Department of Epidemiology and Biostatistics, School of Public Health, Tehran University of Medical Sciences, P.O. Box 14155-6446, Tehran, Iran.
Prevention of Metabolic Disorders Research Center, Research Institute for Endocrine Sciences, Shahid Beheshti University of Medical Sciences, Tehran, Iran.
BMC Med Inform Decis Mak. 2022 Feb 10;22(1):36. doi: 10.1186/s12911-022-01775-z.
Early detection and prediction of type two diabetes mellitus incidence by baseline measurements could reduce associated complications in the future. The low incidence rate of diabetes in comparison with non-diabetes makes accurate prediction of minority diabetes class more challenging.
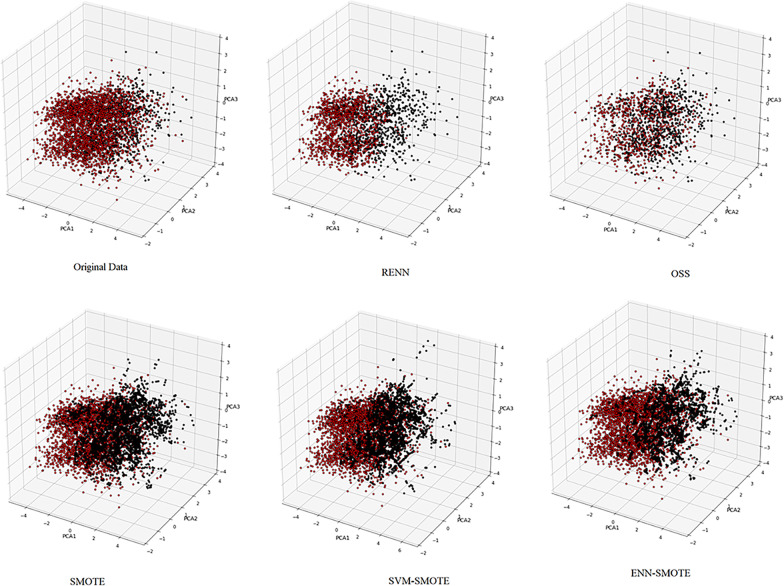
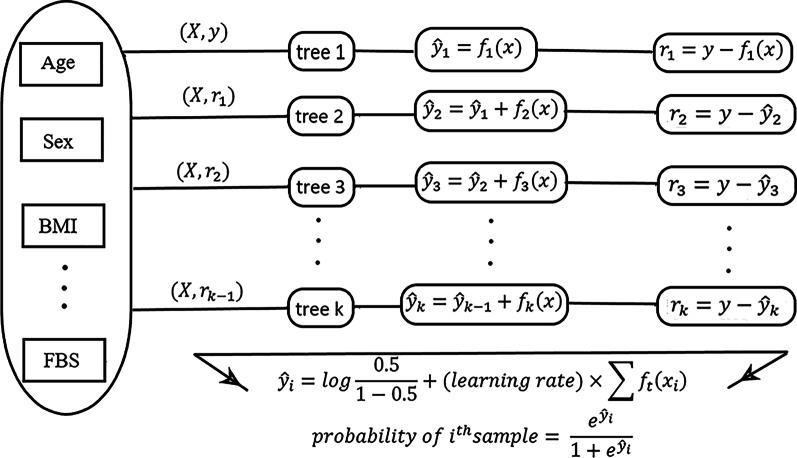
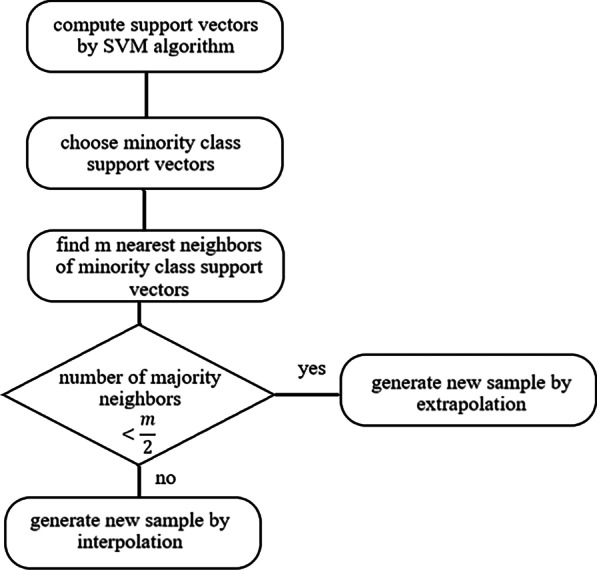
Deep neural network (DNN), extremely gradient boosting (XGBoost), and random forest (RF) performance is compared in predicting minority diabetes class in Tehran Lipid and Glucose Study (TLGS) cohort data. The impact of changing threshold, cost-sensitive learning, over and under-sampling strategies as solutions to class imbalance have been compared in improving algorithms performance.
