Li Shilong, Wang Zichen, Vieira Luciana A, Zheutlin Amanda B, Ru Boshu, Schadt Emilio, Wang Pei, Copperman Alan B, Stone Joanne L, Gross Susan J, Kao Yu-Han, Lau Yan Kwan, Dolan Siobhan M, Schadt Eric E, Li Li
Sema4, Stamford, CT, USA.
Department of Obstetrics, Gynecology, and Reproductive Science, Icahn School of Medicine at Mount Sinai, New York, NY, USA.
NPJ Digit Med. 2022 Jun 6;5(1):68. doi: 10.1038/s41746-022-00612-x.
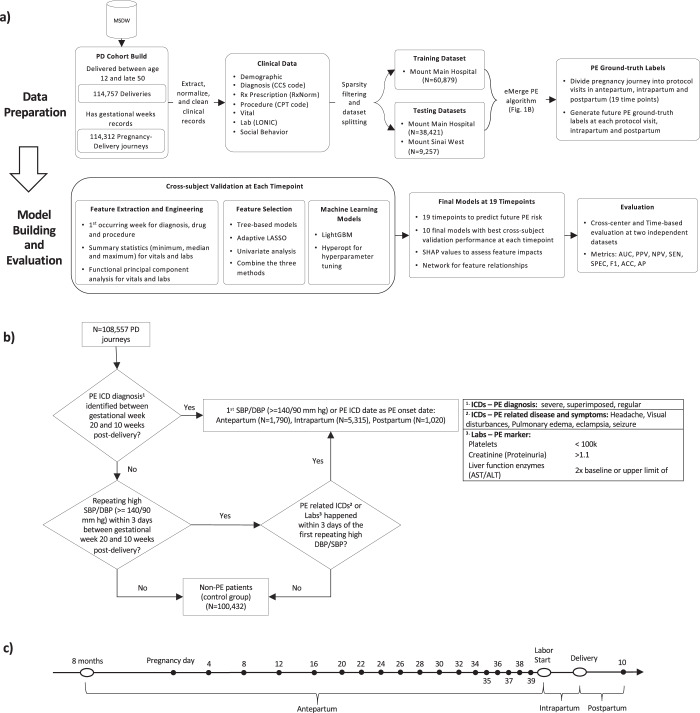
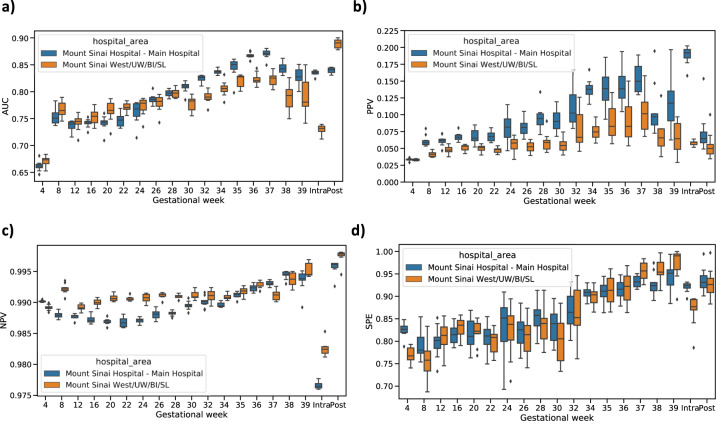
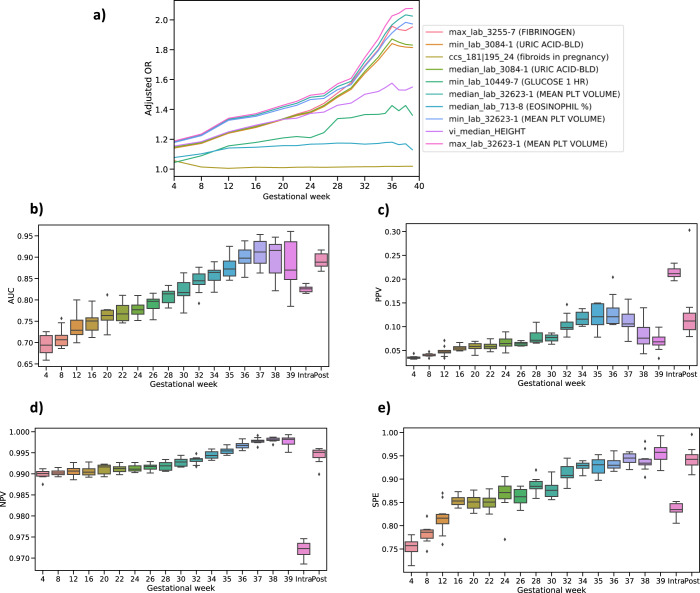
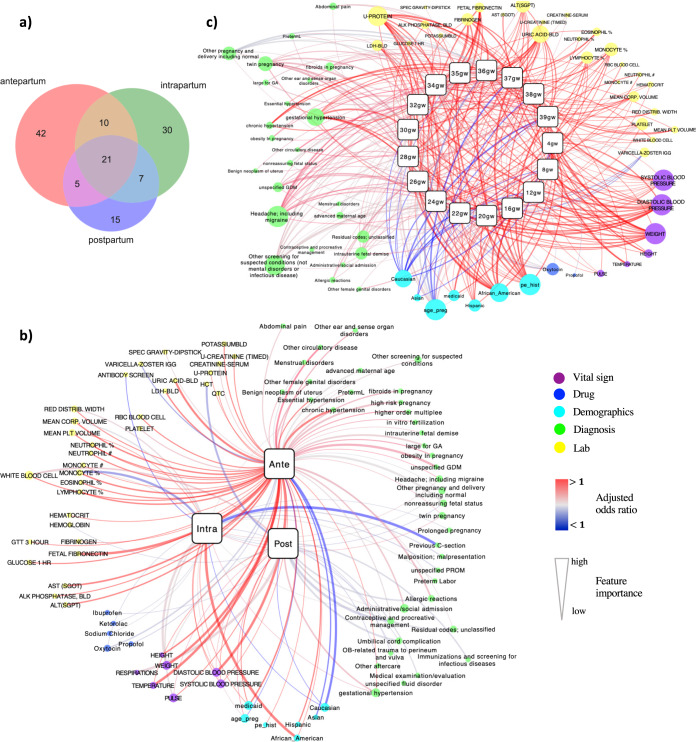
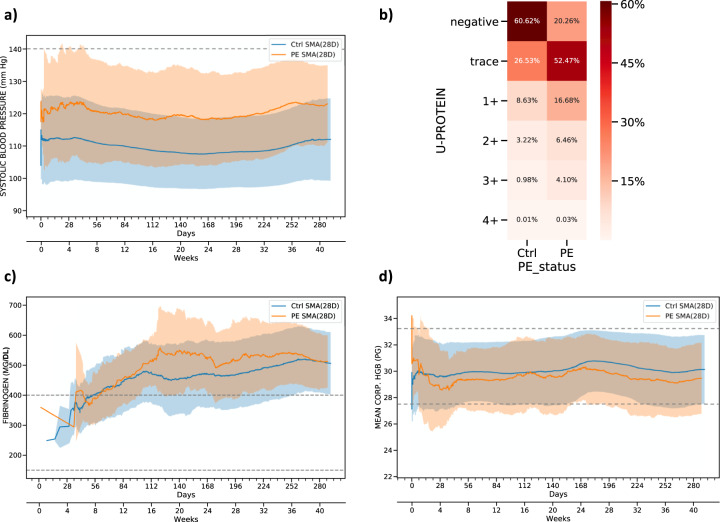
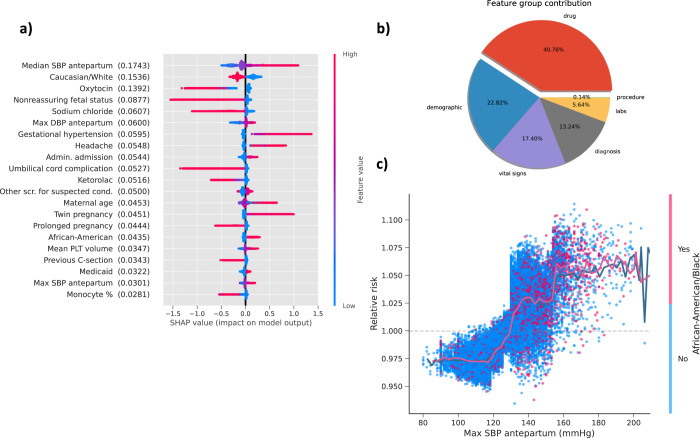
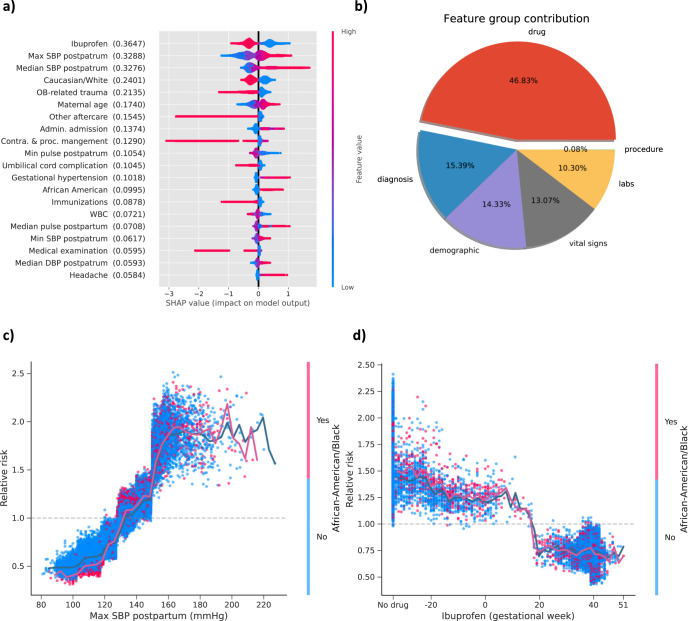
Preeclampsia is a heterogeneous and complex disease associated with rising morbidity and mortality in pregnant women and newborns in the US. Early recognition of patients at risk is a pressing clinical need to reduce the risk of adverse outcomes. We assessed whether information