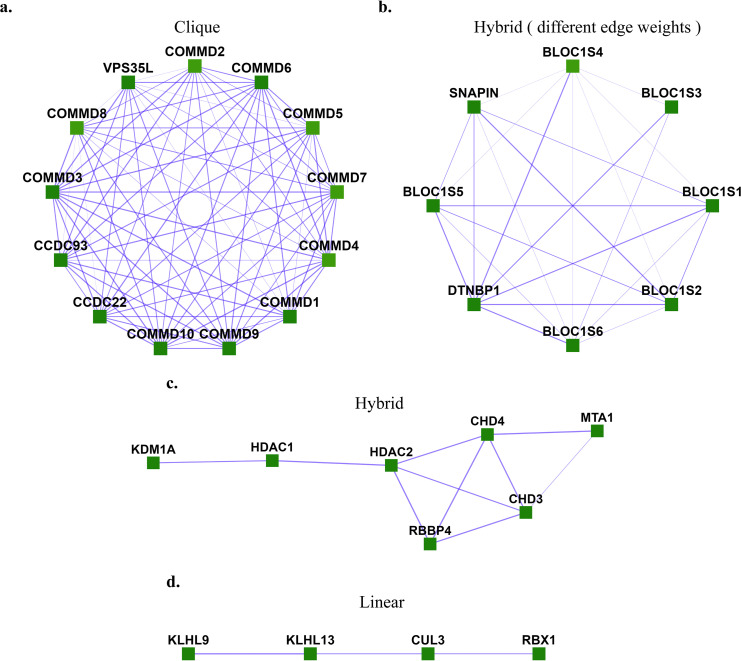
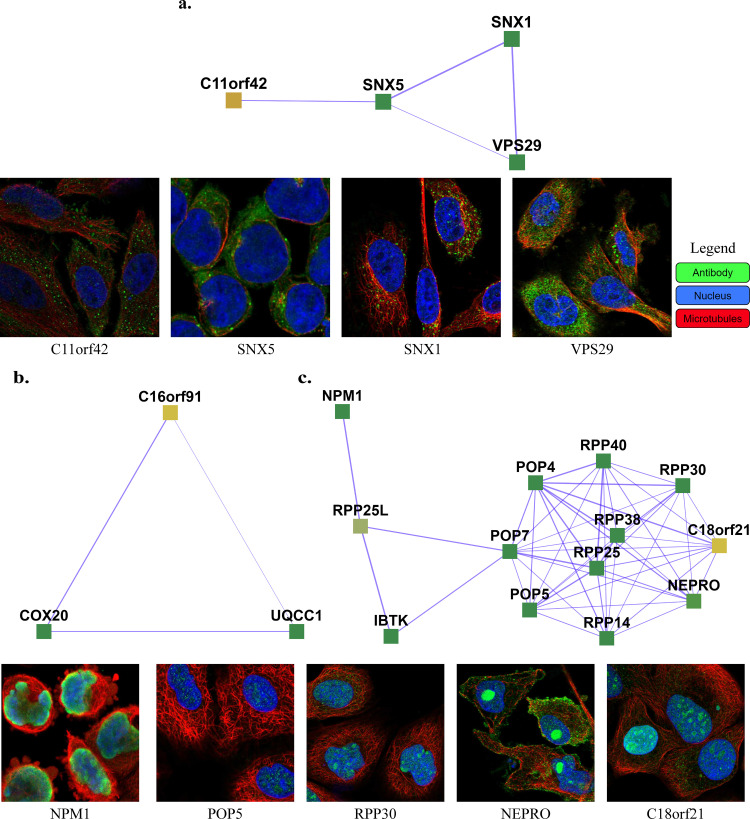
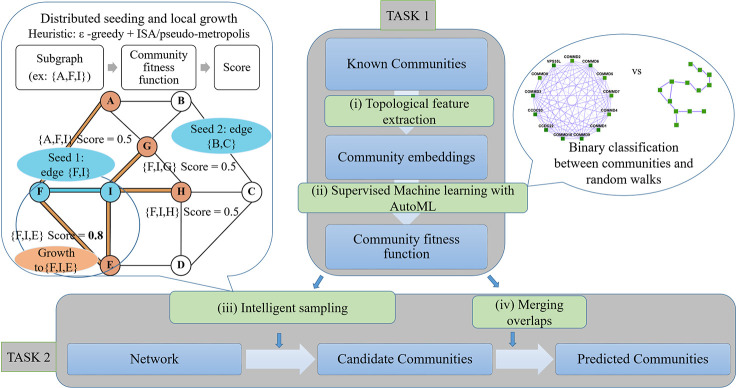
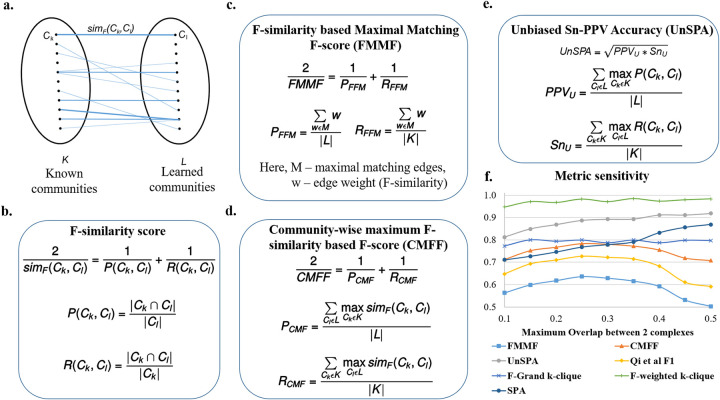
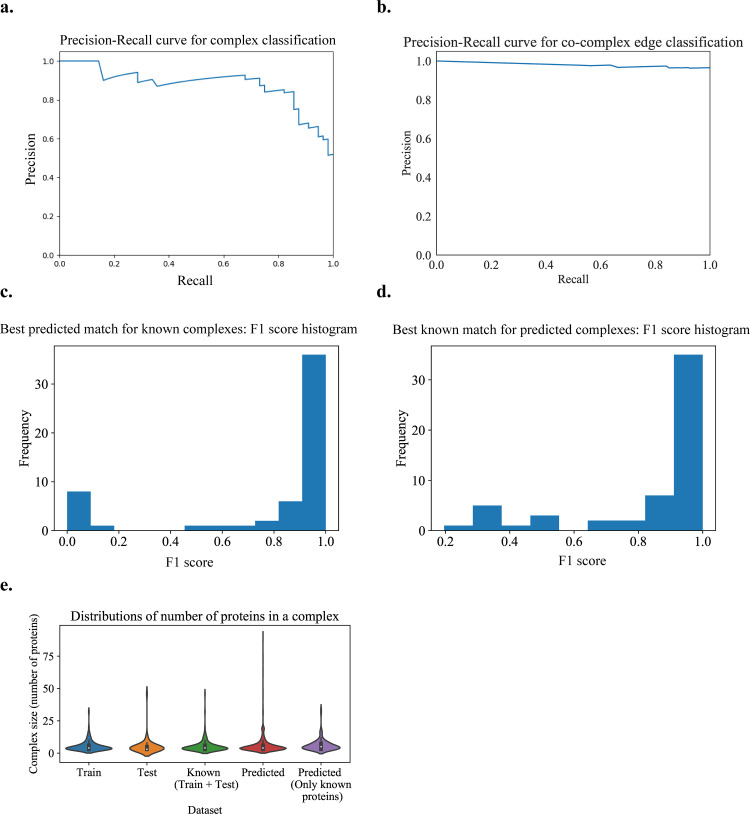
Characterization of protein complexes, i.e. sets of proteins assembling into a single larger physical entity, is important, as such assemblies play many essential roles in cells such as gene regulation. From networks of protein-protein interactions, potential protein complexes can be identified computationally through the application of community detection methods, which flag groups of entities interacting with each other in certain patterns. Most community detection algorithms tend to be unsupervised and assume that communities are dense network subgraphs, which is not always true, as protein complexes can exhibit diverse network topologies. The few existing supervised machine learning methods are serial and can potentially be improved in terms of accuracy and scalability by using better-suited machine learning models and parallel algorithms. Here, we present Super.Complex, a distributed, supervised AutoML-based pipeline for overlapping community detection in weighted networks. We also propose three new evaluation measures for the outstanding issue of comparing sets of learned and known communities satisfactorily. Super.Complex learns a community fitness function from known communities using an AutoML method and applies this fitness function to detect new communities. A heuristic local search algorithm finds maximally scoring communities, and a parallel implementation can be run on a computer cluster