Wireless Communication Ecosystem Research Unit, Department of Electrical Engineering, Chulalongkorn University, Bangkok 10330, Thailand.
Department of Electrical Engineering, Main Campus, University of Science & Technology, Bannu 28100, Pakistan.
Sensors (Basel). 2023 Jul 7;23(13):6212. doi: 10.3390/s23136212.
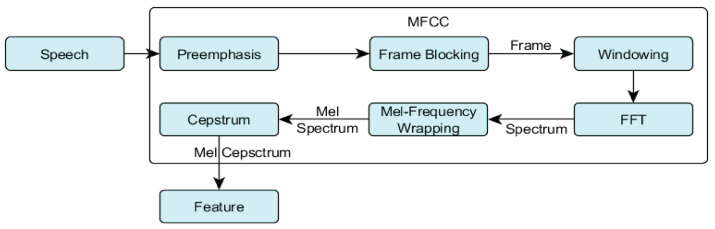
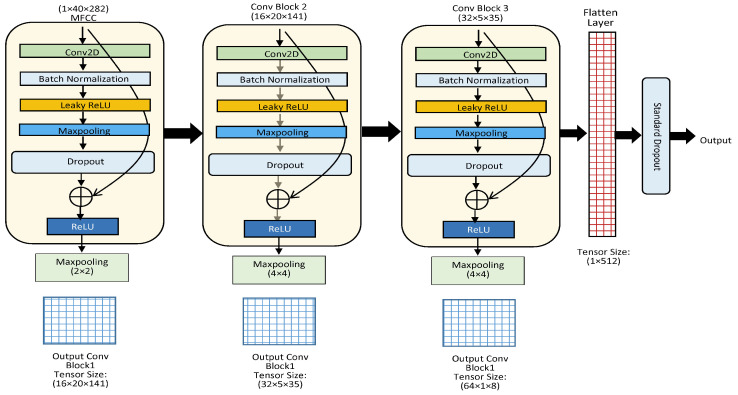
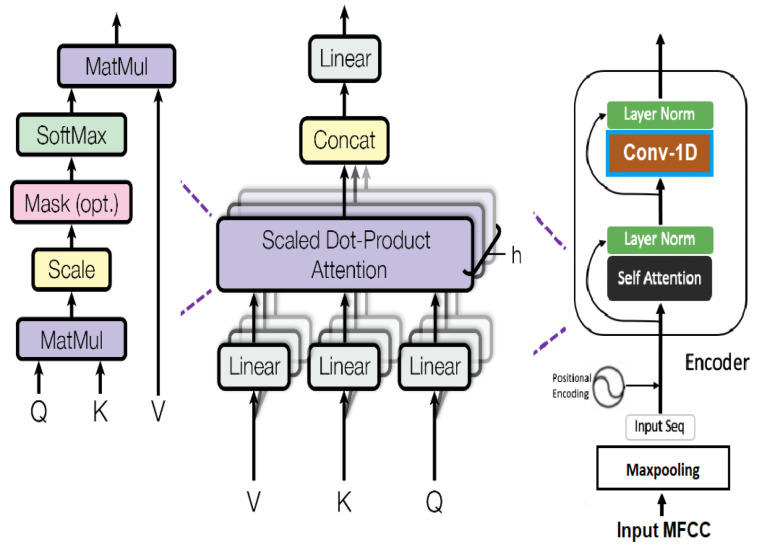
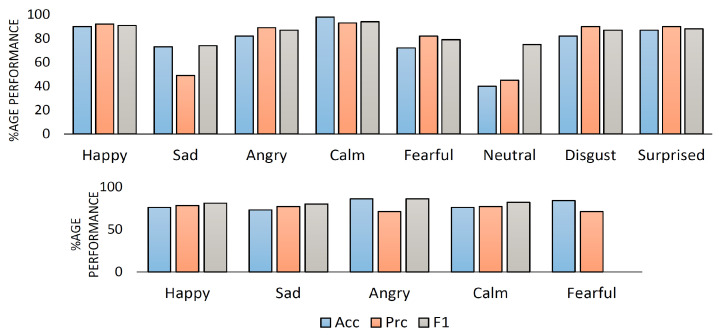
Speech emotion recognition (SER) is a challenging task in human-computer interaction (HCI) systems. One of the key challenges in speech emotion recognition is to extract the emotional features effectively from a speech utterance. Despite the promising results of recent studies, they generally do not leverage advanced fusion algorithms for the generation of effective representations of emotional features in speech utterances. To address this problem, we describe the fusion of spatial and temporal feature representations of speech emotion by parallelizing convolutional neural networks (CNNs) and a Transformer encoder for SER. We stack two parallel CNNs for spatial feature representation in parallel to a Transformer encoder for temporal feature representation, thereby simultaneously expanding the filter depth and reducing the feature map with an expressive hierarchical feature representation at a lower computational cost. We use the RAVDESS dataset to recognize eight different speech emotions. We augment and intensify the variations in the dataset to minimize model overfitting. Additive White Gaussian Noise (AWGN) is used to augment the RAVDESS dataset. With the spatial and sequential feature representations of CNNs and the Transformer, the SER model achieves 82.31% accuracy for eight emotions on a hold-out dataset. In addition, the SER system is evaluated with the IEMOCAP dataset and achieves 79.42% recognition accuracy for five emotions. Experimental results on the RAVDESS and IEMOCAP datasets show the success of the presented SER system and demonstrate an absolute performance improvement over the state-of-the-art (SOTA) models.
语音情感识别(SER)是人机交互(HCI)系统中的一项具有挑战性的任务。在语音情感识别中,一个关键挑战是从语音话语中有效地提取情感特征。尽管最近的研究取得了有希望的结果,但它们通常没有利用先进的融合算法来生成语音话语中情感特征的有效表示。为了解决这个问题,我们描述了通过并行化卷积神经网络(CNN)和 Transformer 编码器来融合语音情感的空间和时间特征表示。我们并行堆叠两个用于空间特征表示的并行 CNN 以及一个用于时间特征表示的 Transformer 编码器,从而同时扩展滤波器深度并降低特征图的表示,同时以较低的计算成本实现具有表现力的分层特征表示。我们使用 RAVDESS 数据集来识别八种不同的语音情感。我们通过添加加性白高斯噪声(AWGN)来扩充 RAVDESS 数据集,并强化数据集的变化,以最大限度地减少模型过拟合。使用 CNN 的空间和顺序特征表示以及 Transformer,SER 模型在验证数据集上对八种情感的准确率达到 82.31%。此外,该 SER 系统还在 IEMOCAP 数据集上进行了评估,对五种情感的识别准确率达到 79.42%。在 RAVDESS 和 IEMOCAP 数据集上的实验结果表明了所提出的 SER 系统的成功,并证明了相对于最先进(SOTA)模型的绝对性能提升。