Ampong Isaac, Zimmerman Kip D, Nathanielsz Peter W, Cox Laura A, Olivier Michael
Center for Precision Medicine, Department of Internal Medicine, Section on Molecular Medicine, Wake Forest University, Winston-Salem, NC 27157, USA.
Center for the Study of Fetal Programming, University of Wyoming, Laramie, WY 82071, USA.
Metabolites. 2022 May 11;12(5):429. doi: 10.3390/metabo12050429.
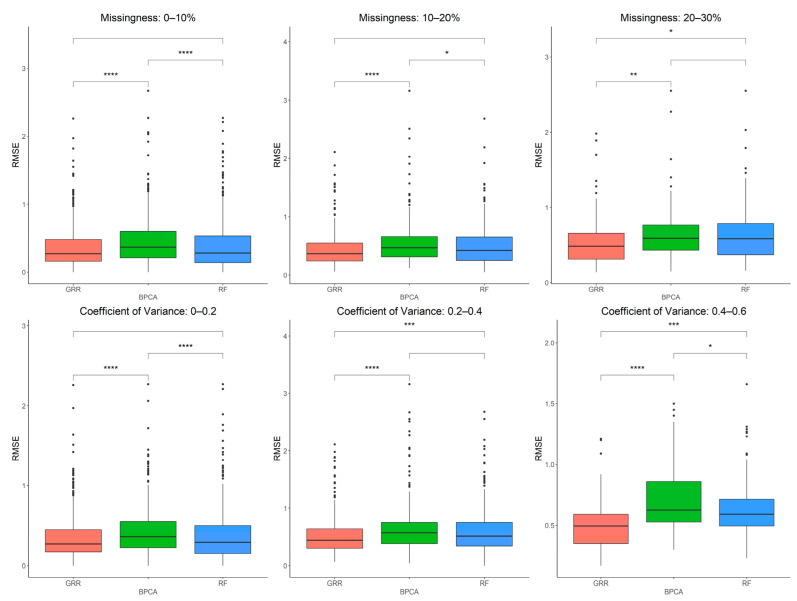
Gas chromatography-coupled mass spectrometry (GC-MS) has been used in biomedical research to analyze volatile, non-polar, and polar metabolites in a wide array of sample types. Despite advances in technology, missing values are still common in metabolomics datasets and must be properly handled. We evaluated the performance of ten commonly used missing value imputation methods with metabolites analyzed on an HR GC-MS instrument. By introducing missing values into the complete (i.e., data without any missing values) National Institute of Standards and Technology (NIST) plasma dataset, we demonstrate that random forest (RF), glmnet ridge regression (GRR), and Bayesian principal component analysis (BPCA) shared the lowest root mean squared error (RMSE) in technical replicate data. Further examination of these three methods in data from baboon plasma and liver samples demonstrated they all maintained high accuracy. Overall, our analysis suggests that any of the three imputation methods can be applied effectively to untargeted metabolomics datasets with high accuracy. However, it is important to note that imputation will alter the correlation structure of the dataset and bias downstream regression coefficients and -values.
气相色谱-质谱联用(GC-MS)已用于生物医学研究,以分析多种样本类型中的挥发性、非极性和极性代谢物。尽管技术有所进步,但代谢组学数据集中缺失值仍然常见,必须妥善处理。我们评估了十种常用的缺失值插补方法在高分辨率气相色谱-质谱仪上分析代谢物时的性能。通过将缺失值引入完整的(即无任何缺失值的)美国国家标准与技术研究院(NIST)血浆数据集,我们证明随机森林(RF)、广义线性模型套索回归(GRR)和贝叶斯主成分分析(BPCA)在技术重复数据中具有最低的均方根误差(RMSE)。对狒狒血浆和肝脏样本数据中这三种方法进一步研究表明,它们都保持了较高的准确性。总体而言,我们的分析表明,这三种插补方法中的任何一种都可以有效地高精度应用于非靶向代谢组学数据集。然而,需要注意的是,插补会改变数据集的相关结构,并使下游回归系数和p值产生偏差。