routinely collected in electronic medical records (EMR) could enhance the prediction of preeclampsia risk beyond what is achieved in standard of care assessments. We developed a digital phenotyping algorithm to curate 108,557 pregnancies from EMRs across the Mount Sinai Health System, accurately reconstructing pregnancy journeys and normalizing these journeys across different hospital EMR systems. We then applied machine learning approaches to a training dataset (N = 60,879) to construct predictive models of preeclampsia across three major pregnancy time periods (ante-, intra-, and postpartum). The resulting models predicted preeclampsia with high accuracy across the different pregnancy periods, with areas under the receiver operating characteristic curves (AUC) of 0.92, 0.82, and 0.89 at 37 gestational weeks, intrapartum and postpartum, respectively. We observed comparable performance in two independent patient cohorts. While our machine learning approach identified known risk factors of preeclampsia (such as blood pressure, weight, and maternal age), it also identified other potential risk factors, such as complete blood count related characteristics for the antepartum period. Our model not only has utility for earlier identification of patients at risk for preeclampsia, but given the prediction accuracy exceeds what is currently achieved in clinical practice, our model provides a path for promoting personalized precision therapeutic strategies for patients at risk.
子痫前期是一种异质性复杂疾病,在美国,它与孕妇及新生儿发病率和死亡率的上升相关。尽早识别有风险的患者是降低不良结局风险的迫切临床需求。我们评估了电子病历(EMR)中常规收集的信息是否能在标准护理评估之外增强对子痫前期风险的预测。我们开发了一种数字表型算法,从西奈山医疗系统的电子病历中筛选出108,557例妊娠,准确重建妊娠过程,并使这些过程在不同医院的电子病历系统中实现标准化。然后,我们将机器学习方法应用于一个训练数据集(N = 60,879),以构建三个主要妊娠时期(产前、产时和产后)子痫前期的预测模型。所得模型在不同妊娠时期对子痫前期的预测准确率很高,在孕37周、产时和产后的受试者工作特征曲线下面积(AUC)分别为0.92、0.82和0.89。我们在两个独立的患者队列中观察到了类似的表现。虽然我们的机器学习方法识别出了子痫前期的已知风险因素(如血压、体重和产妇年龄),但它也识别出了其他潜在风险因素,如产前全血细胞计数相关特征。我们的模型不仅有助于更早地识别子痫前期风险患者,而且鉴于预测准确率超过了目前临床实践中的水平,我们的模型为促进针对风险患者的个性化精准治疗策略提供了一条途径。