Control Engineering College, Army Engineering University of PLA, Nanjing 210007, China.
Beijing Information and Communications Technology Research Center, Beijing 100036, China.
Sensors (Basel). 2022 Apr 26;22(9):3320. doi: 10.3390/s22093320.
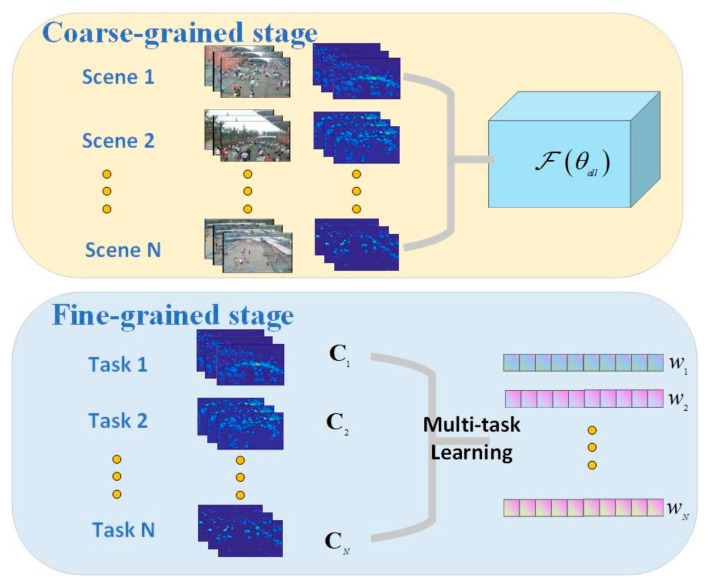
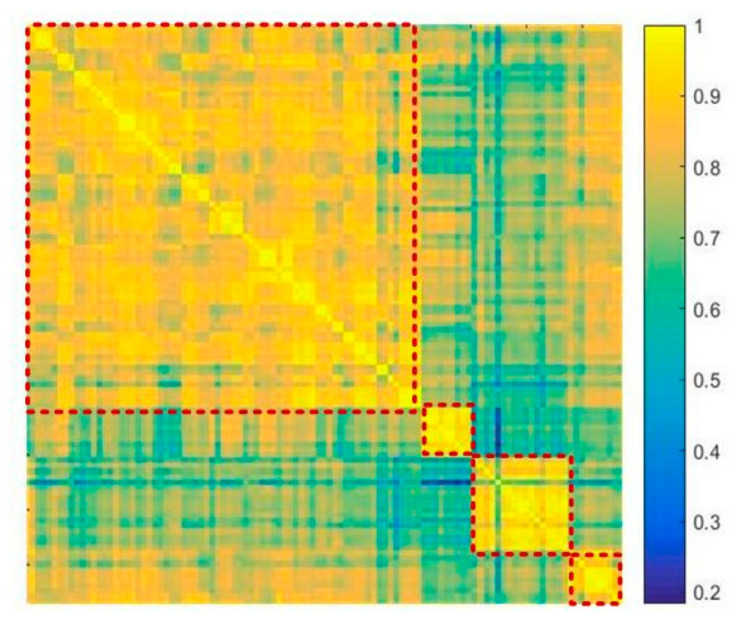
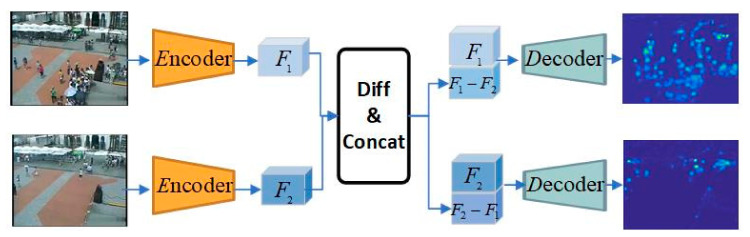
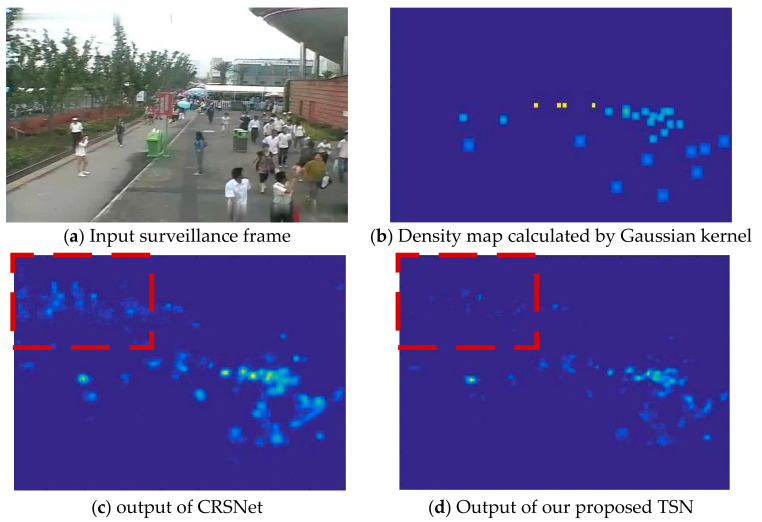
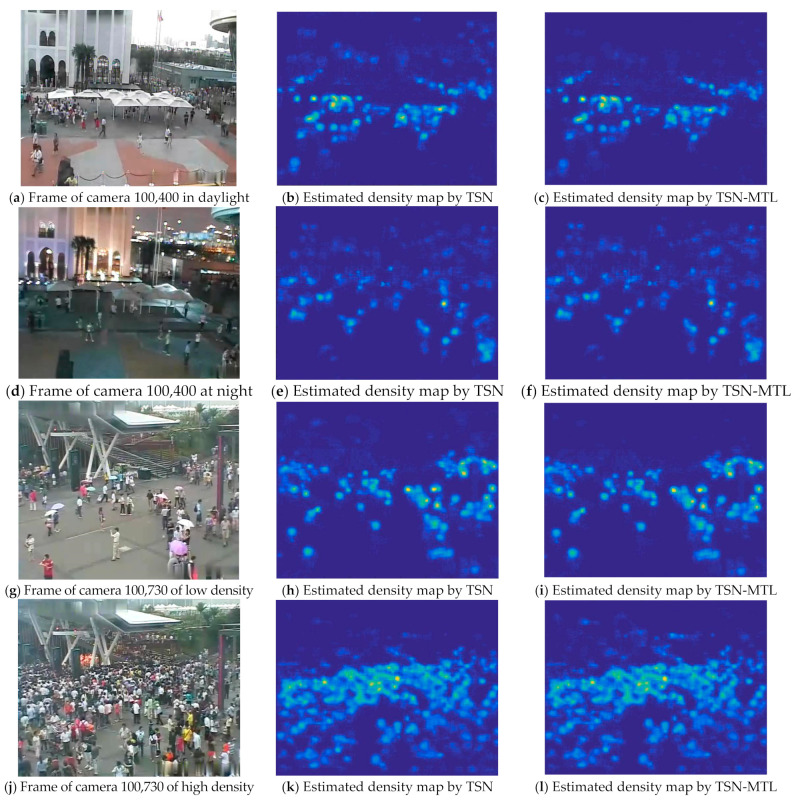
In this paper, we propose a multi-scene adaptive crowd counting method based on meta-knowledge and multi-task learning. In practice, surveillance cameras are stationarily deployed in various scenes. Considering the extensibility of a surveillance system, the ideal crowd counting method should have a strong generalization capability to be deployed in unknown scenes. On the other hand, given the diversity of scenes, it should also effectively suit each scene for better performance. These two objectives are contradictory, so we propose a coarse-to-fine pipeline including meta-knowledge network and multi-task learning. Specifically, at the coarse-grained stage, we propose a generic two-stream network for all existing