for scaling to large networks. On a yeast protein-interaction network, Super.Complex outperforms 6 other supervised and 4 unsupervised methods. Application of Super.Complex to a human protein-interaction network with ~8k nodes and ~60k edges yields 1,028 protein complexes, with 234 complexes linked to SARS-CoV-2, the COVID-19 virus, with 111 uncharacterized proteins present in 103 learned complexes. Super.Complex is generalizable with the ability to improve results by incorporating domain-specific features. Learned community characteristics can also be transferred from existing applications to detect communities in a new application with no known communities. Code and interactive visualizations of learned human protein complexes are freely available at: https://sites.google.com/view/supercomplex/super-complex-v3-0.
蛋白质复合物的特性,即组装成单个更大物理实体的蛋白质集合,非常重要,因为这些复合物在细胞中发挥着许多重要作用,如基因调控。从蛋白质-蛋白质相互作用网络中,可以通过应用社区检测方法计算识别潜在的蛋白质复合物,这些方法会标记以特定模式相互作用的实体组。大多数社区检测算法倾向于无监督,并且假设社区是密集的网络子图,但这并不总是正确的,因为蛋白质复合物可以表现出不同的网络拓扑结构。少数现有的监督机器学习方法是串行的,可以通过使用更适合的机器学习模型和并行算法来提高准确性和可扩展性。在这里,我们提出了 Super.Complex,这是一个用于加权网络中重叠社区检测的分布式、有监督的基于 AutoML 的流水线。我们还提出了三个新的评估指标,以解决比较学习社区和已知社区的出色问题。Super.Complex 使用 AutoML 方法从已知社区中学习社区适应度函数,并应用此适应度函数来检测新社区。启发式局部搜索算法找到得分最高的社区,并且可以在计算机集群上运行并行实现以扩展到大型网络。在酵母蛋白质相互作用网络上,Super.Complex 优于其他 6 种监督方法和 4 种无监督方法。将 Super.Complex 应用于包含约 8k 个节点和约 60k 条边的人类蛋白质相互作用网络,产生了 1028 个蛋白质复合物,其中 234 个复合物与 SARS-CoV-2(COVID-19 病毒)有关,103 个学习到的复合物中有 111 个未被表征的蛋白质。Super.Complex 具有通用性,可以通过结合特定于领域的特征来提高结果。还可以将学习到的社区特征从现有应用程序转移到新的无已知社区的应用程序中,以检测社区。学习到的人类蛋白质复合物的代码和交互式可视化可在以下网址免费获得:https://sites.google.com/view/supercomplex/super-complex-v3-0.