Anderson Tim, Wheeler Travis J
Department of Computer Science, University of Montana, Missoula, MT, USA.
Algorithms Mol Biol. 2021 Dec 31;16(1):25. doi: 10.1186/s13015-021-00204-6.
Pattern matching is a key step in a variety of biological sequence analysis pipelines. The FM-index is a compressed data structure for pattern matching, with search run time that is independent of the length of the database text. Implementation of the FM-index is reasonably complicated, so that increased adoption will be aided by the availability of a fast and flexible FM-index library.
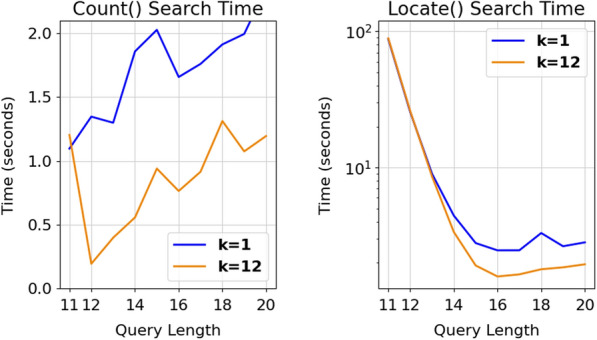
We present AvxWindowedFMindex (AWFM-index), a lightweight, open-source, thread-parallel FM-index library written in C that is optimized for indexing nucleotide and amino acid sequences. AWFM-index introduces a new approach to storing FM-index data in a strided bit-vector format that enables extremely efficient computation of the FM-index occurrence function via AVX2 bitwise instructions, and combines this with optional on-disk storage of the index's suffix array and a cache-efficient lookup table for partial k-mer searches. The AWFM-index performs exact match count and locate queries faster than SeqAn3's FM-index implementation across a range of comparable memory footprints. When optimized for speed, AWFM-index is [Formula: see text]2-4x faster than SeqAn3 for nucleotide search, and [Formula: see text]2-6x faster for amino acid search; it is also [Formula: see text]4x faster with similar memory footprint when storing the suffix array in on-disk SSD storage.
AWFM-index is easy to incorporate into bioinformatics software, offers run-time performance parameterization, and provides clients with FM-index functionality at both a high-level (count or locate all instances of a query string) and low-level (step-wise control of the FM-index backward-search process). The open-source library is available for download at https://github.com/TravisWheelerLab/AvxWindowFmIndex.
模式匹配是各种生物序列分析流程中的关键步骤。FM索引是一种用于模式匹配的压缩数据结构,其搜索运行时间与数据库文本的长度无关。FM索引的实现相当复杂,因此,一个快速且灵活的FM索引库将有助于其更广泛地被采用。
我们展示了AvxWindowedFMindex(AWFM索引),这是一个用C语言编写的轻量级、开源、线程并行的FM索引库,针对核苷酸和氨基酸序列索引进行了优化。AWFM索引引入了一种新方法,以跨步位向量格式存储FM索引数据,通过AVX2按位指令能够极其高效地计算FM索引出现函数,并将其与索引后缀数组的可选磁盘存储以及用于部分k-mer搜索的缓存高效查找表相结合。在一系列可比内存占用情况下,AWFM索引执行精确匹配计数和定位查询的速度比SeqAn3的FM索引实现更快。在针对速度进行优化时,对于核苷酸搜索,AWFM索引比SeqAn3快2至4倍,对于氨基酸搜索快2至6倍;当将后缀数组存储在磁盘固态硬盘中时,在类似内存占用情况下,它也快4倍。
AWFM索引易于整合到生物信息学软件中,提供运行时性能参数化,并在高级别(计数或定位查询字符串的所有实例)和低级别(FM索引反向搜索过程的逐步控制)为客户端提供FM索引功能。该开源库可在https://github.com/TravisWheelerLab/AvxWindowFmIndex下载。