Bioinformatics Interdepartmental Program, University of California, Los Angeles, Los Angeles, CA 90095, USA.
Department of Computer Science, University of California, Los Angeles, Los Angeles, CA 90095, USA; Institute for Advanced Computer Studies, University of Maryland, College Park, College Park, MD 20742, USA.
Am J Hum Genet. 2022 Apr 7;109(4):727-737. doi: 10.1016/j.ajhg.2022.02.015. Epub 2022 Mar 16.
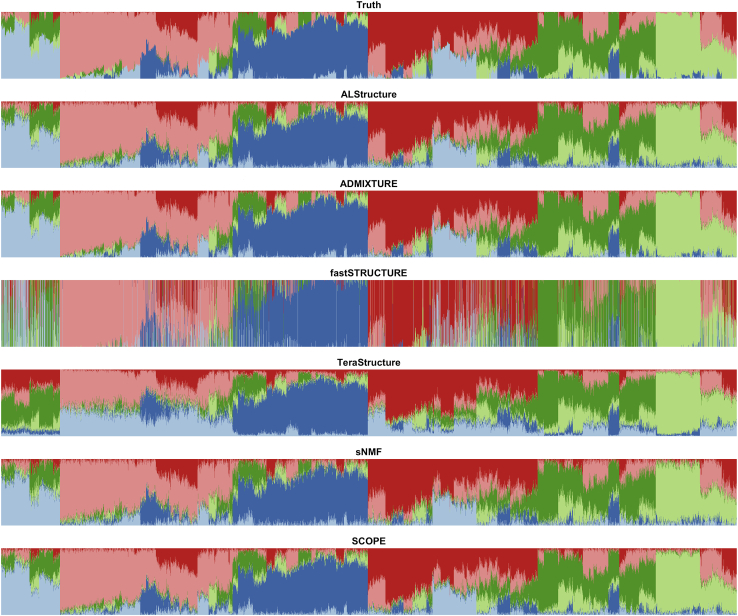
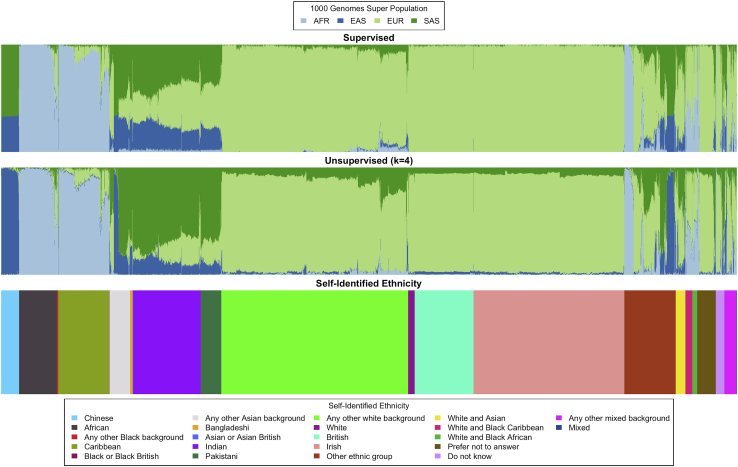
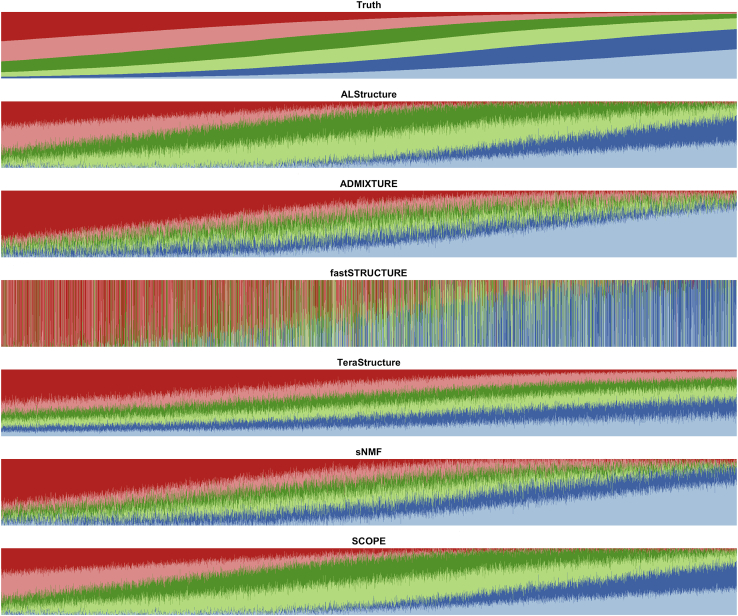
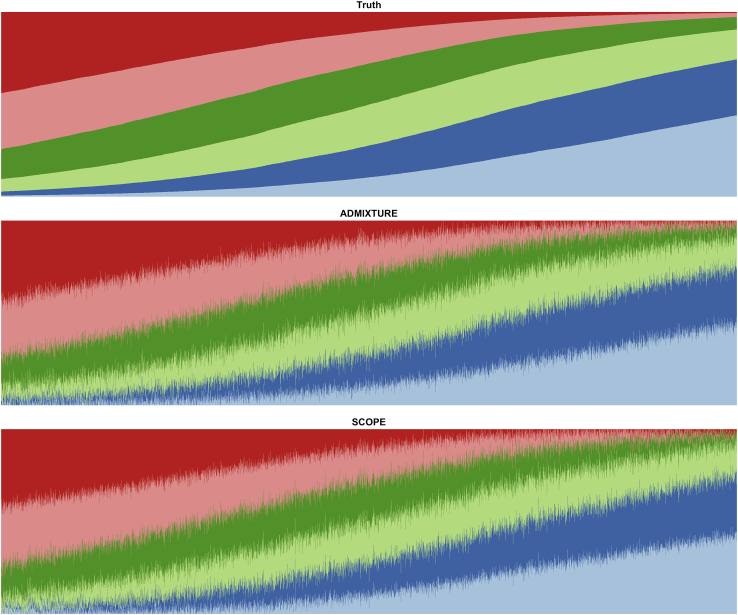
Inferring the structure of human populations from genetic variation data is a key task in population and medical genomic studies. Although a number of methods for population structure inference have been proposed, current methods are impractical to run on biobank-scale genomic datasets containing millions of individuals and genetic variants. We introduce SCOPE, a method for population structure inference that is orders of magnitude faster than existing methods while achieving comparable accuracy. SCOPE infers population structure in about a day on a dataset containing one million individuals and variants as well as on the UK Biobank dataset containing 488,363 individuals and 569,346 variants. Furthermore, SCOPE can leverage allele frequencies from previous studies to improve the interpretability of population structure estimates.
从遗传变异数据推断人类群体的结构是群体和医学基因组研究中的一项关键任务。尽管已经提出了许多用于群体结构推断的方法,但目前的方法在运行包含数百万个体和遗传变异的生物库规模基因组数据集时是不切实际的。我们引入了 SCOPE,这是一种比现有方法快几个数量级的群体结构推断方法,同时达到了相当的准确性。SCOPE 可以在一天内对包含一百万个个体和变体的数据集以及包含 488363 个人和 569346 个变体的 UK Biobank 数据集进行群体结构推断。此外,SCOPE 可以利用来自先前研究的等位基因频率来提高群体结构估计的可解释性。