Department of Computer Science Engineering & Information Technology, Jaypee Institute of Information Technology, A 10, Sector 62, Noida 201307, India.
School of Computer Science Engineering and Technology, Bennett University, Plot Nos 8-11, TechZone 2, Greater Noida 201310, India.
Sensors (Basel). 2022 Mar 19;22(6):2378. doi: 10.3390/s22062378.
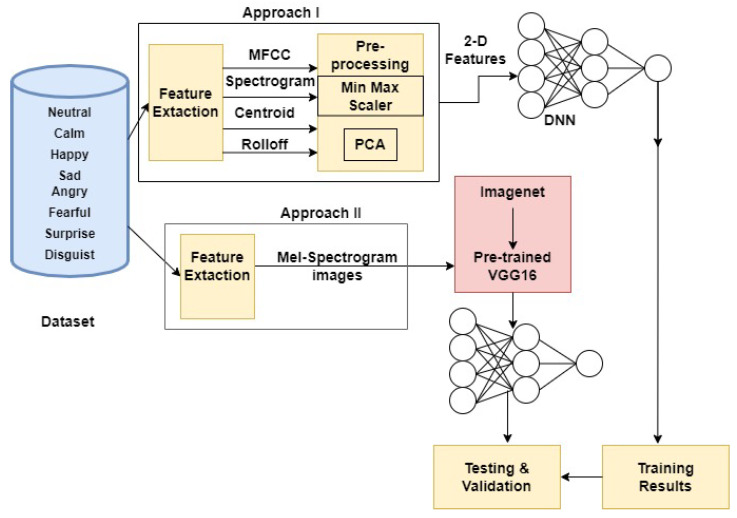
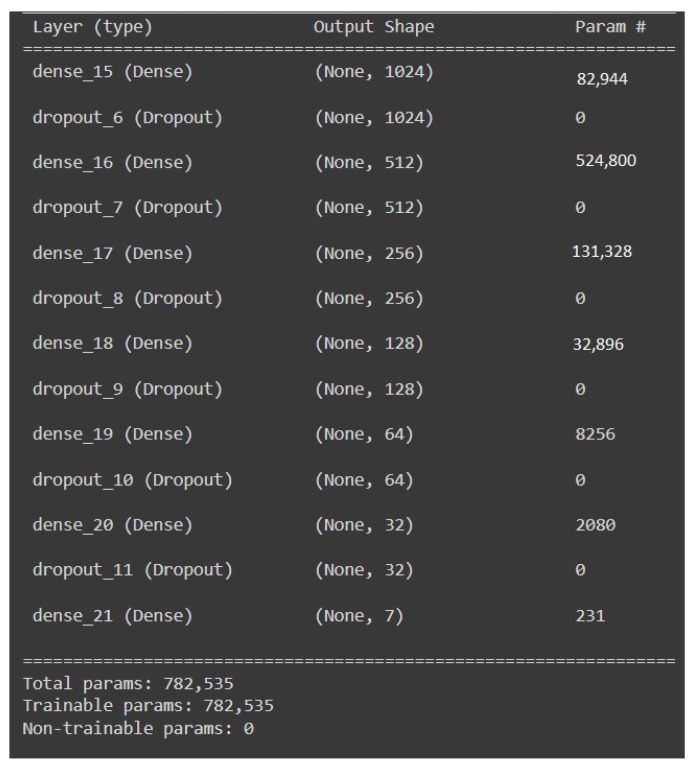
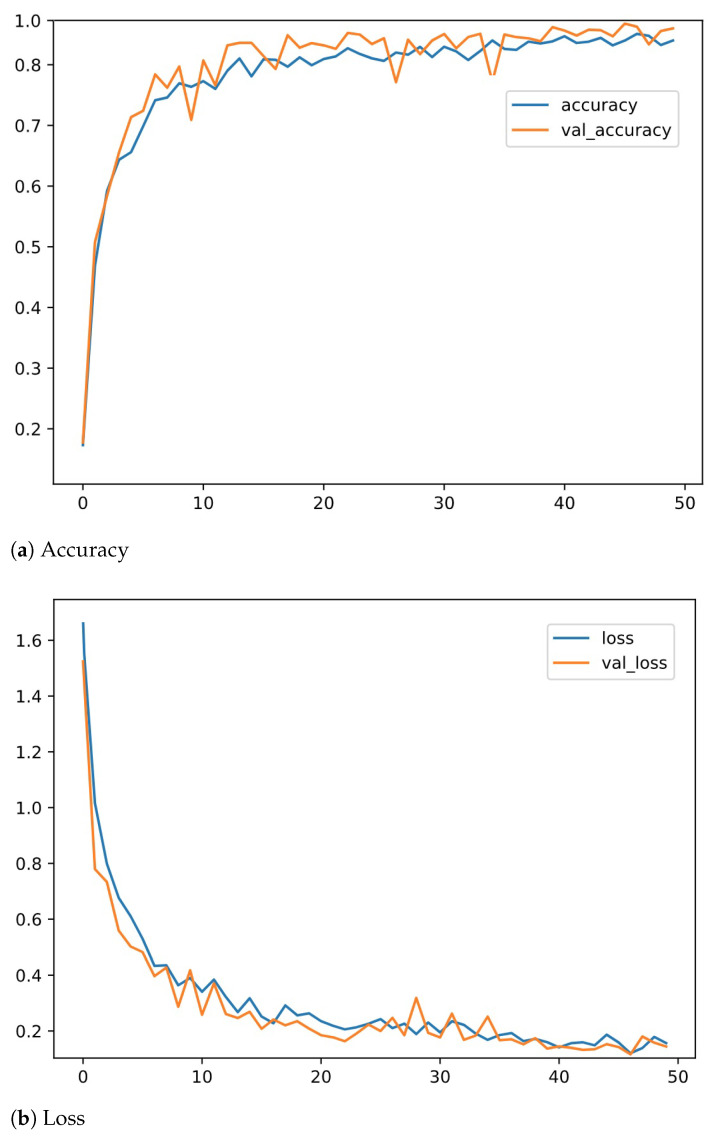
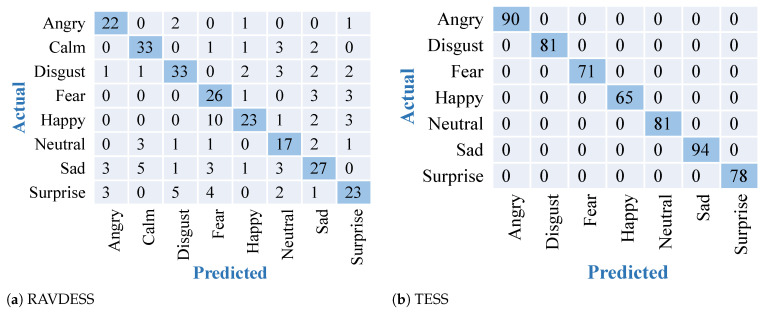
Recognizing human emotions by machines is a complex task. Deep learning models attempt to automate this process by rendering machines to exhibit learning capabilities. However, identifying human emotions from speech with good performance is still challenging. With the advent of deep learning algorithms, this problem has been addressed recently. However, most research work in the past focused on feature extraction as only one method for training. In this research, we have explored two different methods of extracting features to address effective speech emotion recognition. Initially, two-way feature extraction is