In Silico Toxicology and Structural Bioinformatics, Institute of Physiology, Charité Universitätsmedizin Berlin, Berlin, 10117, Germany.
BASF SE, 67056, Ludwigshafen, Germany.
Sci Rep. 2022 May 4;12(1):7244. doi: 10.1038/s41598-022-09309-3.
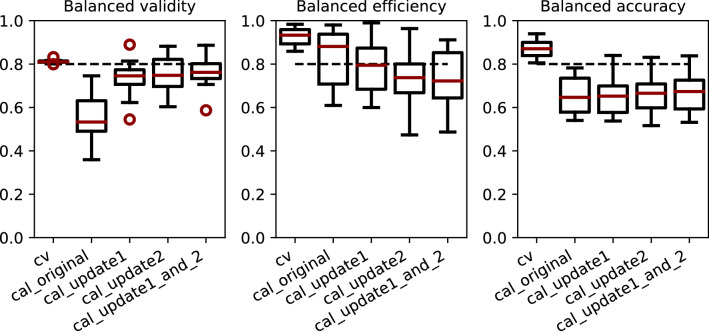
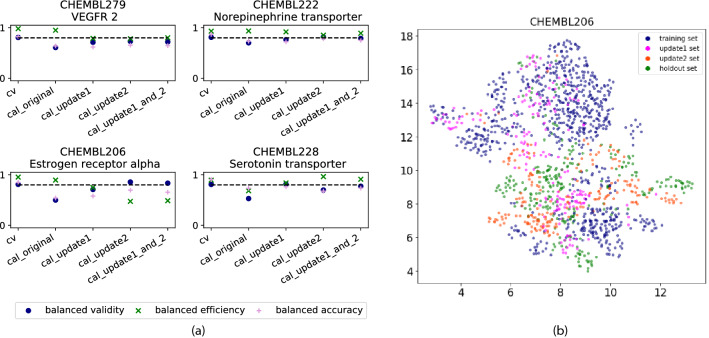
Machine learning models are widely applied to predict molecular properties or the biological activity of small molecules on a specific protein. Models can be integrated in a conformal prediction (CP) framework which adds a calibration step to estimate the confidence of the predictions. CP models present the advantage of ensuring a predefined error rate under the assumption that test and calibration set are exchangeable. In cases where the test data have drifted away from the descriptor space of the training data, or where assay setups have changed, this assumption might not be fulfilled and the models are not guaranteed to be valid. In this study, the performance of internally valid CP models when applied to either newer time-split data or to external data was evaluated. In detail, temporal data drifts were analysed based on twelve datasets from the ChEMBL database. In addition, discrepancies between models trained on publicly-available data and applied to proprietary data for the liver toxicity and MNT in vivo endpoints were investigated. In most cases, a drastic decrease in the validity of the models was observed when applied to the time-split or external (holdout) test sets. To overcome the decrease in model validity, a strategy for updating the calibration set with data more similar to the holdout set was investigated. Updating the calibration set generally improved the validity, restoring it completely to its expected value in many cases. The restored validity is the first requisite for applying the CP models with confidence. However, the increased validity comes at the cost of a decrease in model efficiency, as more predictions are identified as inconclusive. This study presents a strategy to recalibrate CP models to mitigate the effects of data drifts. Updating the calibration sets without having to retrain the model has proven to be a useful approach to restore the validity of most models.
机器学习模型被广泛应用于预测小分子在特定蛋白质上的分子性质或生物活性。模型可以集成到保角预测(CP)框架中,该框架增加了一个校准步骤来估计预测的置信度。CP 模型的优点是在假设测试集和校准集可交换的情况下,保证了预定的错误率。在测试数据已经偏离训练数据的描述符空间的情况下,或者在测定方案发生变化的情况下,这种假设可能不成立,并且模型不一定有效。在这项研究中,评估了应用于新时间分割数据或外部数据的内部有效的 CP 模型的性能。具体来说,基于来自 ChEMBL 数据库的十二个数据集分析了时间数据漂移。此外,还研究了在肝毒性和 MNT 体内终点上,基于公开可用数据训练的模型应用于专有数据时的模型之间的差异。在大多数情况下,当应用于时间分割或外部(保留)测试集时,模型的有效性会急剧下降。为了克服模型有效性的下降,研究了一种使用与保留集更相似的数据更新校准集的策略。更新校准集通常会提高有效性,在许多情况下完全恢复到预期值。恢复的有效性是自信地应用 CP 模型的首要前提。然而,有效性的提高是以模型效率的降低为代价的,因为更多的预测被认为是不确定的。本研究提出了一种重新校准 CP 模型以减轻数据漂移影响的策略。无需重新训练模型即可更新校准集已被证明是恢复大多数模型有效性的有用方法。