DNN with the highest accuracy in predicting diabetes, 54.8%, outperformed XGBoost and RF in terms of AUROC, g-mean, and f1-measure in original imbalanced data. Changing threshold based on the maximum of f1-measure improved performance in g-mean, and f1-measure in three algorithms. Repeated edited nearest neighbors (RENN) under-sampling in DNN and cost-sensitive learning in tree-based algorithms were the best solutions to tackle the imbalance issue. RENN increased ROC and Precision-Recall AUCs, g-mean and f1-measure from 0.857, 0.603, 0.713, 0.575 to 0.862, 0.608, 0.773, 0.583, respectively in DNN. Weighing improved g-mean and f1-measure from 0.667, 0.554 to 0.776, 0.588 in XGBoost, and from 0.659, 0.543 to 0.775, 0.566 in RF, respectively. Also, ROC and Precision-Recall AUCs in RF increased from 0.840, 0.578 to 0.846, 0.591, respectively.
G-mean experienced the most increase by all imbalance solutions. Weighing and changing threshold as efficient strategies, in comparison with resampling methods are faster solutions to handle class imbalance. Among sampling strategies, under-sampling methods had better performance than others.
通过基线测量早期发现和预测 2 型糖尿病的发病率,可以减少未来的相关并发症。与非糖尿病相比,糖尿病的发病率较低,这使得少数糖尿病类别的准确预测更加具有挑战性。
在德黑兰血脂和血糖研究(TLGS)队列数据中,比较了深度神经网络(DNN)、极端梯度提升(XGBoost)和随机森林(RF)在预测少数糖尿病类别的性能。比较了改变阈值、代价敏感学习、过采样和欠采样策略作为解决类别不平衡的方法,以提高算法性能。
DNN 在预测糖尿病方面的准确率最高,为 54.8%,在原始不平衡数据中,其 AUROC、g-mean 和 f1-measure 均优于 XGBoost 和 RF。基于 f1-measure 的最大值改变阈值可提高三种算法的 g-mean 和 f1-measure。在 DNN 中使用重复编辑最近邻(RENN)欠采样和基于树的算法中的代价敏感学习是解决不平衡问题的最佳解决方案。RENN 增加了 DNN 的 ROC 和 Precision-Recall AUCs、g-mean 和 f1-measure,从 0.857、0.603、0.713 和 0.575 分别增加到 0.862、0.608、0.773 和 0.583。在 XGBoost 中,加权从 0.667、0.554 分别提高到 0.776、0.588,在 RF 中,从 0.659、0.543 分别提高到 0.775、0.566。此外,RF 的 ROC 和 Precision-Recall AUC 也分别从 0.840、0.578 增加到 0.846、0.591。
所有不平衡解决方案中,g-mean 的增幅最大。与重采样方法相比,加权和改变阈值是处理类别不平衡的更快速的解决方案。在采样策略中,欠采样方法的性能优于其他方法。