Hu Danqing, Li Shaolei, Zhang Huanyao, Wu Nan, Lu Xudong
College of Biomedical Engineering and Instrumental Science, Zhejiang University, Hangzhou, China.
Department of Thoracic Surgery II, Peking University Cancer Hospital and Institute, Beijing, China.
JMIR Med Inform. 2022 Apr 25;10(4):e35475. doi: 10.2196/35475.
Lymph node metastasis (LNM) is critical for treatment decision making of patients with resectable non-small cell lung cancer, but it is difficult to precisely diagnose preoperatively. Electronic medical records (EMRs) contain a large volume of valuable information about LNM, but some key information is recorded in free text, which hinders its secondary use.
This study aims to develop LNM prediction models based on EMRs using natural language processing (NLP) and machine learning algorithms.
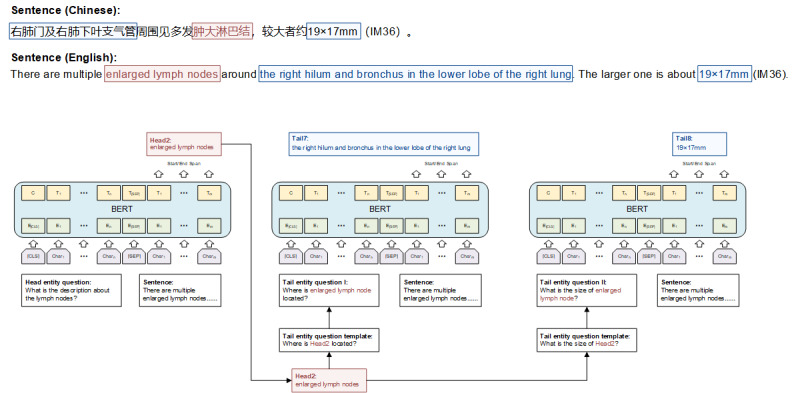
We developed a multiturn question answering NLP model to extract features about the primary tumor and lymph nodes from computed tomography (CT) reports. We then combined these features with other structured clinical characteristics to develop LNM prediction models using machine learning algorithms. We conducted extensive experiments to explore the effectiveness of the predictive models and compared them with size criteria based on CT image findings (the maximum short axis diameter of lymph node >10 mm was regarded as a metastatic node) and clinician's evaluation. Since the NLP model may extract features with mistakes, we also calculated the concordance correlation between the predicted probabilities of models using NLP-extracted features and gold standard features to explore the influence of NLP-driven automatic extraction.
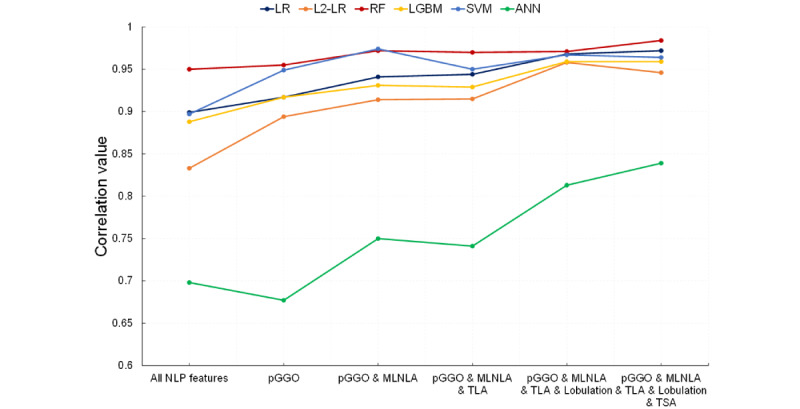