proposed by utilizing super convergence to extract two sets of potential features from the speech data. For the first set of features, principal component analysis (PCA) is applied to obtain the first feature set. Thereafter, a deep neural network (DNN) with dense and dropout layers is implemented. In the second approach, mel-spectrogram images are extracted from audio files, and the 2D images are given as input to the pre-trained VGG-16 model. Extensive experiments and an in-depth comparative analysis over both the feature extraction methods with multiple algorithms and over two datasets are performed in this work. The RAVDESS dataset provided significantly better accuracy than using numeric features on a DNN.
机器识别人类情感是一项复杂的任务。深度学习模型试图通过使机器表现出学习能力来自动化这个过程。然而,要从语音中识别出人类的情感并取得良好的性能仍然具有挑战性。随着深度学习算法的出现,这个问题最近得到了解决。然而,过去大多数研究工作都集中在特征提取上,只是作为训练的一种方法。在这项研究中,我们探索了两种不同的特征提取方法来解决有效的语音情感识别问题。最初,通过利用超收敛性,从语音数据中提取两组潜在特征,提出了双向特征提取。对于第一组特征,应用主成分分析 (PCA) 以获得第一组特征集。然后,实现了具有密集和辍学层的深度神经网络 (DNN)。在第二种方法中,从音频文件中提取梅尔频谱图图像,并将二维图像作为输入提供给预先训练的 VGG-16 模型。在这项工作中,对这两种特征提取方法进行了广泛的实验和深入的比较分析,并使用多个算法和两个数据集进行了比较。RAVDESS 数据集在 DNN 上使用数字特征时提供了显著更好的准确性。