scenes to encode meta-knowledge especially inter-frame temporal knowledge. At the fine-grained stage, the regression of the crowd density map to the overall number of people in each scene is considered a homogeneous subtask in a multi-task framework. A robust multi-task learning algorithm is applied to effectively learn scene-specific regression parameters for existing and new scenes, which further improve the accuracy of each specific scenes. Taking advantage of multi-task learning, the proposed method can be deployed to multiple new scenes without duplicated model training. Compared with two representative methods, namely AMSNet and MAML-counting, the proposed method reduces the MAE by 10.29% and 13.48%, respectively.
在本文中,我们提出了一种基于元知识和多任务学习的多场景自适应人群计数方法。在实践中,监控摄像机通常部署在各种场景中。考虑到监控系统的可扩展性,理想的人群计数方法应该具有很强的泛化能力,以便部署在未知场景中。另一方面,鉴于场景的多样性,它也应该能够有效地适应每个场景,以获得更好的性能。这两个目标是相互矛盾的,因此我们提出了一个粗到细的流水线,包括元知识网络和多任务学习。具体来说,在粗粒度阶段,我们为所有现有场景提出了一个通用的双流网络,以编码元知识,特别是帧间时间知识。在细粒度阶段,将人群密度图回归到每个场景中的总人数视为多任务框架中的一个同质子任务。应用一种稳健的多任务学习算法来有效地学习现有和新场景的特定场景回归参数,从而进一步提高每个特定场景的准确性。利用多任务学习,所提出的方法可以部署到多个新场景,而无需重复模型训练。与两个有代表性的方法,即 AMSNet 和 MAML-counting 相比,所提出的方法分别将 MAE 降低了 10.29%和 13.48%。