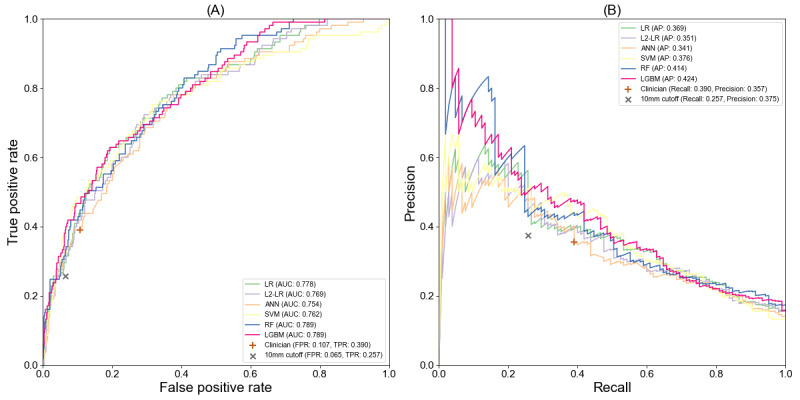
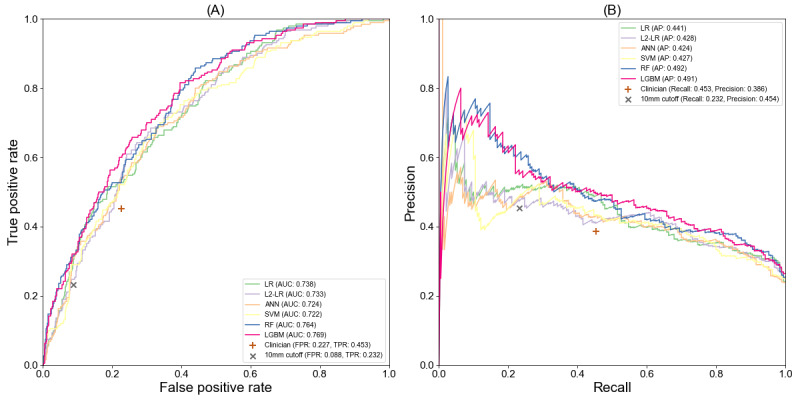
Experimental results show that the random forest models achieved the best performances with 0.792 area under the receiver operating characteristic curve (AUC) value and 0.456 average precision (AP) value for pN2 LNM prediction and 0.768 AUC value and 0.524 AP value for pN1&N2 LNM prediction. And all machine learning models outperformed the size criteria and clinician's evaluation. The concordance correlation between the random forest models using NLP-extracted features and gold standard features is 0.950 and improved to 0.984 when the top 5 important NLP-extracted features were replaced with gold standard features.
The LNM models developed can achieve competitive performance using only limited EMR data such as CT reports and tumor markers in comparison with the clinician's evaluation. The multiturn question answering NLP model can extract features effectively to support the development of LNM prediction models, which may facilitate the clinical application of predictive models.
淋巴结转移(LNM)对于可切除的非小细胞肺癌患者的治疗决策至关重要,但术前精确诊断较为困难。电子病历(EMR)包含大量有关LNM的有价值信息,但一些关键信息以自由文本形式记录,这阻碍了其二次利用。
本研究旨在使用自然语言处理(NLP)和机器学习算法,基于EMR开发LNM预测模型。
我们开发了一个多轮问答NLP模型,以从计算机断层扫描(CT)报告中提取有关原发性肿瘤和淋巴结的特征。然后,我们将这些特征与其他结构化临床特征相结合,使用机器学习算法开发LNM预测模型。我们进行了广泛的实验,以探索预测模型的有效性,并将其与基于CT图像结果的大小标准(淋巴结最大短轴直径>10mm被视为转移淋巴结)和临床医生的评估进行比较。由于NLP模型可能会错误地提取特征,我们还计算了使用NLP提取特征的模型预测概率与金标准特征之间的一致性相关性,以探索NLP驱动的自动提取的影响。
实验结果表明,随机森林模型在预测pN2 LNM时,受试者工作特征曲线(AUC)下面积为0.792,平均精度(AP)值为0.456;在预测pN1&N2 LNM时,AUC值为0.768,AP值为0.524,表现最佳。所有机器学习模型均优于大小标准和临床医生的评估。使用NLP提取特征的随机森林模型与金标准特征之间的一致性相关性为0.950,当用金标准特征替换前5个重要的NLP提取特征时,一致性相关性提高到0.984。
与临床医生的评估相比,开发的LNM模型仅使用有限的EMR数据(如CT报告和肿瘤标志物)就能实现有竞争力的性能。多轮问答NLP模型可以有效地提取特征,以支持LNM预测模型的开发,这可能有助于预测模型的临床应用。